SPSS实验报告二.docx
《SPSS实验报告二.docx》由会员分享,可在线阅读,更多相关《SPSS实验报告二.docx(14页珍藏版)》请在冰豆网上搜索。
SPSS实验报告二
SPSS实验报告二
实验目的:
掌握方差分析、相关分析和回归分析的基本操作;掌握其中相关的问题检验;读懂输出结果并进行合理分析。
第一题:
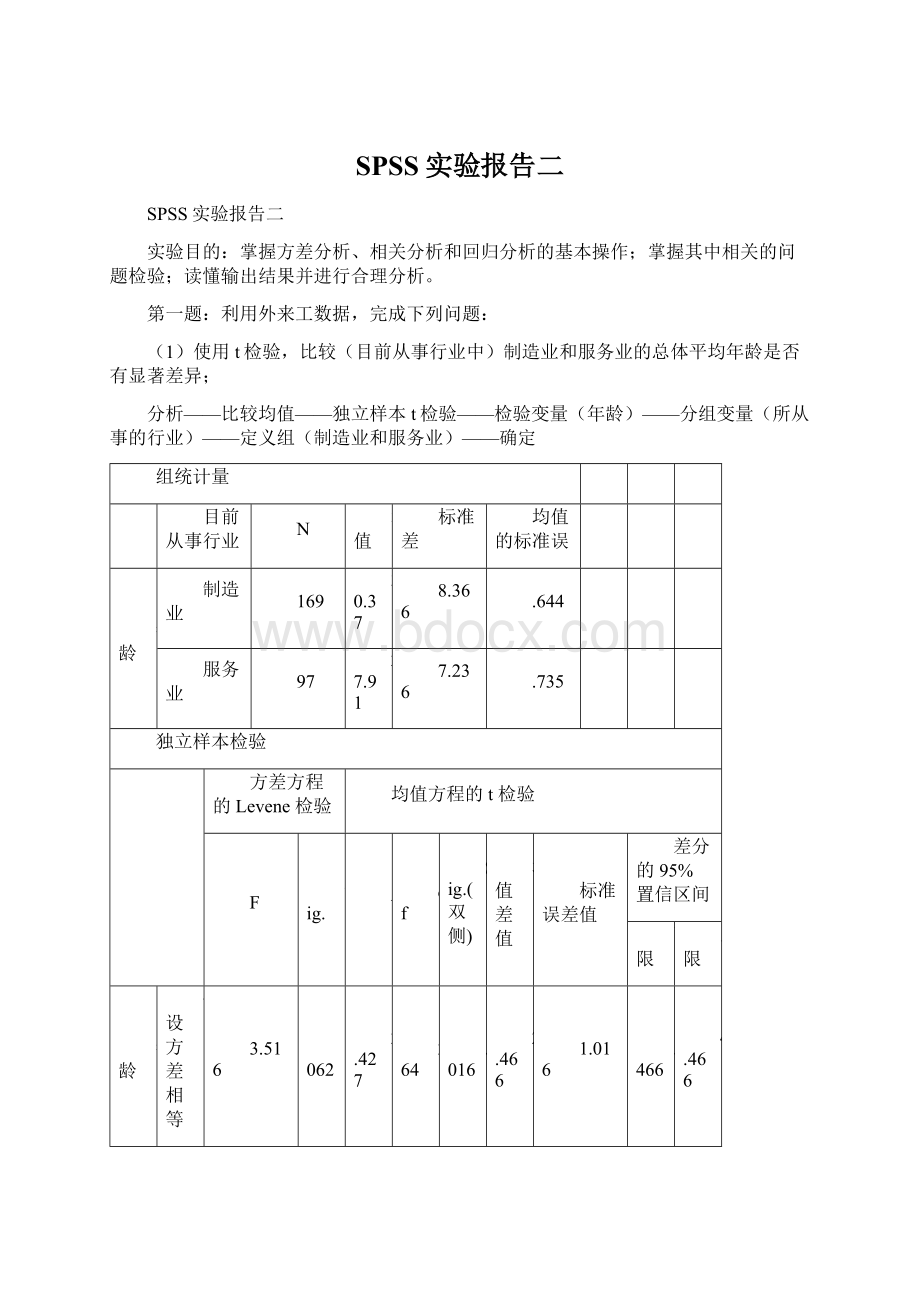
利用外来工数据,完成下列问题:
(1)使用t检验,比较(目前从事行业中)制造业和服务业的总体平均年龄是否有显著差异;
分析——比较均值——独立样本t检验——检验变量(年龄)——分组变量(所从事的行业)——定义组(制造业和服务业)——确定
组统计量
目前从事行业
N
均值
标准差
均值的标准误
年龄
制造业
169
30.37
8.366
.644
服务业
97
27.91
7.236
.735
独立样本检验
方差方程的Levene检验
均值方程的t检验
F
Sig.
