Clementine利用经典实例.docx
《Clementine利用经典实例.docx》由会员分享,可在线阅读,更多相关《Clementine利用经典实例.docx(16页珍藏版)》请在冰豆网上搜索。
Clementine利用经典实例
下面利用AdventureWorks数据库中的TargetMail作例子,通过成立分类树和神经网络模型,决策树用来预测哪些人会响应促销,神经网络用来预测年收入。
TargetMail数据在SQLServer样本数据库AdventureWorksDW中的视图,关于TargetMail详见:
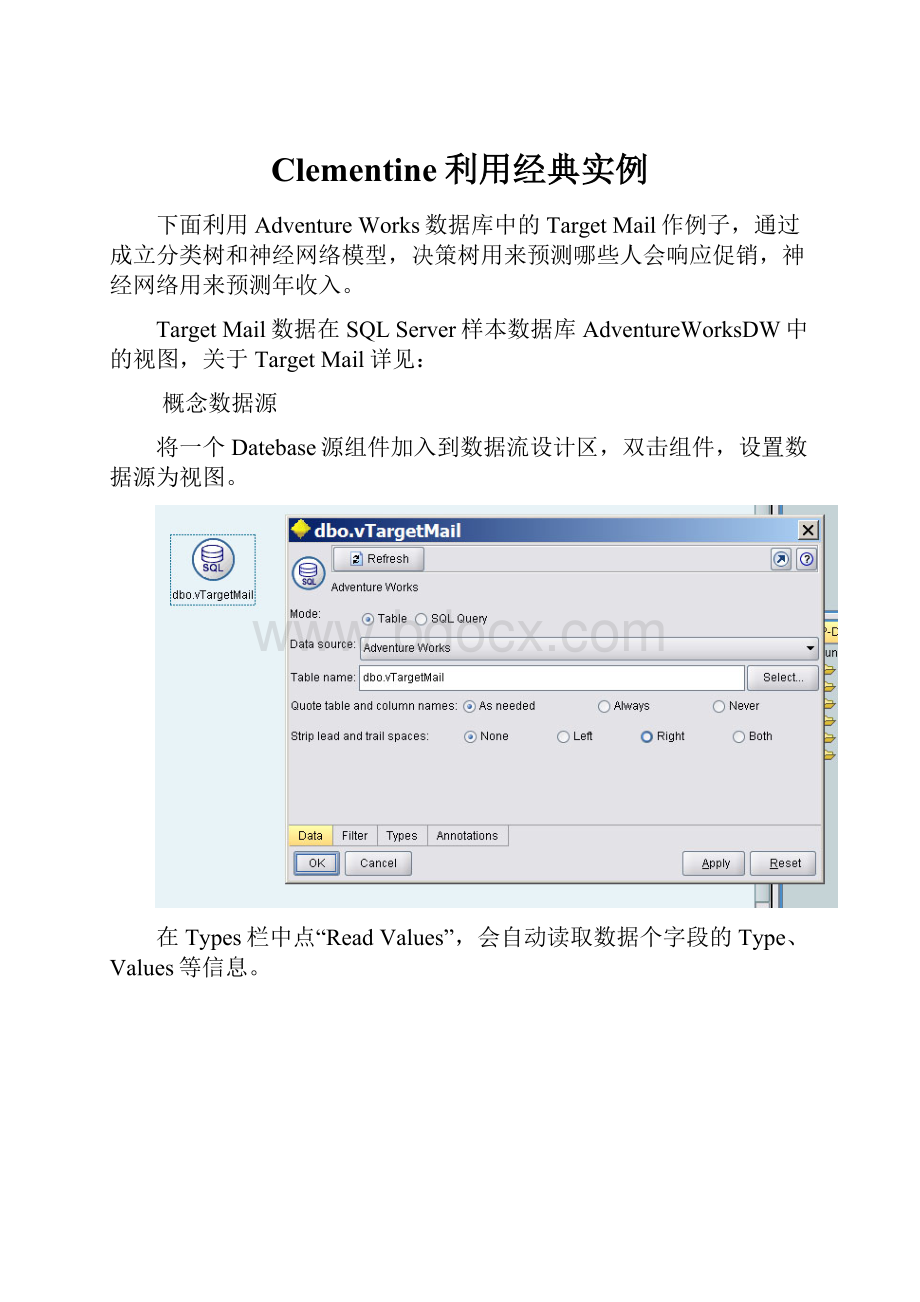
概念数据源
将一个Datebase源组件加入到数据流设计区,双击组件,设置数据源为视图。
在Types栏中点“ReadValues”,会自动读取数据个字段的Type、Values等信息。
Values是字段包括的值,比如在数据集中NumberCardsOwned字段的值是从0到4的数,HouseOwnerFlag只有1和0两种值。
Type是依据Values判定字段的类型,Flag类型只包括两种值,类似于boolean;Set是指包括有限个值,类似于enumeration;Ragnge是持续性数值,类似于float。
通过了解字段的类型和值,咱们能够确信哪些字段能用来作为预测因子,像AddressLine、Phone、DateFirstPurchase等字段是无用的,因为这些字段的值是无序和无心义的。
Direction说明字段的用法,“In”在SQLServer中叫做“Input”,“Out”在SQLServer中叫做“PredictOnly”,“Both”在SQLServer中叫做“Predict”,“Partition”用于对数据分组。
2. 明白得数据
在建模之前,咱们需要了解数据集中都有哪些字段,这些字段如何散布,它们之间是不是隐含着相关性等信息。
只有了解这些信息后才能决定利用哪些字段,应用何种挖掘算法和算法参数。
在除在成立数据源时Clementine能告知咱们值类型外,还能利用输出和图形组件对数据进行探讨。
例如先将一个统计组件和一个条形图组件拖入数据流设计区,跟数据源组件连在一路,配置好这些组件后,点上方绿色的箭头。
等一会,然后这两个组件就会输出统计报告和条形图,这些输出会保留在治理区中(因为条形图是高级可视化组件,其输出可不能出此刻治理区),以后只要在治理区双击输出就能够够够看打开报告。
3. 预备数据
将之前的输出和图形工具从数据流涉及区中删除。
将FieldOps中的Filter组件加入数据流,在Filter中能够去除不需要的字段。
咱们只需要利用MaritalStatus、Gender、YearlyIncome、TatalChildren、NumberChildrenAtHome、EnglishEducation、EnglishOccupation、HouseOwnerFlag、NumberCarsOwned、CommuteDistance、Region、Age、BikeBuyer这些字段。
