用第七课多元统计分析概要.docx
《用第七课多元统计分析概要.docx》由会员分享,可在线阅读,更多相关《用第七课多元统计分析概要.docx(23页珍藏版)》请在冰豆网上搜索。
用第七课多元统计分析概要
数据挖掘
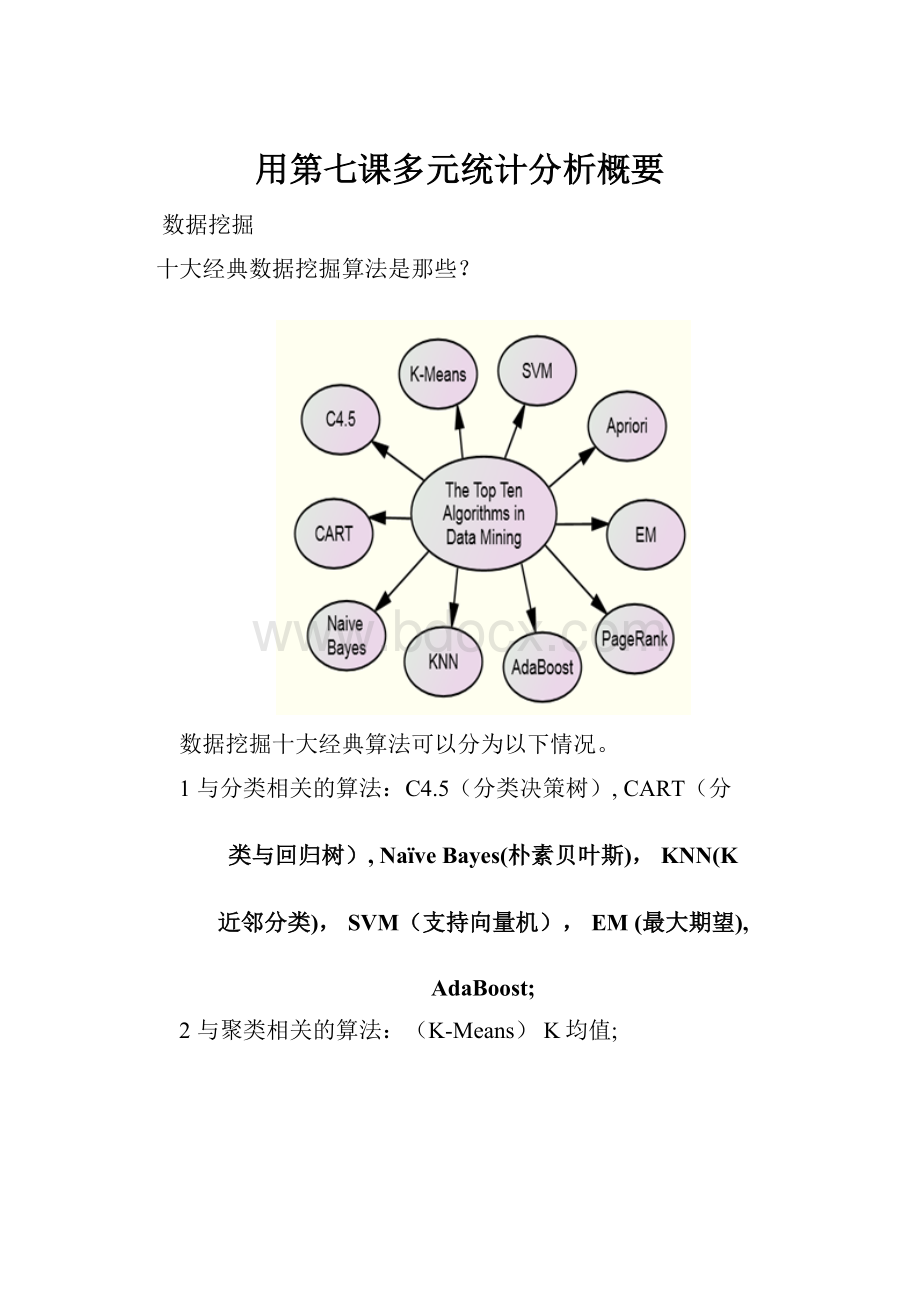
十大经典数据挖掘算法是那些?
