数据结构复习提要.docx
《数据结构复习提要.docx》由会员分享,可在线阅读,更多相关《数据结构复习提要.docx(22页珍藏版)》请在冰豆网上搜索。
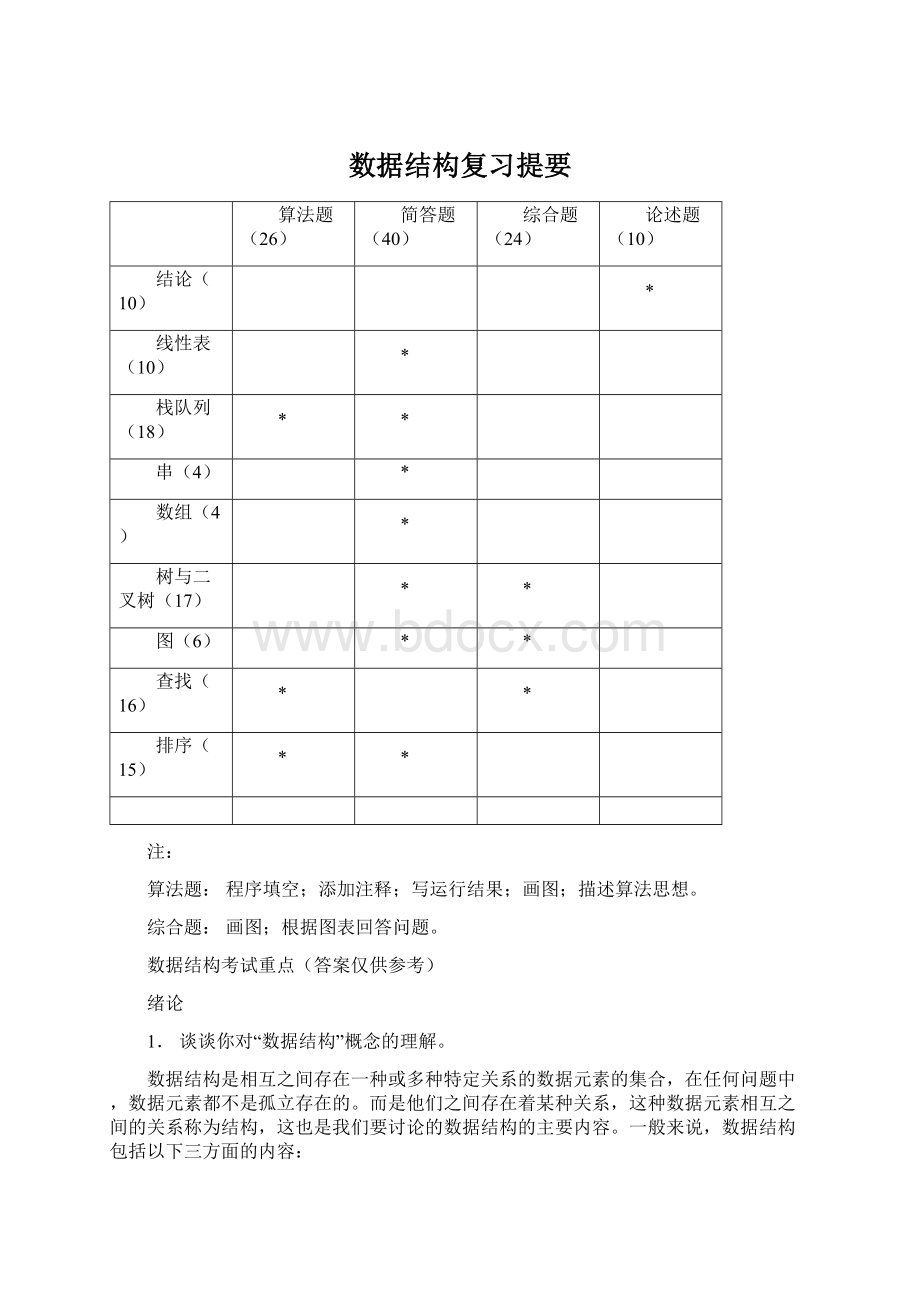
数据结构复习提要
算法题(26)
简答题(40)
综合题(24)
论述题(10)
结论(10)
*
线性表(10)
*
栈队列(18)
*
*
串(4)
*
数组(4)
*
树与二叉树(17)
*
*
图(6)
*
*
查找(16)
*
*
排序(15)
*
*
注:
算法题:
程序填空;添加注释;写运行结果;画图;描述算法思想。
综合题:
画图;根据图表回答问题。
数据结构考试重点(答案仅供参考)
绪论
1.谈谈你对“数据结构”概念的理解。
数据结构是相互之间存在一种或多种特定关系的数据元素的集合,在任何问题中,数据元素都不是孤立存在的。
而是他们之间存在着某种关系,这种数据元素相互之间的关系称为结构,这也是我们要讨论的数据结构的主要内容。
一般来说,数据结构包括以下三方面的内容:
(1)数据元素之间的逻辑关系,也称数据的逻辑结构。
数据的逻辑结构是抽象的,它不依赖计算机的实现,只依赖人们对事物的理解和描述。
(2)数据元素及其关系,在计算机内部(内存)中的表示,称其为数据的物理结构或数据的存储结构。
(3)数据的运算及实现,即对数据元素可以施加的操作及这些操作在相应的存储结构上的具体实现。
2.谈谈你对“抽象数据类型(ADT)”的理解。
抽象数据类型(AbstractDataType简称ADT)是指一个数学模型以及定义在此数学模型上的一组操作。
抽象数据类型需要通过固有数据类型(高级编程语言中已实现的数据类型)来实现。
抽象数据类型是与表示无关的数据类型,是一个数据模型及定义在该模型上的一组运算。
对一个抽象数据类型进行定义时,必须给出它的名字及各运算的运算符名,即函数名,并且规定这些函数的参数性质。
