全文检索方案.docx
《全文检索方案.docx》由会员分享,可在线阅读,更多相关《全文检索方案.docx(11页珍藏版)》请在冰豆网上搜索。
全文检索方案
1全文检索系统方案
1.1全文检索系统总体方案
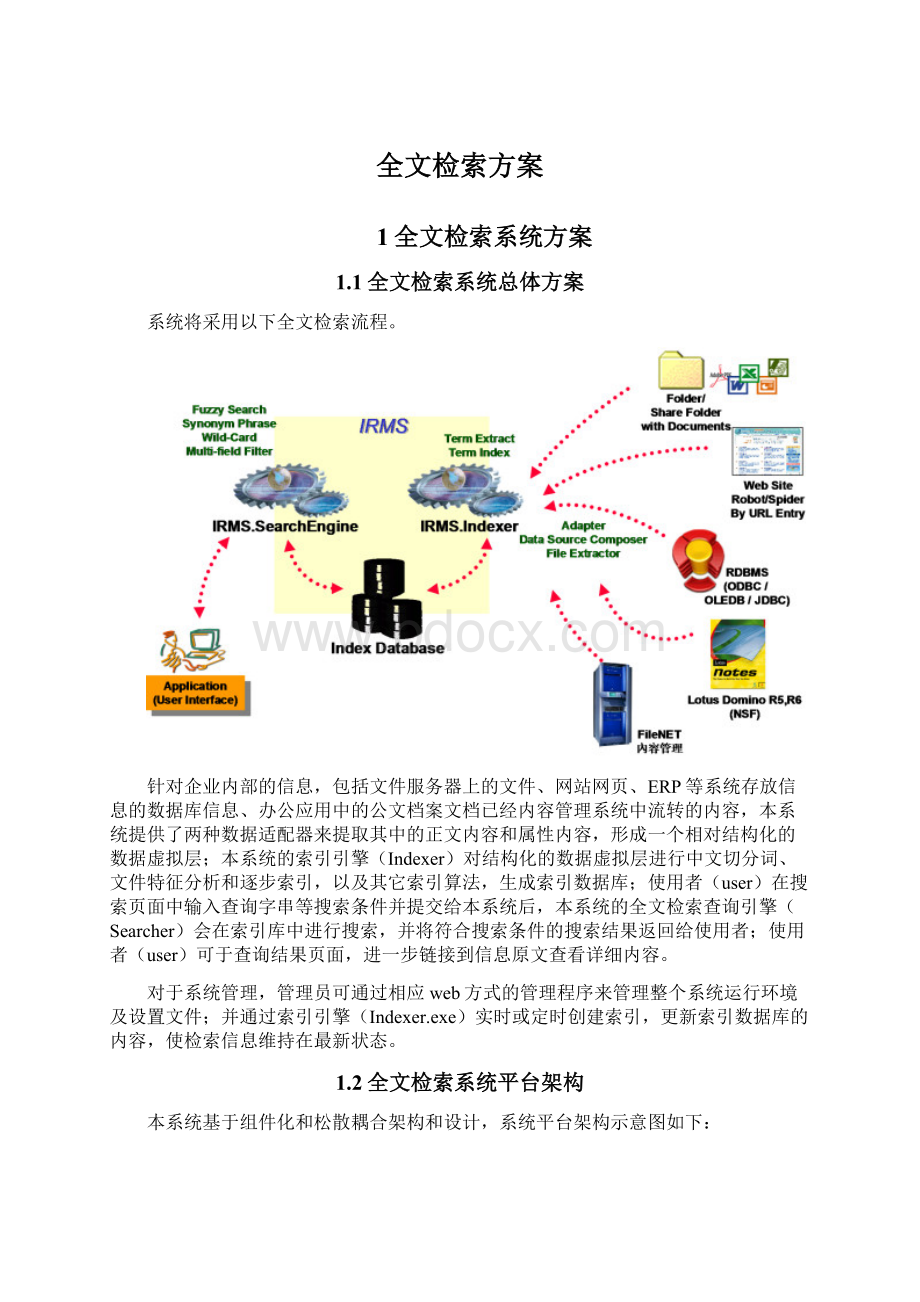
系统将采用以下全文检索流程。
针对企业内部的信息,包括文件服务器上的文件、网站网页、ERP等系统存放信息的数据库信息、办公应用中的公文档案文档已经内容管理系统中流转的内容,本系统提供了两种数据适配器来提取其中的正文内容和属性内容,形成一个相对结构化的数据虚拟层;本系统的索引引擎(Indexer)对结构化的数据虚拟层进行中文切分词、文件特征分析和逐步索引,以及其它索引算法,生成索引数据库;使用者(user)在搜索页面中输入查询字串等搜索条件并提交给本系统后,本系统的全文检索查询引擎(Searcher)会在索引库中进行搜索,并将符合搜索条件的搜索结果返回给使用者;使用者(user)可于查询结果页面,进一步链接到信息原文查看详细内容。
对于系统管理,管理员可通过相应web方式的管理程序来管理整个系统运行环境及设置文件;并通过索引引擎(Indexer.exe)实时或定时创建索引,更新索引数据库的内容,使检索信息维持在最新状态。
1.2全文检索系统平台架构
本系统基于组件化和松散耦合架构和设计,系统平台架构示意图如下:
整个系统主要分为信息整合、信息萃取和服务、应用整合三个部分。
✓信息整合
此部分主要作用是将企业内部存储于不同应用系统中的结构化信息、半结构化信息、非结构化信息通过本系统提供的两种数据适配器进行信息提取,形成一个相对结构化的数据虚拟层,以备后期信息萃取和服务。
✓信息萃取和服务
在信息整合层形成的相对结构化的数据虚拟层基础上,本系统将对其中的每笔记录进行中文切分词、索引、文件特征分析、自动分类等各种演算算法处理,形成可以提供搜索服务的索引库。
用户利用本系统的搜索引擎处理提供的强大的搜索功能,如中文同音搜索、简繁体对译、模糊搜索、同义词搜索、文章概念搜索、分类浏览等,快速、准确、完整、及时、有效地搜索到符合自己搜索条件的信息。
✓应用整合
本系统还提供了完整的外部程序整合机制。
所有组件均提供SDK完整开发接口,方便应用整合和应用扩展。
1.2.1信息整合
此部分主要提供对企业内外部非结构性数据信息源建立自动化数据汇入功能。
根据用户实际需求,用户可以选择导入包含Text、MicrosoftOffice、XML、RTF、PDF、HTML、MHT、AutoCAD及E-mail(含附件文件)等格式及文件影音附件(如影片的文件名或摘要、图片的文件名或摘要、及文字)自动化建立索引数据,建立索引数据所处理之文字包括繁体中文、简体中文等;
同时用户可以选择导入数据库数据,如Oracle、Informix、Sybase、MSSQL等。
此外和Notes系统也已经有了无缝整合,可挂载NotesComposer对nsf库中正文及附件信息索引,在做索引的过程中自动把每笔记录的权限键入索引库。
