并行计算机体系结构.docx
《并行计算机体系结构.docx》由会员分享,可在线阅读,更多相关《并行计算机体系结构.docx(17页珍藏版)》请在冰豆网上搜索。
并行计算机体系结构
第2章并行计算机体系结构
内容提要:
2.1
并行机网络互联拓扑结构
2.2
并行机访存模型与多级存储结构
2.3
并行机分类
2.4
并行机举例
2.5
并行计算机的发展史
并行机网络互联拓扑结构
•参考资料:
■文献1:
第节:
■文献2:
详细阐述;
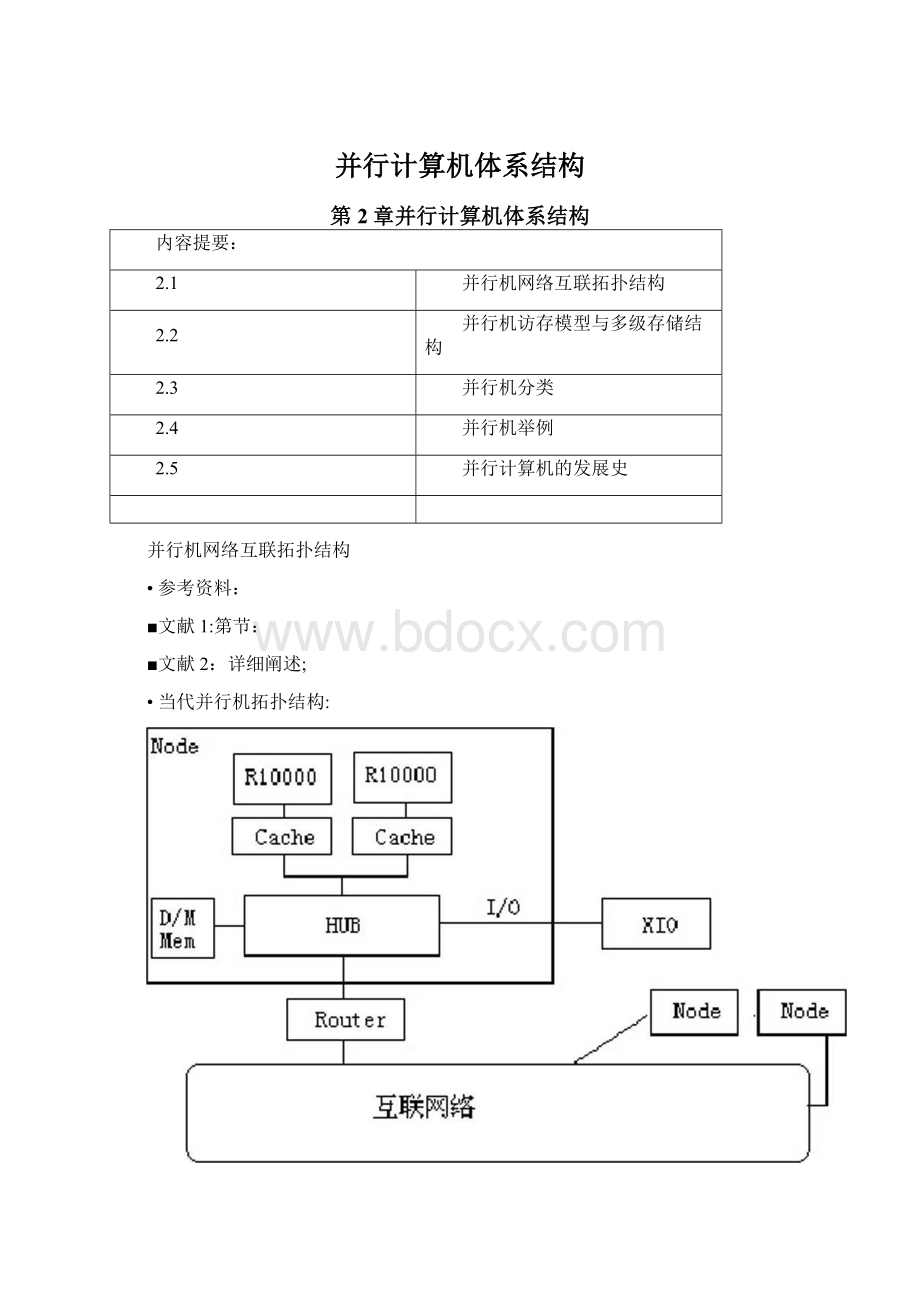
•当代并行机拓扑结构:
•并行机体系结构的几个要素:
■结点:
包含一个或多个CPU,这些CPU通过HUB或全互联交叉开关相互联接,并共享内存,也可以直接与外部进行I/O操作:
■路由器:
联接讣算结点与互联网络,负责数据在结点间的路由寻址;
■互联网络:
将所有路由器以某种拓扑结构相互联接,保证它们之间可以自由地通信。
•互联网络:
■拓扑结构:
将并行机各结点之间物理上相互联接的关系用图来表示,其中图中结点代表并行机的结点,图中连线代表它所联接的两个结点的路由器之间存在物理上的直接联接关系,我们称该图为并行机互联网络拓扑结构:
■拓扑结构的几个重要定义:
>并行机规模:
并行机包含的结点总数,或者包含的CPU总数:
>结点度:
互联网络拓扑结构中联入或联出的一个结点的边的条数,称为该结点的度:
>结点距离:
两个结点之间跨越的图的边的条数:
>网络宜径:
网络中任意两个结点之间的最长距离:
>点对点带宽:
图中边对应的物理联接的物理带宽:
>点对点延迟:
图中任意两个结点之间的一次零长度消息传递必须花费的时间。
延迟与结点间距离相关,英中所有结点之间的最小延迟称为网络的最小延迟,所有结点之间的最大延迟称为网络的最大延迟:
>折半宽度:
对分网络成两个部分(它们的结点个数至多相差1)所必须去掉的边的网络带宽的总和;
>总通信带宽:
所有边的带宽之和;
■互联网络评价:
>大:
结点度、点对点带宽、折半宽度、总通信带宽;
>小:
网络直径、点对点延迟:
•互联网络的分类:
静态拓扑结构、动态拓扑结构、宽带互联网络;
■静态拓扑结构:
