哈希实验报告Word格式文档下载.docx
《哈希实验报告Word格式文档下载.docx》由会员分享,可在线阅读,更多相关《哈希实验报告Word格式文档下载.docx(21页珍藏版)》请在冰豆网上搜索。
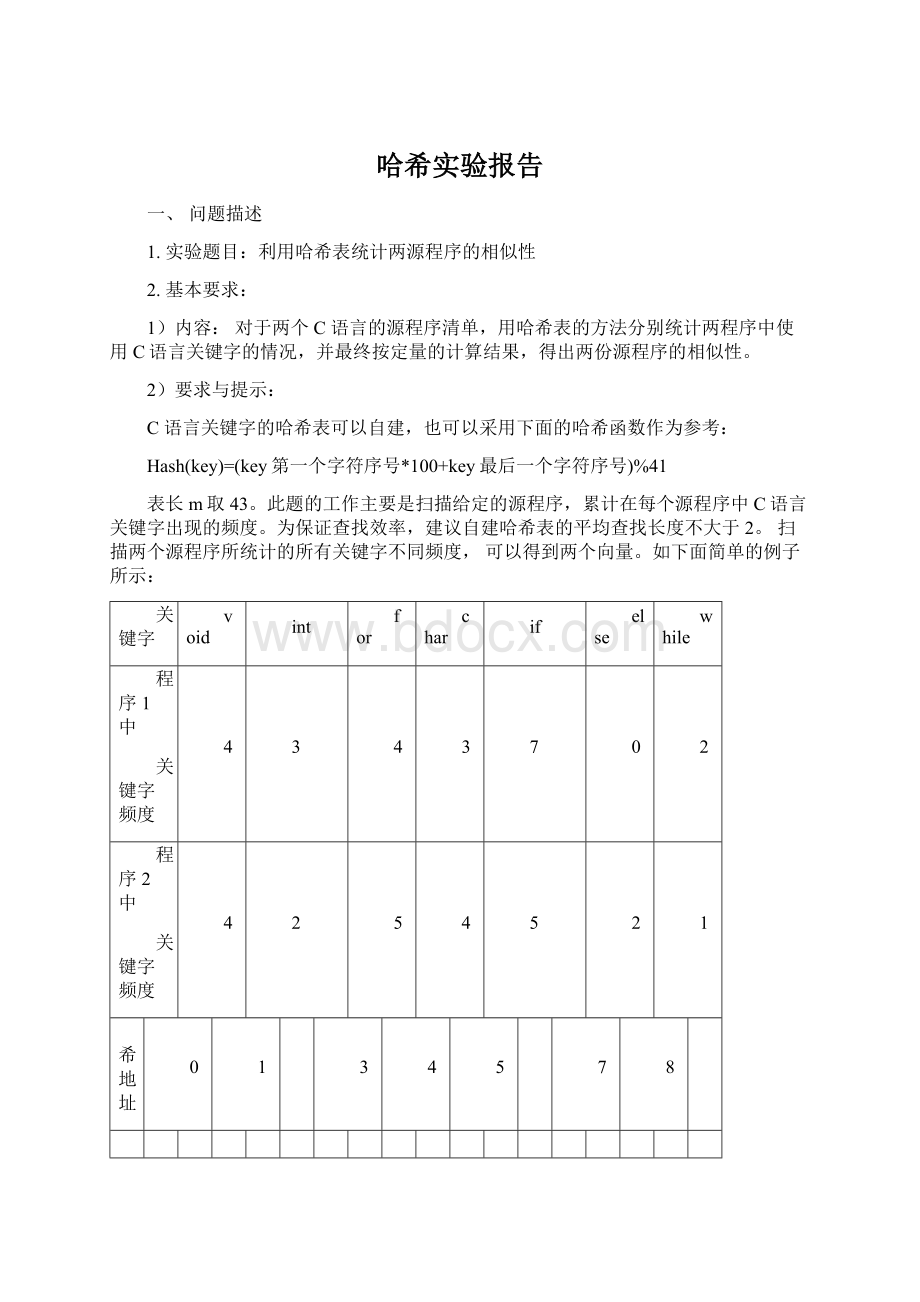
X2=(4205405201)T
一般情况下,可以通过计算向量Xi和Xj的相似值来判断对应两个程序的相似性,相似值的判别函数计算公式为:
其中,
。
S(Xi,Xj)的值介于[0,1]之间,也称广义余弦,即S(Xi,Xj)=COSθ。
Xi=Xj时,显见S(Xi,Xj)=1,θ=0;
XiXj差别很大时,S(Xi,Xj)接近0,θ接近π/2。
如X1=(10)T,X2=(01)T,则S(Xi,Xj)=0,θ=π/2。
当S值接近1的时候,为避免误判相似性(可能是夹角很小,模值很大的向量),应当再次计算之间的“几何距离”D(Xi,Xk)。
其计算公式为:
最后的相似性判别计算可分两步完成:
第一步用式(3-1)计算S,把接近1的保留,抛弃接近0的情况(把不相似的排除);
第二步对保留下来的特征向量,再用式(3-2)计算D,如D值也比较小,说明两者对应的程序确实可能相似(慎重肯定相似的)。
S和D的值达到什么门限才能决定取舍?