一旦定义了一个抽象数据类型及具体实现,程序设计中就可以像使用基本数据类型那样,十分方便地使用抽象数据类型。
线性表
3.顺序表的动态内存分配的好处是什么?
(1)长度能动态增长;根据实际需要分配所需内存大小,合理利用资源
(2)不需要预先分配存储空间;
(3)存储效率高,紧凑结构;
4.单链表中引入“头结点”的好处是什么?
什么情况下单链表需要使用“尾指针”?
(1)由于开始结点的位置存放在头结点的指针域中,所以对链表第一个位置的操作同其他位置一样,无须特殊处理。
(2)只有“头指针”时,访问“头”方便,而访问“尾”不方便。
有时候,根据需要,一个单向循环链表只设置尾指针,而不设置头指针。
此时访问“头”和“尾”都很方便。
5.在主调函数中构建了一个“不带头结点”的单链表L1(即该链表已完成初始化,甚至链表已不空),在子函数中对该单链表进行插入/删除操作。
说明在参数传递时,使用“引用”与不使用“引用”的区别。
6.在主调函数中声明了一个单链表L1,在子函数InitLink()中对该单链表初始化为一个“带头结点”的单链表。
在“不使用引用型参数”的情况下,
1)写出初始化函数。
typedefintdata;
typedefstructLNode{
datad;
StructLNode*next;
}LNode,*LinkList;
LinkListinitialize(void)
{LinkListL;
L=(LinkList)malloc(sizeof(LNode);L->next=NULL;returnL;
}
2)写出调用该函数的语句。
Voidmain()
{LinkListL1;
L1=initialize();
.
.
.
return0;
}
栈队列
7.对“链栈”,哪一端是“栈顶”?
为什么?
链头作为栈顶
原因:
链栈是运算受限的单链表,其插入和删除操作仅限制在表头位置上操作,因此将链头作为栈顶方便操作。
8.链栈中还要不要“头结点”?
