张思成计量实验.docx
《张思成计量实验.docx》由会员分享,可在线阅读,更多相关《张思成计量实验.docx(12页珍藏版)》请在冰豆网上搜索。
张思成计量实验
张思成书上的
金融计量学作业
题一:
获得2001年之后中国月度CPI通货膨胀率,用AR模型预测2011年9月及之后的点估计值和区间预测结果(样本取2001年1月至2011年8月)
Step1:
从中国统计局网站找出2001年1月至2011年8月的居民消费价格指数(上年同月=100),在EViews中构建序列cpi,dcpi=(cpi-100)%.
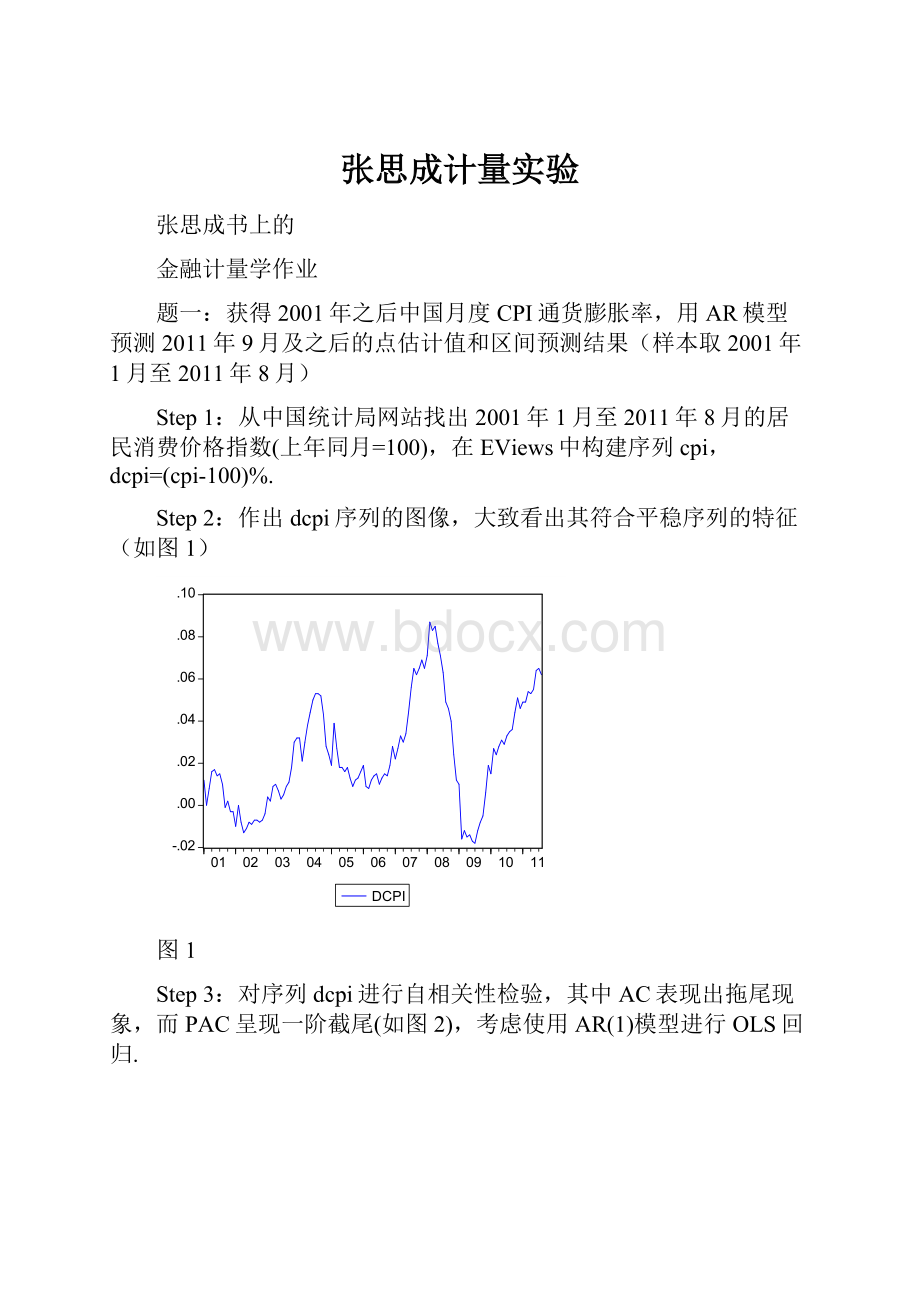
Step2:
作出dcpi序列的图像,大致看出其符合平稳序列的特征(如图1)
图1
Step3:
对序列dcpi进行自相关性检验,其中AC表现出拖尾现象,而PAC呈现一阶截尾(如图2),考虑使用AR
(1)模型进行OLS回归.
