逻辑回归模型分析见解Word文档下载推荐.docx
《逻辑回归模型分析见解Word文档下载推荐.docx》由会员分享,可在线阅读,更多相关《逻辑回归模型分析见解Word文档下载推荐.docx(9页珍藏版)》请在冰豆网上搜索。
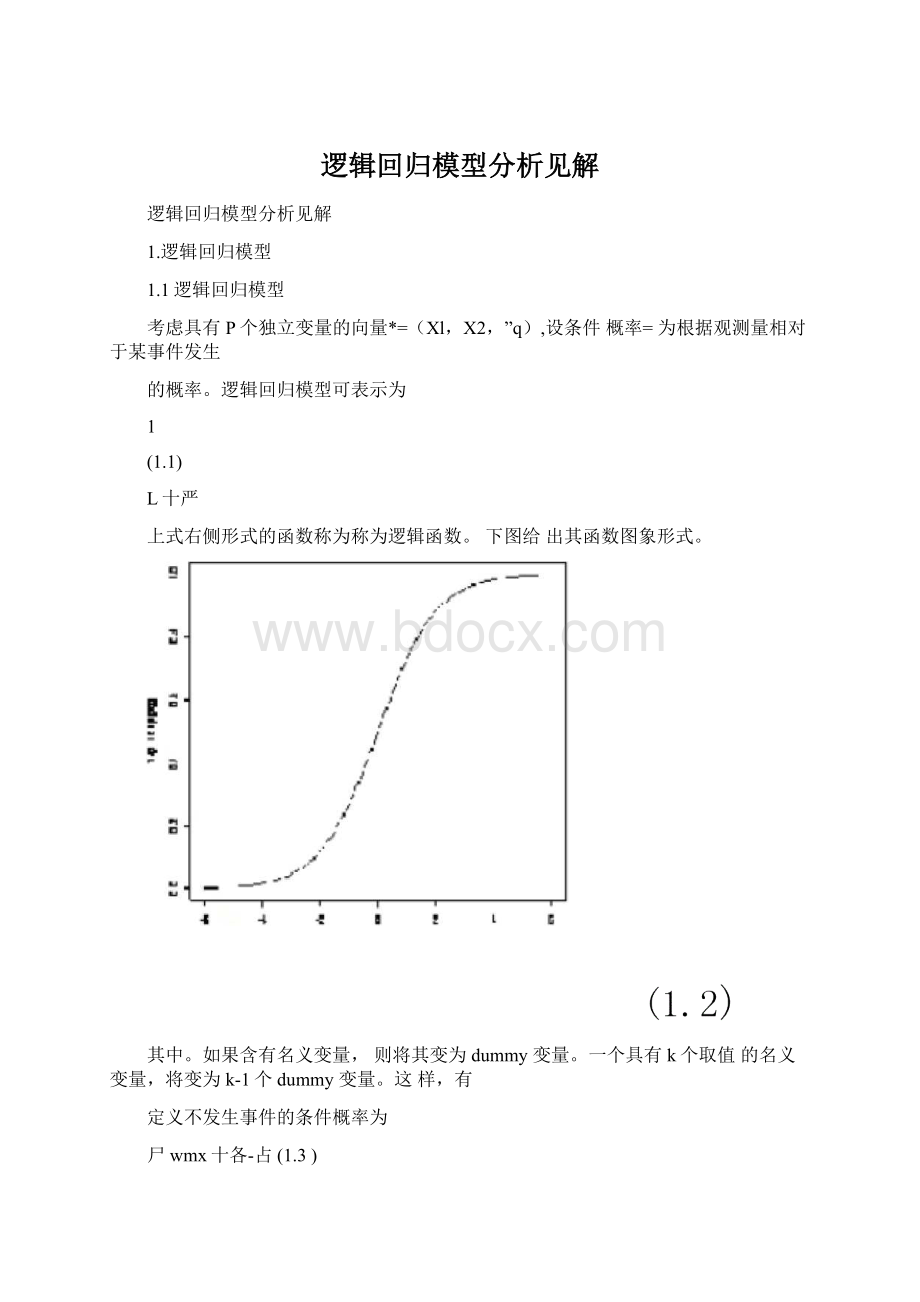
0。
对odds取对数,即得到线性函数,
1.2极大似然函数
假设有n个观测样本,观测值分别为心,7,设丹=P3=X)为给定条件下得到丹=1的概率。
在同样条件下得到刃=°
的条件概率为®
=0|^=1・p’。
于是,得到一个观测值的概率为戸盼八心严(1.6)
因为各项观测独立,所以它们的联合分布可以表示为各边际分布的乘积。
-(1.7)
上式称为n个观测的似然函数。
我们的目标是能够求出使这一似然函数的值最大的参数估计。
于是,最大似然估计的关键就是求出参数,使上式取得最大值。
对上述函数求对数山应・*的・召仙恥区;
]丨门丫」訓:
叩丄】(i8)
上式称为对数似然函数。
为了估计能使£
(旳取得
最大的参数的值。
对此函数求导,得到p+1个似然方程。
纠片-v相严纠#_]新.站卄”和丸(i9)
圣屮.『;
-*几-百工一fJi'
j=12p
上式称为似然方程。
为了解上述非线性方程,应用牛顿一拉斐森(Newton-Raphson)方法
进行迭代求解。
亦占二址(1-隔)
兰丝二-S耳赳兀(1-花)阴阴处心“(1.10)
如果写成矩阵形式,以H表示Hessian矩阵,X表示
U-
1和
1础
■H
…W…知
■■
■e
耳
Va-码
■
«
H=。
再令
_1心
…
(1.12)
则
(注:
前一个
令
矩阵需转置),即似然方程的矩阵形式。
得牛顿迭代法的形式为
氐八验-却切(1.13)注意到上式中矩阵H为对称正定的,求解「「丁即为求解线性方程HX=U中的矩阵X。
对H进行
cholesky分解。
最大似然估计的渐近方差(asymptoticvarianee)和协方差(covarianee)可以由信
息矩阵(informationmatrix)的逆矩阵估计出来。
而信息矩阵实际上是|:
-二阶导数的负值,表示为「“二。
估计值的方差和协方差表示
为八」,也就是说,估计值厂的方差为矩阵I的逆矩阵的对角线上的值,而估计值匚和“的协
方差为除了对角线以外的值。
然而在多数情况,我们将使用估计值再的标准方差,表示为
2
甜(.巧)=(var(屁)户,forj=0,1,2,…,p(1.14)
2.显著性检验
下面讨论在逻辑回归模型中自变量氐是否与反
应变量显著相关的显著性检验。
零假设比:
憑=0(表示自变量〃对事件发生可能性无影响作用)。
如果零假设被拒绝,说明事件发生可能性依赖于比的变化。
2.1Waldtest
对回归系数进行显著性检验时,通常使用Wald检验,其公式为
阳三同/述◎护(21)
其中,磁他)为色的标准误差。
这个单变量Wald统计量服从自由度等于1的,分布。
如果需要检验假设=:
「—,=0,计算统计量
(2.2)
其中,为去掉「所在的行和列的估计值,相应地,八为去掉•」所在的行和列的标准误差。
这里,Wald统计量服从自由度等于p的沪分布。
如果将上式写成矩阵形式,有呼=&
刖9简(為0T(。
血(2.3)
矩阵Q是第一列为零的一常数矩阵。
例如,如果e=[°
1°
检验4=A=o,贝则2。
1」。