数据挖掘十大经典算法可以分为以下情况。
1与分类相关的算法:
C4.5(分类决策树),CART(分
类与回归树),NaïveBayes(朴素贝叶斯),KNN(K
近邻分类),SVM(支持向量机),EM(最大期望),
AdaBoost;
2与聚类相关的算法:
(K-Means)K均值;
3与关联规则相关的算法:
Apriori;
4与搜索引擎相关的算法:
PageRank.
1.判别分析
是用于判别个体所属群体的一种统计方法,属于分类。
判别通常由3种方法:
距离判别、Fisher判别和Bayes判别,它们本质上属于线性判别和
二次判别,R并没有给出这3种判别,而是3中判别法综合在一起,分别给出线性判别函数lda()和二次判别函数qda()函数。
lda()和qda()使用前,需要加载MASS程序包:
library(MASS)
它们的使用形式基本相同,有公式形式,矩阵或数据框形式两种:
公式格式为:
(加载MASS包:
library(MASS))
lda(formula,data,...,subset,na.action)
qda(formula,data,...,subset,na.action)
参数formula为公式,形如groups~x1+x2+…,data为数据构成的数据框,subset为可
选择向量,表示观察值的子集,na.action为函数,表示处理缺失数据的方法。
lda()函数的返回值有:
调用方法、先验概率、每一类样本的均值和线性判别系数,qda()函数的返回值与lda()函数的返回值相同,只是没有线性判别系数,因此,无论预测还是回代,还需要有预测函数predict()函数。
对于lda()函数而言,predict()函数的使用格式:
predict(object,newdata,prior=object$prior,dimen,method=c(“plug-in”,"predictive",”debiased”),…)
对于qda()函数而言,predict()函数的使用格式:
predict(object,newdata,prior=object$prior,method=c(“plug-in”,"predictive",”debiased”,”looCV”),…)
参数object为lda()函数或qda()函数生成的对象;当lda()或qda()使用公式形式计算时,
newdata为预测数据构成的数据框;当lda()或qda()使用矩阵或因子计算时,newdata为向量,
默认值为全体训练样本;prior为先验概率,默认值使用对象的先验概率,dimen为使用空间的
维数,method为参数估计的方法。
predict()函数的返回值有:
$class(分类),$posterior(后验概率),$x(qda函数无此项)。
例1某气象站检测前14年气象的实际资料如下表,有两项综合预报因子,其中有春旱的是6个年份资料,无春旱的是8个年份资料,今年测到两个指标的数据为(23.5,-1.6),试用lda()函数和qda()函数对数据做判别分析,并预报今年是否有春旱。
表某气象站有无春旱的资料
序号春旱无春旱
124.8-2.022.1-0.7
224.1-2.421.6-1.4
326.6-3.022.0-0.8
423.5-1.922.8-1.6
525.5-2.122.7-1.5
627.4-3.121.5-1.0
722.1-1.2
821.4-1.3
解:
数据框输入数据,格式调用
exam.data<-data.frame(
X1=c(24.8,24.1,26.6,23.5,25.5,27.4,
22.1,21.6,22.0,22.8,22.7,21.5,22.1,21.4),
X2=c(-2.0,-2.4,-3.0,-1.9,-2.1,-3.1,
-0.7,-1.4,-0.8,-1.6,-1.5,-1.0,-1.2,-1.3),
sp=rep(c("Have","No"),c(6,8))
)
new<-data.frame(X1=23.5,X2=-1.6)
lda.sol<-lda(sp~X1+X2,data=exam.data)
predict(lda.sol,new)$class
table(exam.data$sp,predict(lda.sol)$class)
##看二次判别结果:
qda.sol<-qda(sp~X1+X2,data=exam.data)
predict(qda.sol,new)$class
table(exam.data$sp,predict(qda.sol)$class)
同学自己看一下,lda()和qda()结果是否一样?
例2(FisherIris数据)Iris数据有4个属性,萼片的长度、萼片的宽度、花瓣长度和花瓣的宽度。
数据共150个样本,分为3类,前50个数据为第一类——Setosa,中间的50个数据为第二类——Versicolor,最后50个数据为第3类——Virginica,数据格式如下表所示,试用R软件中的判别函数(lda或qda)对Iris数据进行判别分析。
表FisherIris数据
序号萼片的长度萼片的宽度花瓣长度花瓣的宽度种类
15.13.51.40.2Setosa
24.93.01.40.2Setosa
505.03.31.40.2Setosa
517.03.24.71.4Versicolor
1005.72.84.11.3Versicolor
1016.33.36.02.5Virginica
1505.93.05.11.8Virginica
解(exam0713.R)R中提供了Iris数据(数据框iris),数据的第5列表明数据属于哪一类。
在150个样本中随机选取100个作为训练样本,余下的50个作为待测样本,先验概率各为1/3。
train<-sample(1:
150,100)##从150个数中随机抽取100个数
z<-lda(Species~.,iris,prior=c(1,1,1)/3,subset=train)
class<-predict(z,iris[-train,])$class
class
sum(class==iris$Species[-train])
###看一下预测结果的准确性(统计:
预测的类别等于真值的类别个数)
结果:
[1]48
……………………………………………..完………………………………………….