为什么?
不要。
原因:
链栈是运算受限的单链表,其插入和删除的操作仅在链表头位置上进行。
如果加了头结点,等于要对头结点之后的结点进行操作,反而使算法更复杂。
9.顺序栈采用动态内存分配,数据结构定义如下:
typedefstructsStack{
DataType*base;
DataType*top;
intstacksize;//最大容量
}SqStack;
1)如何求栈高?
IntstackHeight(SqStacksq)
{returnsq.top-sq.base;
}
2)能否将top定义成int类型?
可以
10.链队列的“队头”与其它链式结构(如链栈或者单链表)有什么不同?
11.为什么引入“循环队列”?
写出循环队列判队满,判队空以及求队长的表达式。
原因:
为充分利用向量空间,克服"假溢出"现象
方法:
1)设置一个队长变量
2)牺牲一个元素空间
队空:
Q.front=Q.rear;
队满:
(Q.rear+1)%maxsize=Q.front
队长(Q.rear-Q.front+MAXSIZE)%MAXSIZE
知识:
12.对于一般的顺序存储结构,若采用“动态内存分配”,当插入元素而空间不足时,可以动态增加内存分配。
而对于循环队列,能否这样做?
为什么?
不能
(1)循环队列是将顺序队列臆造成一个环状空间,当插入元素而空间不足时,动态增长内存分配会破坏循环队列的结构。
(2)循环队列队满的标志为(Q.rear+1)%maxsize==Q.front。
要插入元素,只能让对头元素出队。
能力:
13.定义一个长度为k的循环队列,有一个字符串S(长度>k),编写程序完成进队出队。
调试完毕后,将完整代码写在实验报告册上。
特别强调:
将关键代码加注释,注释行数不少于总代码行的2/3。
#include"stdio.h"
#include"stdlib.h"
#defineMAXSIZE10;//最大队列长度
typedefcharDataType;
typedefstruct{
DataType*base;//初始化的动态分配存储空间
intfront,rear;//头,尾指针,若队列不空,指队头元素、队列尾元素的下一个位置
}SqQueue;
//-------------------实现-----------
voidInitQueue(SqQueue&Q)//初始化队列
{
Q.base=(DataType*)malloc(MAXSIZE*sizeof(DataType));
Q.front=Q.rear=0;
}
boolisQEmpty(SqQueueQ)//判队空
{
if(Q.front==Q.rear)
returntrue;
else
returnfalse;
}
boolisQFull(SqQueueQ)//判队满
{
if((Q.rear+1)%MAXSIZE==Q.front)
returntrue;
else
returnfalse;
}
voidEnQueue(SqQueue&Q,DataType&e)//向队列中添加元素
{
Q.base[Q.rear]=e;
Q.rear=(Q.rear+1)%MAXSIZE;
}
voidOutQueue(SqQueue&Q,DataType&e)//出队
{
e=Q.base[Q.front];
Q.front=(Q.front+1)%MAXSIZE;
}
//-------------------实现完毕-----------
voidmain()//调用函数
{
SqQueueQ1;
InitQueue(Q1);
charc1,c2;
cout<<"请读入符号串,以#号结束:
"<cin>>c1;
while(c1!
='#')
{
if(!
isQFull(Q1))
{
EnQueue(Q1,c1);
cin>>c1;
}
else
{
OutQueue(Q1,c2);
cout<}
}
while(!
isQEmpty(Q1))
{
OutQueue(Q1,c2);
cout<}
cout<}
*/
串
14.能力:
在第1章绪论中,曾经写了一个描述“串”的ADT,并给出了其表示与实现,以及一个完整的程序。
要求:
给该程序关键代码加注释,注释行数不少于总代码行的2/3。
#include"iostream.h"
#include"malloc.h"
typedefstructstr{
char*ch;
intlength;
}HString;
//----------------基本操作算法描述---------------
boolStrAssign(HString&T,char*chars)//将chars串赋给T
{
inti;char*c;
if(T.ch)
free(T.ch);//这行代码有问题,思考?