需要积累经验,选择合适的阈值。
3)测试数据:
做几个编译和运行都无误的C程序,程序之间有相近的和差别大的,用上述方
法求S,并对比差异程度。
二、需求分析
1.本程序能够打印根据关键字建立的哈希表及利用该表统计的C语言源程序关键字使用情况,得出源程序的相似性。
2.将关键字输入key.txt中,关键字均为char型,以空格分开,将要比较的源程序存入不同文本文档中,运行时按提示输入源程序个数和相应的文档名称,若输入多个源程序,比较时输入相应的源程序序号(序号为输入源程序的顺序)。
3.输出建立的哈希表,按哈希表统计的源程序关键字使用情况,所比较的两个程序间的相似度以及向量的几何距离。
三、概要设计
为了实现上述功能,需要哈希表抽象数据类型。
哈希表抽象数据类型定义:
ADTHashList{
数据对象:
D是相同类型元素构成的结合。
数据关系:
R={集合内的元素之间是松散关系}
基本操作:
intDimension(LinkHashListHT);
//求哈希表元素总个数
intHashFunc(char*e);
//哈希函数
voidInitHashList(LinkHashList&
HT,intm,FILE*fp);
//创建哈希表
voidInsertHT(LinkHashList&
HT,char*e);
//插入元素
LNode*SearchHT(LinkHashListHT,char*e);
//查找元素
voidHashBuild(FILE*fp,LinkHashList&
HT);
//统计源程序每个关键字频度
voidHashclear(LinkHashList&
HT,intm);
//将哈希表每个关键字频度置零
voidTraverseHT(LinkHashListHT);
//输出哈希表
}ADTHashList
5.本程序保护模块:
主程序模块
哈希表单元模块:
实现哈希表抽象数据类型
调用关系:
主程序模块->
哈希表单元模块
四、详细设计
1.结点类型和结点指针类型:
typedefstructLNode{
chardata[10];
intaccount;
structLNode*next;
}LNode,**ppLNode;
typedefstruct{
ppLNodehead;
intlength;
}LinkHashList;
2.哈希表的实现
求哈希表元素总个数
intDimension(LinkHashListHT)
{
intd,count=0;
LNode*p;
for(d=0;
d<
43;
d++)
{
p=HT.head[d];
while(p){p=p->
next;
count++;
}
}
returncount;
哈希函数
intHashFunc(char*e)
inti;
for(i=0;
i<
10;
i++)
if(e[i]=='
\0'
)break;
return((e[0]*100+e[i-1])%41);
HT,char*e)
intd=HashFunc(e);
LNode*p=newLNode;
strcpy(p->
data,e);
p->
account=0;
next=HT.head[d];
HT.head[d]=p;
LNode*SearchHT(LinkHashListHT,char*e)
LNode*p=HT.head[d];
while(p&
&
strcmp(p->
data,e)!
=0)p=p->
returnp;
//创建哈希表
HT,intm,FILE*fp)
{inti,d;
charstr[10];
HT.head=newLNode*[m];
HT.length=m;
m;
HT.head[i]=NULL;
LNode*p=newLNode;
strcpy(p->
data,"
\0"
);
p->
next=HT.head[i];
HT.head[i]=p;
charch=fgetc(fp);
while(ch!
=EOF)
if(ch=='
'
ch!