习题某医生为研究舒张压与血浆胆固醇对冠心病的影响情况,随机抽取并测定了某地从事某特殊工作的50~59岁女工冠心病人和正常人各15例的舒张压(DBP)与血浆胆固醇(CHOL),见下表,试分析测定结果,并提供对未知个体(DBP=10.66,CHOL=5.02)属于冠心病患者还是正常人的判断。
解:
library(MASS)
exam.data<-data.frame(
DBP=c(9.86,13.33,14.66,9.33,12.80,10.66,10.66,13.33,13.33,13.33,12.00,14.66,13.33,12.80,13.33,
10.66,12.53,13.33,9.33,10.66,10.66,9.33,10.66,10.66,9.33,10.40,9.33,10.66,10.66,11.20),
CHOL=c(5.18,3.73,3.89,7.10,5.49,4.09,4.45,3.63,5.96,5.70,6.19,4.01,4.01,3.63,5.96,
2.07,4.45,3.06,3.94,4.45,4.92,3.68,2.77,3.21,3.63,3.94,4.92,2.69,2.43,3.42),
sp=rep(c("Have","No"),c(15,15))
)
new<-data.frame(DBP=10.66,CHOL=5.02)
lda.sol<-lda(sp~DBP+CHOL,data=exam.data)
predict(lda.sol,new)$class
table(exam.data$sp,predict(lda.sol)$class)
##看二次判别结果:
qda.sol<-qda(sp~DBP+CHOL,data=exam.data)
predict(qda.sol,new)$class
table(exam.data$sp,predict(qda.sol)$class)
………………………………………………完……………………………………………..
练习
###读用户Excel文件"ch1.xls",做分类,表中说明类别属性“身份”,1将军,
2军师,3武官,4文官。
install.packages("RODBC")
library(RODBC)
con<-odbcConnectExcel("ch1.xls")##连接Excel表格
##ch1.xls是你自己的文件名
tbls<-sqlTables(con)##得到Excel表格信息
sh1<-sqlFetch(con,tbls$TABLE_NAME[3])#读取Excel表格的有信息的sheet页
##通常TABLE_NAME[1]对应sheet1页有信息,一般共3页
sh2<-sh1[,-(1:
2)]
library(MASS)##qda()函数在此包中
new<-data.frame(统御=66,武力=89,智慧=78,政治=56,魅力=76,忠诚=66,国别=3,出身=2)
qda.sol<-qda(身份~.,data=sh2)
predict(qda.sol,new)$class
table(sh2$身份,predict(qda.sol)$class)
完成练习(自己)###读用户Excel文件"ch1.xls",做分类,表中说明类别属性“肾细胞癌转移情况”,0-无转移,1-有转移
……………………………………………………..完………………………………
聚类分析(系统聚类、动态聚类)
思想:
将相似性(或相异性)数据看成是对象之间的“距离”远近的一种度量,将距离近的对象归入一类,不同类之间的对象距离较远。
根据分类对象不同分为Q型聚类分析和R型聚类分析,Q型聚类分析是指:
对样本进行聚类;R型聚类分析是指:
对变量进行聚类。
1.距离和相似系数
变量大致可分为两类1)定量变量,是连续值,具有数值特征,数量上的变化;2)定性变
量,这些量并非具有数量上的变化,而只有性质上的差异,大致分两类,一为有序变量,没有数量关系,只有次序关系,如一等品、二等品等;二为名义变量,既无等级,也无次序,如天气(阴,晴)等。
1.1.距离:
若数据集中有n个样本,则这n个样本就是数据集中的n个点,如每个样本有k个指标(分量),则
为第i个样本的第k个指标,第i个样本的第j个样本的距离记为
,聚类过程中,距离近的归为一类,距离远的归属不同类。
在R中,dist()函数计算各样本间的距离,格式:
dist(x,method="euclidean",diag=FALSE,upper=FALSE,p=2)
参数x为数值矩阵,或者为数据框,或者是“dist”对象;method为定义距离的方法,默认值是euclidean,表示欧几里德距离(即
),还可选绝对值距离、无穷模距离等;diag为逻辑变量,表示输出上三角矩阵值,默认为FALSE,表示仅输出下三角阵值;p表示距离
的参数q,默认值为2,即欧几里德距离。
1.2数据变换
做聚类分析时,需要将数据做中心化或标准化处理,