t
df
Sig.(双侧)
均值差值
标准误差值
差分的95%置信区间
下限
上限
年龄
假设方差相等
3.516
.062
2.427
264
.016
2.466
1.016
.466
4.466
假设方差不相等
2.524
224.367
.012
2.466
.977
.541
4.390
P<0.05拒绝原假设,认为(目前从事行业中)制造业和服务业的总体平均年龄有显著差异。
(2)使用多因素方差分析研究教育程度和月收入对家庭花费(V2_2c),说明两个因素的影响是否显著,有没有显著的交互作用;
分析——一般线性模型——单变量——因变量(选择家庭花费V2-2c)——固定因子(选择教育程度月收入)——确定
主体间效应的检验
因变量:
家庭花费(已婚)
源
III型平方和
df
均方
F
Sig.
校正模型
193602261.170a
13
14892481.628
14.832
.000
截距
466960425.320
1
466960425.320
465.061
.000
V1_3
12124741.618
2
6062370.809
6.038
.003
V2_1
61115389.230
4
15278847.308
15.217
.000
V1_3*V2_1
3027942.331
7
432563.190
.431
.882
误差
244996451.361
244
1004083.817
总计
1608433153.000
258
校正的总计
438598712.531
257
a.R方=.441(调整R方=.412)
从上表P值可看到教育程度和月收入两因素影响显著而它们的交互作用(P=0.882>0.05)不显著。
(3)如果因素影响显著而交互作用不显著,建立非饱和模型,并利用多重比较比较(snk)各因素水平的高低;
分析——一般线性模型——单变量——因变量(选择家庭花费V2-2c)——固定因子(选择教育程度月收入)
——模型(设定选择V1-3V2-1到模型M框)——继续
——绘制——水平轴(V2-1)——单图(V1-3)——添加——继续
——两两比较(将V1-3V2-1指向两两比较检验框P)——勾选s-n-k
——保存——勾选预测值(未标准化)——残差(标准化)——诊断(Cook距离)——继续
——选项——勾选(描述统计方差齐性检验)——继续——确定
主体间效应的检验
因变量:
家庭花费(已婚)
源
III型平方和
df
均方
F
Sig.
校正模型
190574318.839a
6
31762386.473
32.143
.000
截距
502244370.157
1
502244370.157
508.270
.000
V1_3
12486468.828
2
6243234.414
6.318
.002
V2_1
115006246.078
4
28751561.520
29.097
.000
误差
248024393.692
251
988144.995
总计
1608433153.000
258
校正的总计
438598712.531
257
a.R方=.435(调整R方=.421)
家庭花费(已婚)
Student-Newman-Keuls
教育程度
N
子集
1
2
3
初中及以下
54
1528.30
中专或高中
145
1969.88
大学及以上
59
3071.51
Sig.