for(i=0,c=chars;*c;i++,c++)//求chars串的长度
;
if(!
i){
T.ch=NULL;T.length=0;}//建立一个空串
else{
T.ch=(char*)malloc(i*sizeof(char));//注意:
这里没有检测是否内存分配成功,其实是应该做的
for(intj=0;jT.ch[j]=chars[j];//注意:
T串的末尾没有添加'\0'
T.length=i;
}
returntrue;//赋值成功
}
intStrLength(HStringS)//求串长
{
returnS.length;
}
intStrCompare(HStringS,HStringT)//串大小的比较
{
inti;
for(i=0;iif(S.ch[i]!
=T.ch[i])
returnS.ch[i]-T.ch[i];
returnS.length-T.length;//请理解这一行的意思
}
boolSubString(HString&Sub,HStringS,intpos,intlen)//求子串
{
if(pos<1||pos>S.length||len<0||len>S.length-pos+1)
returnfalse;
if(Sub.ch)
free(Sub.ch);//这行代码有问题,思考?
if(!
len){Sub.ch=NULL;Sub.length=0;}
else{
Sub.ch=(char*)malloc(len*sizeof(char));//注意:
这里没有检测是否内存分配成功,其实是应该做的
for(intj=0,k=pos-1;jSub.ch[j]=S.ch[k];
Sub.length=len;
}
returntrue;
}
intIndex(HStringS,HStringT,intpos)//子串定位
{
intn,m,i;
HStringsub;
sub.ch=NULL;
sub.length=0;
if(pos>0){
n=StrLength(S);m=StrLength(T);i=pos;
while(i<=n-m+1)
{SubString(sub,S,i,m);
if(StrCompare(sub,T)!
=0)
i++;
elsereturni;//返回子串的位置
}
}
return0;//不存在子串
}
voidmain()
{
HStringS,T,sub;
intpos;
intm,n,i;
S.ch=NULL;//初始化。
其实最好将初始化过程做成一个基本操作
S.length=0;
T.ch=NULL;//初始化。
其实最好将初始化过程做成一个基本操作
T.length=0;
StrAssign(S,"xabcdc");//注意:
strS1.ch的末尾没有'\0'
StrAssign(T,"ab");//注意:
strS1.ch的末尾没有'\0'
cin>>pos;
cout<}
数组
知识:
15.二维数组A[8][9]按行优先顺序存储,若数组元素A[2][3]的存储地址为1087,A[4][7]的存储地址为1153,则数组元素A[6][7]的存储地址是多少?
A[4][7]和A[2][3]相差22个元素[(4×9+7)-(2×9+3)=22]
1153-1087=66即一个数组元素占3个字节
A[6][7]和A[4][7]相差18个元素[(6×9+7)-(4×9+7)]=18
则A[6][7]存储地址为1153+18×3=1207
16、三角矩阵和对称矩阵在进行压缩存储时有什么不同?
三角矩阵是指上(下)三角矩阵的下(上)三角(不包括对角线)中的元素均为常数C或0,所以在压缩存储时只存储上(下)三角中的元素,并加一个存储常数C的存储空间。
对称矩阵进行压缩存储时是每一对称无分配一个存储空间,将n的平方个元压缩存储在n(n+1)/2个元的空间中。
树和二叉树:
知识:
17、对于二叉树,什么情况下选用“顺序存储”较好?
稠密的树
18、先序序列为:
ABCDEFG,中序序列为:
CBAEFGD,画出该二叉树,及二叉链表。
19、实现二叉链表的层序遍历,需要借助于什么数据结构?
为什么?