称:
,
,i=1,2,..,n;j=1,2,...,p为中心化变换,
称:
,
,i=1,2,..,n;j=1,2,...,p为标准化变换
在R中,scale()函数做数据的中心化或标准化,格式:
scale(x,center=TRUE,scale=TRUE)
参数x为样本构成的数值矩阵,center或者为逻辑变量,表示是否对数据做中心变换,默认值为TRUE;或者为数值向量,其维数等于矩阵x的列数,表示以center为中心做中心化变换;scale或者为逻辑变量,表示对数据是否做标准变换,默认值为TRUE,或者为数值向量,其维数等于矩阵x的列数,表示以scale为尺度做标准化变换。
1.3相似系数
聚类分析不仅对样本分类,而且对变量进行分类,对变量分类时,常用相似系数度量变量之间的相似程度。
设
表示变量
和
间的相似系数,要求:
(1)
=
1,当且仅当
;
(2)
,对一切i,j成立;
(3)
,对一切i,j成立。
越接近1,则表示
和
间的关系越密切,越接近0两者间关系越疏远。
用cor()函数计算相关系数。
变量间的距离可用相关系数求解:
(往往用在变量聚类(R型聚类)中)
2系统聚类法
最普遍方法,思想:
将距离最近类合并成一个类,重复进行两最近类合并,直至所有样本合并为一个类,方法很多:
最短距离法:
“single”
最长距离法:
“complete”
中间距离法:
“median”
类平均法:
“average”
重心法:
“centroid”
离差平方和法:
“Ward”
Mcquitty相似法:
“mcquitty”
2.1hclust()函数计算系统聚类,plot()函数画出系统聚类的树形图(谱系图),plclust()函数也可画谱系图;
格式:
hclust(d,method="complete",members=NULL)
参数d为dist()函数生成的对象,即距离。
method为系统聚类的方法,默认值为“complete”代表最长距离法,“single”代表最短距离法,“median”代表中间距离法,“average”代表类平均法等;members或者为NULL(默认值),或者为与d有相同变量长度的向量。
格式:
plot(x,labels=NULL,hang=0.1,...)
参数x为hclust()函数生成的对象;labels为树叶的标记,默认值为NULL;hang为数值,表明谱系图中各类所在的位置,默认值为0.1,取负值表示谱系图中的类从底部画起;其他参数意义与plot()函数相同。
格式:
plclust(tree,hang=0.1,unit=FALSE,level=FALSE,hmin=0,square=TRUE,labels=NULL,plot.=TRUE,axes=TRUE,frame.plot=FALSE,ann=TRUE,main="",sub=NULL,xlab=NULL,ylab="Height")
参数tree为hclust()函数生成的对象;unit为逻辑变量,取TRUE表示分叉画在等空间高度,而不是在对象的高度。
其他参数意义见帮助文档。
例1设有5个样本,每个样本只有一个指标,分别是1,2,6,8,11,样本间的距离选用欧几里得距离,试用最短距离法、最长距离法等方法进行聚类分析,并画出相应的谱系图。
##%%输入数据,生成距离结构
x<-c(1,2,6,8,11);dim(x)<-c(5,1);##x已转化成矩阵:
5行1列
d<-dist(x)
##%%生成系统聚类
hc1<-hclust(d,"single");hc2<-hclust(d,"complete")
hc3<-hclust(d,"median");hc4<-hclust(d,"average")
##%%绘出所有树形结构图,并以/2*2/的形式绘在一张图上
opar<-par(mfrow=c(2,2),omi=rep(0,4))
plot(hc1,hang=-1);plot(hc2,hang=-1)
plot(hc3,hang=-1);plot(hc4,hang=-1)
par(opar)
##%%保存图形
savePlot("hclust_1",type="eps")
##%%用plclust函数绘图
opar<-par(mfrow=c(2,2),omi=rep(0,4),mar=c(5,4,1,1))
plclust(hc1,hang=-1);plclust(hc2,hang=-1)######绘图结果一样
plclust(hc3,hang=-1);plclust(hc4,hang=-1)
par(opar)
3聚类方法的评价:
cophenetic()函数:
计算系统聚类的Cophenetic距离;
格式:
cophenetic(x),参数x为hclust()函数或as.hclust()函数生成的对象。
用途:
通过计算Cophenetic距离与dist()函数的距离的相关系数,用以评价聚类方法好坏,