本系统提供可挂载的数据适配器(DataAdapter),将异质的数据来源与数据结构进行汇整与粹取,亦扮演将非结构的信息结构化,可以很容易地分析特殊档案格式和管理复杂的数据源结构(如递归、巢状等)的多功能设计,以方便信息检索与管理。
以e-mail含附件为例,e-mailAdapter可解析e-mail内文,而当选购officeAdapter后,原来的e-mailAdapter即可解析office相关的附件文件,可视需求额外购买PDF、ZIP、RAR、OCR等不同数据适配器,即可交互搭配使用。
搭配使用本系统的TXT、MicrosoftOffice、RTF、PDF、HTML、E-mail及FileMeta资料提取器,将可解析Text、MicrosoftOffice、XML、RTF、PDF、HTML、MHT及E-mail(含附件文件)及文件影音附档(如影片的文件名或摘要、图片的文件名或摘要、及文字)等格式,包括繁体中文、简体中文、英文、Unicode等;使用数据库数据适配器,将可支持数据库数据汇入处理如Oracle、Informix、Sybase、MSSQL等。
1.2.2信息萃取和服务
此部分须提供对数据提取的内容所包含的信息,进行数据处理分析,包含:
✓分类模式建立自动分类功能。
✓针对非结构性数据建立词库,词库须包含同音词库、同义词库、专业词库。
✓自动分类机制与专业词库须具备自动学习与修正之功能以提升数据处理准确度。
✓可针对不同使用层级、项目进行非结构性数据权限控管。
依照使用者不同等级提供不同权限的查询功能接口。
应用本系统一系列内容分析与索引核心组件群,将汇整的内容进行断词、索引、分类、文件特征等运算与处理,以便满足信息检索与信息管理的应用,提供多功能全面性的数据分析能力,可针对不同情境应用加以整合,快速达到使用者需求。
同时,用户利用本系统的搜索引擎处理提供的强大的搜索功能,如中文同音搜索、简繁体对译、模糊搜索、同义词搜索、文章概念搜索、分类浏览等,快速、准确、完整、及时、有效地搜索到符合自己搜索条件的信息。
1.2.3
应用整合
完整外部程序整合机制—所有组件均提供SDK完整开发接口,方便外部整合。
另外大量提供XML的方法来进行信息源更新时的同步以及权限的导入与检查工作。
1.3全文检索系统功能特点
1.3.1基本检索功能支持
✓支持跨数据源索引与整合搜索。
将分散在FileServer上的文件、远程网站中的网页、群组软件中的资料,以及数据库中的文字与非文字纪录,在一次搜寻条件下,整合搜寻出来。
可以对近线数据、在线数据和离线数据分别建立索引库,到时可以通过索引库的选择来控制对哪些性质的数据进行搜索;
✓支持「万用字符(*、?
)查询」。
使用者可查询部分关键字及*(代表多于一个字)或?
(代表一个字)的组合。
例如:
输入关键词【Chin*】,会找到【China】、【Chine】、【Chinese】等等。
输入关键词【Chin?
】,会找到【China】;