层序遍历需要借助于“队列”完成,对二叉树遍历,除了按先序、中序、后序遍历外,还可以按“层序”遍历。
先一层的遍历完须保存下来。
20、结点权值分别是:
0.05,0.29,0.07,0.08,0.14,0.23,0.03,0.11,构造最优二叉树。
例如:
1,2,3,4,5,6,7,8,9,10
1、先在序列里找权值两个最小的根结点。
选1,2组成一棵二叉数。
然后,把1,2去掉。
用根结点的权值3加入原序列。
3,3,4,5,6,7,8,9,10
2、在新的序列中找权值两个最小的根结点.选3,3组成一棵二叉数。
然后,把3.3去掉。
用根结点的权值6加入原序列,升序排列。
4,5,6,6,7,8,9,10
3、在新的序列中找权值两个最小的根结点.选4,5组成一棵二叉数。
然后,把4,5去掉。
用根结点的权值9加入原序列。
升序排列。
6,6,7,8,9,9,10
4、在新的序列中找权值两个最小的根结点.选6,6组成一棵二叉数。
然后,把6,6去掉。
用根结点的权值12加入原序列。
升序排列。
7,8,9,9,10,12
5、在新的序列中找权值两个最小的根结点.选7,8组成一棵二叉数。
然后,把7,8去掉。
用根结点的权值15加入原序列。
升序排列。
9,9,10,12,15
6、在新的序列中找权值两个最小的根结点.选9,9组成一棵二叉数。
然后,把9,9去掉。
用根结点的权值18加入原序列。
升序排列。
10,12,15,18
7、在新的序列中找权值两个最小的根结点.选10,12组成一棵二叉数。
然后,把10,12去掉。
用根结点的权值22加入原序列。
升序排列。
15,18,22
8、在新的序列中找权值两个最小的根结点.选15,18组成一棵二叉数。
然后,把15,18去掉。
用根结点的权值33加入原序列。
升序排列。
22,33
9、在新的序列中找权值两个最小的根结点.选22,33组成一棵二叉数。
然后,把22,33去掉。
用根结点的权值55加入原序列。
55
21、能力:
1)按右图所示的二叉树建立二叉链表,然后:
2)按“中序”遍历二叉链表;3)求树高度;
调试完毕后,将完整代码写在实验报告册上。
要求:
将关键代码加注释,注释行数不少于总代码行的2/3。
#include
#include
typedefcharelemtype;
typedefstructBiNTree{/*定义二叉树结点类型*/
elemtypedata;
structBiNTree*lchild;
structBiNTree*rchild;
}BiNTree,*BiTree;/创建一棵二叉树
voidCreateBiTree(BiTree&T)
{if(T)free(T);
cin>>ch;
if(ch=='#')T=NULL;
else
{T=(BiTNode*)malloc(sizeof(BiTNode));
T->data=ch;
CreateBiTree(T->lchild);
CreateBiTree(T->rchild);/递归创建一棵二叉树
}
returnOK;
}
voidInOrderTraverse(BiTreeT)中序遍历
{
if(T){
InOrderTraverse(T->lchild);访问左子树
printf("%c",T->data);
InOrderTraverse(T->rchild);访问右子树
}
}
intDepth(BiTreeT){求树高
intdepl,depr;左右子树的高度
if(T){
depl=Depth(T->lchild);
depr=Depth(T->rchild);
if(depl>=depr)return(depl+1);
elsereturn(depr+1);返回子树高度加上根节点高度
}
return0;
}
intmain(void)调用函数
{
BiTreet;/*定义二叉数*/
CreateBiTree(t);
printf("\n中序输出");
InOrder(t);访问二叉树
Depth(t);
return0;
}
22、带“空指针域标记”的中序序列能否确定二叉树的形态?
为什么?