=EOF)
do
{ch=fgetc(fp);
}while(ch=='
i=0;
='
{
str[i++]=ch;
ch=fgetc(fp);
}
str[i]='
;
InsertHT(HT,str);
统计源程序每个关键字频度
HT)
inti,d;
while((ch<
97||ch>
122)&
i=0;
if(ch>
96&
ch<
123)
while(ch>
{
}
LNode*p=SearchHT(HT,str);
if(p)p->
account++;
ch=fgetc(fp);
将哈希表每个关键字频度置零
HT,intm)
{LNode*p;
{p=HT.head[i];
while(p)
{p->
p=p->
//遍历哈希表
voidTraverseHT(LinkHashListHT)
p=HT.head[0]->
cout<
<
"
["
0<
]"
while(p->
next){
data<
->
account;
endl;
for(inti=1;
HT.length;
i++){
p=HT.head[i];
}//for
3.函数调用关系图
五、调试分析
1.hashbuild函数中,在文件中搜索字符时,采用的方法是比较ASC码的值,但是总是执行后无法继续,后来发现是ch在最后被赋值为EOF而没有经外层循环的判断跳出,因而在内层循环中也添加了一个判断。
2.原先利用哈希表对源程序关键字计数时,没有考虑在统计完一个程序后,要对哈希表计数的量重新置零,得到的结果总是不对,后来添加了hashclear函数,得到了正确的结果。
3.输出统计结果时,注意到哈希表的插入是对head前插,所以每个单元最后一个节点没有赋关键字符值,还是初始值零,输出时跳过,但是后面将统计结果赋值给数组时,这些值也赋值进去了,因为全部是零,所以不影响后面的相似度判断,只是增加了向量的维度而已。
4.最后比较相似度是,取S值为0.9,D值为10。
若有更合理的阈值,要对它们进行修正。
5.复杂度分析
函数时间复杂度空间复杂度
DimensionO(n+d)O
(1)
InitHashListO(n+d)O(n+d)
HashBuildO(n+d)O
(1)
HashclearO(n+d)O
(1)
CosineO(n+d)O
(1)
DistanceO(n+d)O
(1)
六、使用说明
程序运行后根据提示输入所要进行的操作,输入关键字存储文件名,源程序存储文件名。
程序将打印建立的哈希表,对源程序的统计结果,相似度和几何距离。
七、调试结果
使用joseph,parking两个源程序用上述方法求S,D,并对比差异程度。
建立的哈希表
joseph.txt源程序:
intMinEdge(floatlow[],intVexnum)
inti,j,m,flag=0;
floatk;
for(i=0;
Vexnum;
for(j=0;
j<
j++)
if(low[i]==0&
low[j]!
=0)
k=low[j];
m=j;
flag=1;
break;
}
if(flag)break;
=0&
k>
low[j])
returnm;
统计结果
parking.txt源程序
inti01,j,k;
i=1000;
floatlowcost[MAX_VEX_NUM];
ArcNode*p;
G.VexNum-1;
{p=G.vertices[v0].firstarc;
while(p)
j=p->
adjvex;
lowcost[j]=p->
weight;
adjvex[j]=v0;
nextarc;
if(!
VexJudge(G,v0,i))lowcost[i]=1000;
比较结果
八、附录
源代码
Hash.h
doubleCosine(int(*w)[76],inta,intb,intm);
doubleDistance(int(*w)[76],inta,intb,intm);
Hash.cpp
#include<
stdio.h>
stdlib.h>
iostream.h>
#include<
string.h>
math.h>
#include"
hash.h"
intDimension(LinkHashListHT)//求哈希表中元素总个数
HT,char*e)//插入元素
LNode*SearchHT(LinkHashListHT,char*e)//查找元素
HT,intm,FILE*fp)//创建哈希表
//从文件中读取关键字
HT)//对文件中关键字进行统计
HT,intm)//统计量置零
doubleCosine(int(*w)[76],inta,intb,intm)//计算S
inti,s=0,v=0,u=0;
doublecos=0;
s=s+(*(*(w+a)+i))*(*(*(w+b)+i));
u=u+(*(*(w+a)+i))*(*(*(w+a)+i));
v=v+(*(*(w+b)+i))*(*(*(w+b)+i));
cos=s/(sqrt(v)*sqrt(u));
returncos;
doubleDistance(int(*w)[76],inta,intb,intm)//计算D
inti,s=0;
s=s+(*(*(w+a)+i)-*(*(w+b)+i))*(*(*(w+a)+i)-*(*(w+b)+i));
returnsqrt(s);
voidTraverseHT(LinkHashListHT)//遍历哈希表
程序相似性比较.cpp
voidmain()
intn,i,j,p,q,dim,k=0;
doubles,d;
charkey[20],source[20],choice;
intweight[10][76];
FILE*fp,*fp1;
LinkHashListHHT;
LNode*node;
cout<
请输入关键字存储文件名:
cin>
>
key;
if((fp=fopen(key,"
r"
))==NULL)
printf("
cantopenfile"
exit
(1);
InitHashList(HHT,43,fp);
TraverseHT(HHT);
请输入源程序个数:
n;
cout<
请输入源程序存储文件名:
cin>
source;
if((fp1=fopen(source,"
cantopenthefile"
}
HashBuild(fp1,HHT);
dim=Dimension(HHT);
printf("
用哈希表统计结果为:
\n"
for(j=0;
dim&
k<
)//把统计结果赋值给数组,构造向量
{node=HHT.head[k++];
while(node)
weight[i][j]=node->
node=node->
j++;
k=0;
Hashclear(HHT,43);
是否比较(Y\N):
choice;
while(choice=='
Y'
)
cout<
请输入源程序序号(按照输入顺序):
//编号i,向量在数组中存储与第i行
p>
q;
s=Cosine(weight,p-1,q-1,dim);
相似度S="
s;
if(s>
0.9)
d=Distance(weight,p-1,q-1,dim);
cout<
几何距离D="
d;
if(d<
10)cout<
两个程序相似\n"
elsecout<
两
 升级会员
升级会员 