然而当回归系数的绝对值很大时,这一系数的估计标准误就会膨胀,于是会导致Wald统
计值变得很小,以致第二类错误的概率增加。
也就是说,在实际上会导致应该拒绝零假设时却未能拒绝。
所以当发现回归系数的绝对值很大时,就不再用Wald统计值来检验零假设,而应该使用似然比检验来代替。
2.2似然比(Likelihoodratiotest)检验
在一个模型里面,含有变量西与不含变量再
的对数似然值乘以-2的结果之差,服从尸分布这一检验统计量称为似然比(likelihoodratio),用式子表示为
r—不纸似卷
G-沁含有训然)(24)
计算似然值米用公式(1.8)。
倘若需要检验假设…:
:
=0,计算统计
量
U-孑二貲LsAd厂虚UI■丸1-4(2.5)
上式中,冷表示必=0的观测值的个数,而灼表示岛=1的观测值的个数,那么n就表示所有观测值的个数了。
实际上,上式的右端的右半部分[丛如+讣如・汕(”)]表示只含有咸的似然值。
统计量G服从自由度为p的,分布
2.3Score检验
(2.6)上式中,幕」表示在心=0下的对数似然函数
(1.9)的一价偏导数值,而:
表示在:
=0
下的对数似然函数(1.9)的二价偏导数值。
Score统计量服从自由度等于1的:
:
分布。
2.4模型拟合信息
在零假设凤:
以=0下,设参数的估计值为爲,即对应的煤=0。
计算Score统计量的公式为5颅『厂'
(如刃隔小
模型建立后,考虑和比较模型的拟合程度有三个度量值可作为拟合的判断根据。
(1)-2LogLikelihood
W…(2.7)
(2)Akaike信息准则(AkaikeInformationCriterion,简写为AIC)
AlC=-2LagL^-2(K^S)(28)
其中K为模型中自变量的数目,S为反应变量类别总数减1,对于逻辑回归有S=2-1=1。
-2LogL的值域为0至,其值越小说明拟合越
好。
当模型中的参数数量越大时,似然值也就越大,-2LogL就变小。
因此,将2(K+S)加到
AIC公式中以抵销参数数量产生的影响。
在其它条件不变的情况下,较小的AIC值表示拟合
模型较好。
(3)Schwarz准则
这一指标根据自变量数目和观测数量对-2LogL值进行另外一种调整。
SC指标的定义
&
7=-2比就+2〔疋+£
严In(町(29)
其中ln(n)是观测数量的自然对数。
这一指标只能用于比较对同一数据所设的不同模型。
在其它条件相同时,一个模型的AIC或SC值越小说明模型拟合越好。
3.回归系数解释
3.1发生比
(3.1)
⑵二分类自变量的发生比率。
变量的取值只能为0或1,称为dummyvariable。
当%取值为1,对于取值为0的发生比率为
血擀■…W泡4
*(3.2)
亦即对应系数的幂。
⑶分类自变量的发生比率。
如果一个分类变量包括m个类别,需要建立的dummyvariable的个数为m-1,所省略的那个类别称作参照类(reference
category)。
设dummyvariable为心,其
系数为钱,对于参照类,其发生比率为詐。
3.2逻辑回归系数的置信区间
对于置信度1"
,参数爆的100%(1"
)
的置信区间为
卫牡(3.3)
z
上式中,扌为与正态曲线下的临界Z值
(criticalvalue),%为系数估计&
的标准误差,T’和T’两值便分别是置信区间
的下限和上限。
当样本较大时,a=0.05水平的系数&
的95%置信区间为屁±
1,94型?