✓搜寻条件具有完整的布尔逻辑运算AND、OR、NOT能力,支持复合式布尔逻辑运算查询,并且可以配合多组左括号"("与右括号")"作关键词查询优先级的设定,方便查询者输入布尔组合之查询条件;
✓内建「智能型快速响应模式」(Smartcache)机制,可以提供同一种查询条件之重复使用率,提高系统资源的效益。
Cache储存目录记录了Cache档案所要放置的地址,经查询过的资料或画面,第二次再进入时,可重复使用第一次查询结果;
✓支持/多字段/多条件检索,提高搜索精确度;单一字段内,支持AND/OR/NOT逻辑条件,且支持括号方式来提供条件优先权。
多字段条件间,支持AND/OR/NOT逻辑条件;
1.3.2词索引与查询功能
系统中提供了传统的字索引,但是为提高查询检索的准确度,系统采用自然语言断词机制和灵活的词索引开关,用户可根据需要选择词索引或字索引。
具体功能如下:
Ø中文句子将透过智能型自动断词技术以达到词索引的效果,自动分析与断词,并建立词索引;
Ø词索引功能通过开关灵活设置;
Ø检索字串首先通过自动断词,将其断词结果进行组合检索;
Ø提供「词库」编辑器,针对断词用的「词库」进行维护和调整;使中文切分词更符合使用者的行业特点,提高查询的速度和准确度。
该功能优势如下:
✓提高精确度:
输入「民法」不会找到「人民法院」;
✓更小的索引空间:
–通过词索引的方式,索引数据库相对字索引需要更少的磁盘空间;同样数据量下,检索时需要的Memory更少;
✓检索性能更高:
配合高效算法,词索引的搜索性能相对字索引平均高出3倍以上;
1.3.3多国语系数据索引与查询
✓系统基于Unicode设计。
✓可支持多国语系(英文、繁简体中文、日文、韩文、Unicode等)混合的文件的建置与查询。
✓可支持多种编码格式的索引,包含Big5、GB2312、Unicode、UTF-8、EUC-JP、Shift-JIS,并支持以Unicode同时输入多国语系条件进行搜寻。
✓
同个数据表或一条数据库记录中可以支持多国语言混排内容;
✓一个索引数据库可以存在多国语言的不同数据;
✓可以输入多国语言的检索条件,并使用AND、OR、NOT逻辑关系;
✓检索结果中可以同时显示多国语言记录;
✓搭配多国语言同义词库,可以通过单一语言条件,得到多国语言检索结果;
1.3.4中英文模糊搜索查询功能
✓内建「中英文容错(Fuzzy)」查询功能。
✓中英文容错功能FuzzySearch,基于文字特性,很多专有名词及词汇依情况不同,也许衍生出通用的简称,或是文字次序对调。
也有可能因为模糊不明确的意象,使用者希望只需要输入一个关键词,就能一并查询性质类似或相关之信息。
比如:
输入「MobileNetwork」可查到「MobileApplianceNetwork」等特定距离的词句、输入「产业研究」可查到「产业结构研究」、「产业….研究」等,扩展搜寻的完整性。
1.3.5近似概念词库辅助查询功能
✓可针对不同的索引库设定同义词组。