加入Sample组件做随机抽样,从源数据中抽取70%的数据作为训练集,剩下30%作为查验集。
注意为种子指定一个值,学过统计和运算机的应该明白只要种子不变,运算机产生的伪随机序列是不变的。
因为要利用两个挖掘模型,模型的输入和预测字段是不同的,需要加入两个Type组件,将数据分流。
决策树模型用于预测甚麽人会响应促销而购买自行车,要将BikeBuyer字段作为预测列。
神经网络用于预测年收入,需要将YearlyIncome设置为预测字段。
有时候用于预测的输入字段太多,会花费大量训练时刻,能够利用FeatureSelection组件挑选对预测字段阻碍较大的字段。
从Modeling中将FeatureSelection字段拖出来,连接到神经网络模型的组件后面,然后点击上方的ExecuteSelection。
FeatureSelection模型训练后在治理区显现模型,右击模型,选Browse可查看模型内容。
模型从12个字段被选出了11个字段,以为这11个字段对年收入的阻碍比较大,因此咱们只要用这11个字段作为输入列即可。
将模型从治理区拖入数据流设计区,替换原先的FeatureSelection组件。
4. 建模
加入NearalNet和CHAID模型组件,在CHAID组件设置中,将Mode项设为”Launchinteractivesession”。
然后点上方的绿色箭头执行整个数据流。
Clementine在训练CHAID树时,会开启交互式会话窗口,在交互会话中能够操纵树生长和对树剪枝,幸免过拟合。
假设是确信模型后点上方黄色的图标。
完成后,在治理区又多了两个模型。
把它们拖入数据流设计区,开始评估模型。
5. 模型评估
修改抽样组件,将Mode改成“DiscardSample”,意思是抛弃之前用于训练模型的那70%数据,将剩下30%数据用于查验。
注意种子不要更改。
我那个地址只查验CHAID决策树模型。
将各类组件跟CHAID模型关联。
执行后,取得提升图、预测准确率表……
6. 部署模型
Export组件都能够利用Publish发布数据流,那个地址会产生两个文件,一个是pim文件,一个是par文件。
pim文件保留流的所有信息,par文件保留参数。
有了这两个文件就能够够够利用来执行流,是ClementineSolutionPublisher的执行程序。
ClementineSolutionPublisher是需要单独授权的。
在SSIS中pim和par类似于一个dtsx文件,就类似于。
如果要在其他程序中使用模型,可以使用Clementine执行库(CLEMRTL),相比起Microsoft的oledbfordm,SPSS的提供的API在开发上还不是专门好用。
 升级会员
升级会员 