越接近1,方法越好。
例2上例1中4种聚类方法,分别计算cophenetic距离和各自与距离d的相关系数:
##%%使用cophenetic函数,作聚类方法的比较
x<-c(1,2,6,8,11);dim(x)<-c(5,1);d<-dist(x)
method=c("single","complete","median","average")
cc<-numeric(0)
for(minmethod){
dc<-cophenetic(hclust(d,m))
cc[m]<-cor(d,dc)
}
cc
执行结果:
singlecompletemedianaverage
0.77444790.78478850.78597800.7865155
越接近1方法越好,所以average方法最好
4类个数的确定
有几种方法:
(1)给定一个阈值,要求类与类之间的距离大于阈值;
(2)观察样本散点图;(3)使用统计量;(4)根据谱系图确定分类个数准则。
4.1cutree()函数:
根据谱系图确定聚类个数。
格式:
cutree(tree,k=NULL,h=NULL)
参数tree为hclust()函数生成的对象;k为整数向量,表示类的个数;h为数值型向量,表示谱系图中的阈值,要求分成的各类距离大于h.在参数中,k和h至少指定一个,若两个均被指定,以k为准。
例3对305名女中学生测量8个体型指标,有下列相应的相关矩阵,将相关系数看成相似系数,定义距离:
,用最长距离法做系统分析。
有8个体型指标相关系数:
x<-c(1.000,0.846,0.805,0.859,0.473,0.398,0.301,0.382,
0.846,1.000,0.881,0.826,0.376,0.326,0.277,0.277,
0.805,0.881,1.000,0.801,0.380,0.319,0.237,0.345,
0.859,0.826,0.801,1.000,0.436,0.329,0.327,0.365,
0.473,0.376,0.380,0.436,1.000,0.762,0.730,0.629,
0.398,0.326,0.319,0.329,0.762,1.000,0.583,0.577,
0.301,0.277,0.237,0.327,0.730,0.583,1.000,0.539,
0.382,0.415,0.345,0.365,0.629,0.577,0.539,1.000)
names<-c("身高","手臂长","上肢长","下肢长","体重","颈围","胸围","胸宽")
r<-matrix(x,nrow=8,dimnames=list(names,names))
d<-as.dist(1-r);hc<-hclust(d);
plot(hc,hang=-1);##绘谱系图
cutree(hc,k=2)##根据谱系图确定聚类个数2
执行结果:
身高手臂长上肢长下肢长体重颈围胸围胸宽
11112222
4.2rect.hclust()函数:
根据谱系图确定最终聚类,并在谱系图做出标记。
格式:
rect.hclust(tree,k=NULL,which=NULL,x=NULL,h=NULL,border=2,cluster=NULL)
参数tree,k,h的意义与cutree()函数相同,which和x为整数向量,表示围绕着哪一类画出矩形;which从左到右是按数字选择,默认1:
k;x是按水平坐标选择;border数字向量或字符串,表示矩形框的颜色;cluster为可选向量,是由cutree()函数得到的聚类结果。
例4对于例3,有:
par(mai=c(1,0.8,0.1,0.1))
plclust(hc,hang=-1);re<-rect.hclust(hc,k=3)
########根据谱系图确定最终聚类,并在谱系图做出标记
savePlot("hclust_4",type="bmp")
5实例
给出1999年全国31个省市自治区的城镇居民家庭平均每人全年消费性支出的8个主要指标数据,分别是:
食品(x1)、衣着(x2)、家庭设备用品及服务(x3)、医疗保健(x4)、交通与通讯(x5)、娱乐教育文化服务(x6)、居住(x7)、杂项商品和服务(x8),分别用最长距离法、类平均法、重心法、Ward法对各地区做聚类分析。
##%%读取数据
X<-read.table("exam0716.dat")
##%%生成距离结构,作系统聚类
d<-dist(scale(X))
method=c("complete","average","centroid","ward")
for(minmethod){
hc<-hclust(d,m);class<-cutree(hc,k=5)
print(m);print(sort(class))
}
......................................
 升级会员
升级会员 