结点之间存在固泄的物理联接方式,程序执行过程中,结点间的点对点联接关系不变,例如:
[文献1:
P10-P11,给出各类泄义的具体值,文献2详细讨论]:
>一维阵列(Array)、环(Ring);
>多维网格(Mesh)、多维环(Torus):
>树(Tree):
二叉树、X-树、星树、胖树:
>超立方体(Hypercube);
■动态拓扑结构:
结点之间无固左的物理联接关系,而是在联接路径的交叉点处用电子开关、路由器或仲裁器等提供动态联接的特性,主要包含单一总线、多层总线、交叉开关、多级互联网络:
>单-总线:
联接处理器、存储模块和I/O设备等的一组导线和插座,在主设备
(处理器)和从设备(存储器)之间传递数据,特征有:
◊公用总线以分时工作为基础,各处理器模块分时共享总线带宽,即在同一个时种周期,至多只有一个设备能占有总线;
◊总线带宽=总线主频X总线宽度,例如ASUS主板的总线频率=150MHz,总线宽度为64位,则该总线的带宽审;
◊监听协议与仲裁算法:
选择哪个设备占有总线;
◊例如:
微机主板外部数据总线、PCI总线、ASCIWhite每个结点包含16个CPU,CPU之间通过总线共享局部存储器:
>务层总线:
各设备内部存在本地总线(结点、存储器、I/O设备),本地总线之间以系统总线相互联接,系统总线一般在通信主板中实现,例如文献1P14图。
>交义幵关(CrossbarSwitcher):
所有结点通过交叉开关阵列相互连接,每个交叉开关均为其中两个结点之间提供一条专用联接通路,同时,任意两个结点之间也能找到一个交叉开关,在它们之间建立专用联接通路。
交叉开关的状态可根据程序的要求动态地设程为“开”和“关”。
例如4x4交叉开关联接8个结点(黑板上画图说明)。
交叉开关特征:
◊结点之间联接:
交叉开关一般构成NxN阵列,但在每一行和每一列同时只能有一个交叉点开关处于"开”状态,从而它同时只能接通N对结点;
◊结点与存储器之间的联接:
每个存储器模块同时只允许一个结点访问,故每一列只能接通一个交叉点开关,但是为了支持并行存储访问,每一行同时可以接通多个交叉点开关。
◊交叉开关的成本为N2,N为端口数,限制了它在大规模并行机中的应用,一般适合8-16个处理器的情形.