1.000
1.000
1.000
已显示同类子集中的组均值。
基于观测到的均值。
误差项为均值方(错误)=988144.995。
a.使用调和均值样本大小=70.814。
b.组大小不相等。
将使用组大小的调和均值。
不保证I型误差级别。
c.Alpha=0.05。
家庭花费(已婚)
Student-Newman-Keuls
月收入
N
子集
1
2
3
800元以下
7
1232.14
801-1200
69
1421.42
1201-2000
87
1776.54
2001-3000
51
2362.33
3000元以上
44
3809.95
Sig.
.145
1.000
1.000
已显示同类子集中的组均值。
基于观测到的均值。
误差项为均值方(错误)=988144.995。
a.使用调和均值样本大小=23.677。
b.组大小不相等。
将使用组大小的调和均值。
不保证I型误差级别。
c.Alpha=0.05。
从家庭花费和教育程度来看,大学及以上学历的群体比初高中及中专学历的群体家庭花费要多出很多。
因此,可得出教育程度越高,家庭花费越多。
而从家庭花费和月收入来看,800元以下及801到2000元收入的群体家庭花费并不会随着收入的增加而有很大的增幅;但2001到3000元及3000元以上的收入群体的家庭花费会随之增幅很大。
因此,大体可得出收入越高的群体家庭花费越多。
第二题:
应用waste.sav数据,研究固体垃圾排放量与宾馆、餐饮业用地、零售业用地、运输、批发企业用地、金属制造业用地、工业企业用地的关系。
(1)、通过散点图观察变量间的相关关系,使用Enter建立模型,判断各自变量间是否存在多重共线性,写出回归方程,说明T检验和F检验的结果
图形——旧对话框——矩阵分布——选择简单点——定义
——X轴变量(固体垃圾排放)——行(宾馆、餐饮业用地、零售业用地、运输、批发企业用地、金属制造业用地、工业企业用地)
分析——回归——线性——因变量(固体垃圾~)——自变量(宾馆、餐饮业用地、零售业用地、运输、批发企业用地、金属制造业用地、工业企业用地)
——方法(进入)——确定
模型汇总
模型
R
R方
调整R方
标准估计的误差
1
.921a
.849
.827
.15046
a.预测变量:
(常量),宾馆、餐饮业用地,金属制造业用地,工业企业用地,运输、批发企业用地,零售业用地。
Anovaa
模型
平方和
df
均方
F
Sig.
1
回归
4.326
5
.865
38.214
.000b
残差
.770
34
.023
总计
5.095
39
a.因变量:
固体垃圾排放量
b.预测变量:
(常量),宾馆、餐饮业用地,金属制造业用地,工业企业用地,运输、批发企业用地,零售业用地。
系数a
模型
非标准化系数
标准系数
t
Sig.
B
标准误差
试用版
(常量)
1.21585
.032
3.838
.001
工业企业用地(X1)
-5.249E-005
.000
-.232
-2.930
.006
金属制造业用地(X2)
4.345E-005
.000
.045
.283
.779
运输、批发企业用地(X3)
2.5E-004
.000
.491
2.827
.008
零售业用地(X4)
-8.6E-004
.000
-.439
-2.284
.029
宾馆、餐饮业用地(X5)
1.3355E-002
.002
1.083
5.853
.000
a.因变量:
固体垃圾排放量
共线性诊断a
模型
维数
特征值
条件索引
方差比例
(常量)
工业企业用地
金属制造业用地
运输、批发企业用地
零售业用地
宾馆、餐饮业用地
1
1
3.606
1.000
.02
.02
.01
.01
.00
.00
2
1.111
1.801
.05
.07
.04
.02
.01
.01
3
.660
2.338
.07
.63
.02
.02
.01
.00
4
.510
2.660
.74
.12
.01
.00
.02
.01
5
.072
7.080
.05
.00
.92
.90
.00
.03
6
.042
9.310
.07
.16
.00
.05
.96
.93