入(34)
4.变量选择
4.1前向选择(forwardselection):
在截距
模型的基础上,将符合所定显著水平的自变量一次一个地加入模型。
具体选择程序如下
(1)常数(即截距)进入模型。
(2)根据公式(2.6)计算待进入模型变量的Score检验值,并得到相应的P值。
(3)找出最小的p值,如果此p值小于显著性水平捡,则此变量进入模型。
如果此变量是某个名义变量的单面化(dummy)变量,则此名义变量的其它单面化变理同时也进入模型。
不
然,表明没有变量可被选入模型。
选择过程终止。
(4)回到
(2)继续下一次选择。
4.2后向选择(backwardselection):
在
模型包括所有候选变量的基础上,将不符合保留要求显著水平的自变量一次一个地删除。
(1)所有变量进入模型。
(2)根据公式(2.1)计算所有变量的Wald检验值,并得到相应的p值。
(3)找出其中最大的p值,如果此P值大于显著性水平j,则此变量被剔除。
对于某个名义变量的单面化变量,其最小p值大于显著性水平•,则此名义变量的其它单面化变量也被删除。
不然,表明没有变量可被剔除,选择过程终止
⑷回到⑵进行下一轮剔除
4.3逐步回归(stepwiseselection)
⑴基本思想:
逐个引入自变量。
每次引入对Y影响最显著的自变量,并对方程中的老变量逐个进行检验,把变为不显著的变量逐个从方程中剔除掉,最终得到的方程中既不漏掉对Y影响显著的变量,又不包含对Y影响不显著的变量。
(2)
筛选的步骤:
首先给出引入变量的显著性水平塔和剔除变量的显著性水平%,然后按下图筛选变量。
(3)逐步筛选法的基本步骤
逐步筛选变量的过程主要包括两个基本步骤:
是从不在方程中的变量考虑引入新变量的步骤;
二是从回归方程中考虑剔除不显著变量的步骤。
假设有p个需要考虑引入回归方程的自变量•
1设仅有截距项的最大似然估计值为;
。
对p个自变量每个分别计算Score检验值,
设有最小p值的变量为心,且有兀=皿打,对于单面化(dummy)变量,也如此。
若》“7”,则此变量进入模型,不然停止。
如果此变量是名义变量单面化(dummy)的变量,则此名义变量
的其它单面化变量也进入模型。
其中签为引入变量的显著性水平。
2为了确定当变量%在模型中时其它p-1个变量也是否重要,将gm,..”知分别与%进行拟合。
对p-1个变量分别计算Score检验值,其p值设为刊。
设有最小p值的变量为%,且有&
=叫).若阳<陷,则进入下一步,不然停止。
对于单面化变量,其方式如同上步。
3此步开始于模型中已含有变量%与%。
注意到有可能在变量%被引入后,变量沧不再重要。
本步包括向后删除。
根据(2.1)计算变量心与花的Wald检验值,和相应的p值。
设心为具有最大p值的变量,即*=max
(二)厂・:
.如果此p值大于“,则此变量从模型中被删除,不然停止。
对于名义变量,如果某个单面化变量的最小p值大于"
,则此名义变量从模型中被删除。
4如此进行下去,每当向前选择一个变量进入后,都进行向后删除的检查。
循环终止的条件是:
所有的p个变量都进入模型中或者模型中的变量的p值小于%,不包含在模型中的变量的p值大于%。
或者某个变量进入模型后,在下一步又被删除,形成循环。
 升级会员
升级会员 