>匕级联网络(MIN:
MultistageInterconnectionNetwork):
由多个单级交叉开关级联接尼来形成大型交叉开关网络,相邻交叉开关级之间存在固定的物理联接拓扑。
为了在输入与输出之间建立联接,可以动态地设崟开关状态。
例如:
◊一般联接图:
文献1图,其中ISC为该级互联网络,主要有混洗、蝶网、纵横交叉等:
(详细参考文献2)
◊蝶网、CCC网、Benes网:
均为超立方体网络的推广,参考文献2的P215-P225。
◊Q网:
等价于蝶网,参考文献1的P16图。
■宽带互联网络:
>快速以太网(10Mbps(82年)、100Mbps(94年)、lGbps(97年)):
国际标准,三代网络性能比较参考文献1的P18表,特征类似于单一总线:
◊分时共享、竞争仲裁:
带宽100Mbps,8台处理机共享,每台处理机的平均带宽为Mbps。
>FDDI:
光纤分布式数据接口(FiberDistributedDataInterface)采用双向光纤令牌环,所有结点联接在该环中,提供100-200Mbps数据传输速度,双向环提供冗余通路以提供可靠性,距离可达100米、2公里、60公里等,比快速以太网具有更好的可靠性、适应性;
>Switcher:
交叉开关,可同时为N/2对端口提供100Mbps的宜接联接通路,英中N为端口总数。
多个Switcher堆叠(不多于7个)可形成多级Switcher。
Beowulf微机机群采用这种结构互联所有结点。
(参考张林波讲义之图)。
>ATM:
异步传输模式(ATM:
AsynchronousTransferMode)是在光纤通信基础上建立起来的一种新的宽带综合业务数字网的交换技术。
介质无关的信息传输协议,采用53字节的龙长短数据单元(cell)进行传输。
大的数据包进入ATM网络时,分解成多个定长的单元,各个单元独立传输,到达目的地址后,这些单元汇集成原来的数据包。
ATM网络适合髙速度传输声音、图像、视频和数据等的所有形式的媒体。
>Mvrinet:
专用机群互联网络,带宽可达200MB/秒,延迟小于10us。
>Infiniband:
专用机群互联网络,带宽可达秒,延迟小于6us。
>Qudrics:
专用机群互联网络,带宽可达400MB/秒,延迟小于6us。
>HiPPI:
髙性能并行接口(HighPerformanceParallelInterface),1993年标准()形成。
单工点对点的数据传输界而,带宽可达800Mb/so
•互联网络的路由选择算法:
■定义:
>数据包(Packet):
结点间数据在网络中传输的最小单位,一般为几十个、或者几百个字节。
>路由选择算法:
网络中数据包传输的路径选择。
>申请队列长度:
在某条边上等待传输的数据包的个数。
■常用路由选择算法:
>贪心法:
每个数据包沿最短路径传输(二维阵列举例),该方法容易在某一条边上形成通信阻塞。
>动态路由选择算法:
数据包根据当前边的申请队列长度,动态地改变传输路径。
>虫孔算法(Wormhole):
数据包分解为长度更小的字肖流,所有字节流在网络中按动态路由选择算法在网络中传输,最后在目的地址合并还原成数据包。
•作业:
■作业:
假设网络包含P=2N=M3个结点,请给出一维阵列(环)、二维网格(Torus)、三维网格(Torus)、超立方体、二叉树(叶结点个数为P)、蝶网、Benes网的结点度、点对点延迟(以跨越的边的条数为单位)、折半宽度(以边的条数为单位)、网络直径。
■作业:
假设存在8个结点,分别联接在lGbps的快速以太网和100Mbps的24端口的Switcher上,请问任意两个结点间的平均带宽为多少,如果结点数增加一倍,则平均带宽又为多少。
并行机存储结构
•参考资料:
■文献1:
第节:
■文献8、文献10;•并行机存储模块
■内存模块与结点分离
结点0
结点P
图内存模块局部于结点内部
结点P
CPU0
CPU1
n匸
匚
Cache
Cache
结点0
CPU0
CPU1
Jt
Cache
Cache
□r
L
互联网络
并行机访存模型
■均匀访存模型(UMA:
UniformMemoryAccess):
内存模块与结点分离,分别位于互联网络的两侧(图),互联网络一般采用系统总线、交叉开关和多级网络,称之为紧耦合系统(TightlyCoupledSystem)-具有如下特征:
♦物理存储器被所有结点均匀共享;
♦所有结点访问任意存储单元的时间相同;
♦访存竞争时,仲裁策略对每个结点均是机会等价的;
♦各结点的CPU可带有局部私有高速缓存(Cache):
♦外围I/O设备也可以共享,且对各结点等价。
■北均匀访存模型(NU2IA:
NonuniformMemoryAccess):
内存模块局部在各个结点内部(图),所有局部内存模块构成并行机加全局内存模块。
具有如下特征:
♦任意结点可以直接访问任意内存模块:
♦结点访问内存模块的时间不一致:
访问本地存储模块的速度一般是访问其他结点内存模块的3倍以上:
♦访存竞争时,仲裁策略对结点可能是不等价的:
♦各结点的CPU可带有局部私有髙速缓存(Cache);
♦外围I/O设备也可以共享。
■Cache一致性非均匀访存模型(CC-NUMA:
Coherent-CacheNonuniformMemoryAccess):
存在专用硬件设备保证在任意时刻,冬结点Cache中数据与全局内存数据的一致性,具有特征:
♦各CPU的局部Cache数据来源于全局内存,并保证所有结点中数据的一致性
(画图简单说明):
♦大多数访存可以局部在本地高速Cache;
♦基于目录的Cache-致性协议(Cache原理参考下章)。
■分布式访存模型(DMA:
DistributedMemoryAccess):
各个结点的存储模块只能被局部CPU访问,其他结点无法直接访问局部存储模块,称之为分布式存储(图),具有特征:
♦内存模块分布局部于各个结点,每个结点只能直接访问其局部存储模块,对其他结点的内存访问只能通过消息传递程序设计•来实现;
♦每个结点均是一台由处理器、存储器、I/O设备组成的自洽计算机。
•多级存储结构:
500MHzPentium-IllCluster
CPU
一级Cache
二级Cache
本地局部内存
chip
寄存器
容量(B)带宽(MB/s)延迟(ns)
忌程内存(MPI消息传递)
256
6000
2
32K
4000
6
512K
2000
80
500M
1200
320
海量
100
100,000
处理机
每位成本增加
■
•访存延迟比例:
>微机机群1:
3:
40:
160:
50,000
>Origin20001:
3:
30:
50:
500
•一次消息传递延迟相当于峰值浮点运算的次数:
>微机机群:
50,000次
>Origin2000:
1000次
•通信与CPU计算速度不匹配:
并行机分类
•参考资料:
■文献1:
P21-P25:
■文献6:
第1章:
■文献久10、11:
•指令与数据流分
 升级会员
升级会员 