如设定「电脑$Computer$计算机」为同义词,则使用者可搜索“电脑”时,可同时查到含有“Computer”或“计算机”的信息。
✓内建18万多组中英文同义词组,具有中英文近似概念与同义词检索,并可提供词库管理工具,使用户可自行修改词库内容。
1.3.6其他检索功能
✓中文同音辅助查询功能,如输入“网骆”,启动中文同音功能后,可以搜索出以“网络”为关键字的记录;
✓英文字根(Stemming)辅助查询功能,输入“computing”,可以搜索出以“computer”为关键字的记录;
✓英文错误字提示功能;
✓简繁对译组件功能,输入“中国”,可以搜索出以繁体字“中国”为关键字的记录;
1.3.7搜索结果显示
✓以Web网页形式呈现查询结果,使用者可指定所欲察看的特定笔数或分页浏览。
支持二次搜索功能。
✓提供「属性字段权重排序机制」,管理者可自订查询结果的排序规则,让搜寻结果按搜索者的意图显示。
✓提供「树形分类目录」,提供查询结果分类,可以让使用者进一步选取下一层目录,以缩小查询范围。
✓具有标示原文关键词功能,可以直接将原文中有关使用者输入得关键词全数标示出来,同时系统管理者可以自行设定关键词标示的颜色、大小、字型….等属性。
✓查询结果可同时显示文件抬头及重要摘要段落或者仅仅显示文件抬头以加快使用者的查询速度。
✓开发搜索接口,用户可根据开发的SDK自己开发特定形式和显示风格的搜索结果页面。
1.3.8自然语言应用组件
利用自然语言的形似相关词功能,可对数据撷取内容进行新词学习,语意分析等,可自动建立新词,提升数据处理准确度。
基于自然语言应用组件,可实现相关文章查询功能、重复文章查询功能、自动摘要功能、语意查询功能、形似相关词建议功能等。
从而能够通过关联组织的方式,把不同档案库中的相似、相关内容一次性的搜索出来。
✓相关文件查询
✓文章自动摘要
1.3.9自动分类应用组件
搭配自动分类组件,可对撷取数据进行分类,并可辅以导览式分类组件与搜寻组件进行整合,即可逐一依类别筛检过滤资料,并显示类别内符合资料。
✓导览式分类
✓自动分类
1.3.10高效数据同步功能(增量索引)
以前的全文搜索引擎在面对大资料量建立索引时,都会限制数据量的多少,而解决这个问题通常都是将资料量分为几个部分分开建索引。
但是这种方法并无法彻底解决资料同步更新或检索的需求。
本系统提供渐进式索引技术,也就是通过增量索引机制可以逐步地分别为数据库建立索引,对于异动的数据或索引,进行实时的更新。
1.3.11高可用性
本全文检索服务可以通过Layer4Switch硬件进行搜寻的负载均衡,提高服务效能。
若某台主机因不明原因无法对外服务,则可实时以另一台主机对外进行正常服务。
索引库可存放于网络存储设备上,让备用机共享其索引数据,使全文检索服务可以正常运行。
1.3.12可扩充性:
本系统可依不同需求扩张,分类,自然语言,数据适配器等组件,更可置换其关键性应用组件,例如:
企业已使用其它分类组件,透过本系统提供之SDK,可取代原本之分类应用组件,且不会影响原本服务机制。
 升级会员
升级会员 