Step4:
程序窗口输入lsdcpicdcpi(-1),查看AR
(1)模型的回归情况
DependentVariable:
DCPI
Method:
LeastSquares
Date:
11/04/13Time:
22:
17
Sample(adjusted):
2001M022011M08
Includedobservations:
127afteradjustments
Variable
Coefficient
Std.Error
t-Statistic
Prob.
C
0.106733
0.083134
1.283866
0.2016
DCPI(-1)
0.971321
0.024204
40.13017
0
R-squared
0.927972
Meandependentvar
2.388189
AdjustedR-squared
0.927396
S.D.dependentvar
2.536859
S.E.ofregression
0.683562
Akaikeinfocriterion
2.092624
Sumsquaredresid
58.40713
Schwarzcriterion
2.137414
Loglikelihood
-130.8816
F-statistic
1610.431
Durbin-Watsonstat
1.673332
Prob(F-statistic)
0
从上表能够看出R-squared很接近1,dcpi的t统计量很显著,AIC和SIC都不大,于是可以决定用AR
(1)进行预测。
Step5:
以2001年1月至2011年8月的数据作为样本,预测2011年9月至2012年7月的dcpi数值。
可得出图3。
图3
于是做出了2011年9月至2012年8月的dcpi预测图。
题二:
以2001年1月至2011年8月的股票收益率为样本,利用AR模型对2011年9月以及以后的股票收益率进行预测,并比较不同模型结果的准确度。
Step1:
首先在wind资讯上查到了2001年1月至2012年11月的以月度为频率的股票指数,生成序列index。
以该序列为基础,生成股票收益率的序列i,公式为seriesi=((index-index(-1))/index(-1))*100。
并画出收益率的graph以及自相关图。
Step2:
按题意用AR模型进行预测,其中样本为2001年1月至2011年8月,之后的数据作为对比,看预测值与实际值得差距。
Step3:
先用AR
(2)进行预测。
输入:
ici(-1)i(-2)看拟合程度
拟合度并不好,但先用其生成预测序列if1.
Step3:
用AR(3)进行预测,类似Step2的步骤,得到if2.同理获取AR(4),AR(5)的预测序列if3,if4.其拟合度都不高。
将四个预测序列和实际序列放在同一张图上看出用AR(5)预测的值较其他更接近实际值。
下面是分别用ar(3)ar(4)ar(5)拟合的结果。
这里i(-1)和i(-3)的系数几乎为0,而且t统计量不显著
ar(3)的结果
ar(4)的结果
ar(5)的结果
相对于ar
(2)ar(3)ar(4),ar(5)的预测稍微准确,相信将阶数增加到很大的时候可以比较接近真实值。
题三:
用ADF单位根检验法检验1978至2000年的GDP序列,并用ARIMA模型预测2001年和2002年的GDP
Step1:
在中经网数据库找出1978至2002年的gdp数据,其中1978年至2000年的数据作为样本,作出graph以及自相关图
可以看出gdp序列可能是非平稳的。
Step2:
对该序列进行ADF单位根检验,以确定gdp序列的平稳性。
假设是情况3,即既带有t趋势项又带有截距项。
在选项中选择Trendandintercept。
可得:
T统计量的值远大于检验水平1%、5%、10%的的临界值。
因此拒绝原假设,即可认为序列gdp是非平稳的。
其中gdp一阶差分,gdp二阶差分的系数,以及trend的系数都比较显著,拒绝均为0的原假设。
即可认为该序列属于第三种情况(既含趋势项又含截距项)
Step3:
下面确定单位根的个数,由于gdp的一阶滞后项和二阶滞后项都有系数。
直接用二阶差分的ADF单位根来检验。
得出;
T统计量大于5%的临界值,因此可以接受原假设。
并且trend项的系数不显著,可以认为gdp的二阶差分是平稳的,即gdp序列是二阶单整序列。
Step4:
用ARIMA(p,d,q)模型来估计该序列,目前可以确定d=2。
对gdp的二阶差分进行自相关图分析
ACF和PACF都没有出现截尾,ACF滞后1阶,4阶处超出置信区间,PACF在1、2、4、5、6、7都超出。
MA应该是低阶的,AR取2(滞后2阶后变的很小)
考虑用ARMA(2,1)和ARMA(2,2)来拟合经过2阶差分的GDP序列。
代码为d(log(gdp),1,2)car
(2)ar
(1)ma
(1)
其中ARIMA(2,2,1)的结果为:
ARMA(2,2,2)的结果为:
看来ARMA(2.2)预测的跟真实值更接近。
将两个预测结果和真实值放在一个图中
实际值
ARIMA(2,2,1)
ARIMA(2,2,2)
2001
109655.17
108705.0586
110776.4696
2002
120332.69
119385.501
123234.2277
ARIMA(2,2,1)的预测值更接近实际值
 升级会员
升级会员 