a.因变量:
固体垃圾排放量
通过F检验,其P值小于显著性水平0.05,所以认为它们之间有显著的线性关系,可以构建回归模型。
通过T检验,我们可以得知,除了金属制造业用地的P值大于显著性水平0.05外,即接受原假设,金属制造业用地和固体垃圾排放量没有显著的关系外,其他的四个的P值都小于显著性水平0.05和固体垃圾排放量有显著的关系,工业企业用地和零售业用地和固体垃圾排放量有负相关的关系;而运输、批发企业用地和宾馆、餐饮业用地与固体垃圾排放量有正相关的关系。
运输、批发企业用地和宾馆、餐饮业用地、工业企业用地和零售业用地、金属制造业用地的VTF都没有大于10,故它们之间没有多重共线性关系。
其回归方程为:
y=-0.122-5.249E-005*x1+4.345E-005*x2+0.00025*x3-0.001*x4+0.013*x5
(2)、利用Stepwise建立模型,通过计算D-W统计量和作出残差分布图、pp图等方法初步判断是否存在序列相关、异方差和正态性,保存模型的预测值。
选做:
以库克距离大于1去除异常点后再做第二个问,对比回归结果。
分析——回归——线性——因变量(固体垃圾~)——自变量(宾馆、餐饮业用地、零售业用地、运输、批发企业用地、金属制造业用地、工业企业用地)
——方法(进入)
——勾选统计量(D-W)——继续
——绘制——Y(ZRESID)——X2(ZPRED)——勾选(直方图正态概念图)—继续
——保存——勾选(为标准化预测未标准化残差Cook距离)——继续
——选项——默认(不需作任何修改)——确定
残差统计量a
极小值
极大值
均值
标准偏差
N
预测值
.1284
1.7014
.3801
.33297
40
标准预测值
-.756
3.968
.000
1.000
40
预测值的标准误差
.025
.142
.043
.031
40
调整的预测值
-.9708
2.1276
.3650
.44695
40
残差
-.31253
.26904
.00000
.14065
40
标准残差
-2.105
1.812
.000
.947
40
Student化残差
-3.278
2.900
.032
1.261
40
已删除的残差
-1.35175
1.24074
.01516
.35600
40
Student化已删除的残差
-3.881
3.279
.037
1.365
40
Mahal。
距离
.122
34.464
3.900
8.588
40
Cook的距离
.000
14.429
.813
3.014
40
居中杠杆值
.003
.884
.100
.220
40
a.因变量:
固体垃圾排放量
模型汇总b
模型
R
R方
调整R方
标准估计的误差
Durbin-Watson
1
.921a
.849
.827
.15046
1.694
a.预测变量:
(常量),宾馆、餐饮业用地,金属制造业用地,工业企业用地,运输、批发企业用地,零售业用地。
b.因变量:
固体垃圾排放量
D-W统计量为1.694,在1.5~2.5之间,认为无明显的序列相关。
通过P-P图可以看到数据点围绕基准线还存在一定的规律,表明标准化残差与标准正态分布不存在显著差异。
通过散点图可分析,随着标准化预测值的变化,残差点在0线周围随机分布,但残差随着标准化预测值变化的趋势并不明显,因此异方差现象并不明显。
第三题:
完成P283,例题9-3,画出外出就餐和年份的散点图,利用复合函数,指数函数和三次函数行拟合,选择最好的拟合模型,写出曲线方程,并对之后两年年的数据进行预测。
图形——旧对话框——散点点状——简单分布——定义——Y轴(在外就餐)——X轴(年份)
在数据视图添加年份(输入20032004)
分析——回归——曲线估计——因变量(在外就餐)——变量(年份)
—勾选(在等式包含常量根据模型绘图线性复合立方指数分布)—确定
指数函数和复合函数的拟合效果最好。
复合函数的曲线方程为:
y=1.031E-131*1.166**X
指数函数的曲线方程:
y=1.031E-131*e**(0.154X)
而预测后两年的数据分别为683.49853和797.16461
.
 升级会员
升级会员 