不能
图
23、
(1)画出图(a)的邻接表,并说明如何根据其邻接表求结点V1的入度和出度。
P164页第一个图
在有向图的邻接表中,第i个链表中结点的个数是顶点Vi的出度。
此邻接表中V1邻接的节点为两个,则V1的出度为2
但是要求Vi的入度较困难,需遍历整张表。
此邻接表中只有顶点V4的单链表中有V1,则V1的入度为1
(2)写出从V1开始的深度优先遍历序列。
例:
V1——V3——V4——V2(答案不唯一)
方法:
(1)从图中的某个顶点V出发,访问之;
(2)依次从顶点V的未被访问过的邻接点出发,深度优先遍历图,直到图中所有和顶点V有路径相通的顶点都被访问到;
(3)若此时图中尚有顶点未被访问到,则另选一个未被访问过的顶点作起始点,重复上述
(1)
(2)的操作,直到图中所有的顶点都被访问到为止。
(基本思路(假定从A出发)
先访问A点,再访问A的第1个尚未访问的邻接点B;再访问B的第1个尚未访问的邻接点C;再访问C的第1个尚未访问的邻接点D;……。
到头后沿原路返回,再访问返回路径上其他点的第1个尚未访问的邻接点,直至所有顶点访问完毕。
)
(3)画出图(b)的邻接矩阵,并说明如何根据其邻接矩阵求结点V1的度。
V1V2V3V4V5
V101010
V210101
V301011
V410100
V501100
(4)写出从V2开始的广度优先遍历序列。
例:
V2--V1--V3--V5--V4(答案不唯一)
方法:
(1)从图中的某个顶点V出发,访问之;
(2)依次访问顶点V的各个未被访问过的邻接点,将V的全部邻接点都访问到;
(3)分别从这些邻接点出发,依次访问它们的未被访问过的邻接点,并使“先被访问的顶点的邻接点”先于“后被访问的顶点的邻接点”被访问,直到图中所有已被访问过的顶点的邻接点都被访问到。
广度优先搜索不是一个递归的过程,它需要借助于队列完成(基本思路
图的广度优先遍历的思路是:
尽可能先对横向进行遍历,先访问的节点其邻接点也最先被访问。
)
查找
24、集合元素的关键字依次为:
1,2,3,4,6,8,20,25,26,27,40,50。
(1)画出二分查找的判定树;
某个结点所在的层数,就是查找该结点需要比较的次数(节点的值不是关键字的值,而是关键字在表中的位置)
我们对一维数组中存放的元素1523384755628895102123这十个数用二分法查找元素95要用到二叉树构建的方法.如果查找数组元素个数是偶数n=10,那就将(n+1)/2=5.5,这里有向上取整和向下取整两种方法,我用向下取整这种方法解释下。
5.5向下取整就是5,所以数组的第五个元素55作为二叉树的根节点.这时数组分为了两堆.15233847和
628895102123.还是同样的方法15233847这一堆的中间元素是(4+1)/2=2.5向下取整就是元素23,而628895102123这一堆本来就是奇数,所以直接将95作为他们的中间元素,此时的左边一堆的中间元素23和右边一堆的中间元素95分别作为刚刚原数组中间元素55这个根节点的左子树和右子树。
然后又将元素分成了15(以23作为中间元素的左边一堆)和3847(以23作为中间元素的右边一堆)和6288(以95作为中间元素的左边一堆)和102123(以95作为中间元素的右边一堆)这四堆。
分别取四堆的中间元素,15、38、62、102.其中15和38分别作为节点23的左、右子树,而62和102作为节点95的左、右子树。
然后就该是八堆了.但是15只有一个元素所以他就只是叶子节点了,3847取走38后只剩47所以47作为节点38的子树寄叶子节点,右边6288取走62后剩88作为62的叶子节点,102123取走102后只有123作为他的叶子节点。
现在要查找95这个元素.第一次访问根节点55,然后第二就可以访问根节点的右子树95节点了.所以只要两次就可以了.
(2)每个结点查找等概率情况下,求平均查找长度。
ASL=P1C1+P2C2+P3C3+...+PnCn
Pi与Ci分别表示第i个数被
 升级会员
升级会员 