BP算法程序实现Word格式.docx
《BP算法程序实现Word格式.docx》由会员分享,可在线阅读,更多相关《BP算法程序实现Word格式.docx(15页珍藏版)》请在冰豆网上搜索。
BP学习算法也可写成向量形式:
对输出层
W
[5oyT]T
式中
y
[y0y1y2
yjym]T,5o
ooooT[12kl]
对于隐层
V
[5yXT]T
X
[xox1x2
xixn]T,5y
yyyyT[12jm]
看出,BP算法中,各层权值调整公式形式上都是一样的,均由3个因素决定,学习率n,本层输出的误差信号S及本层输入信号丫(或X)。
其中输出层误差信号同网络的期望输出与实际输出之差有关,直接反映了输出误差,而各隐层的误差信号与前面各层的误差信号都有关,是从输出层开始逐层反传过来的。
反传过程可以简述为:
d与o比较得到输出层误差信号5°
-计算输出层权值调整量厶W*通过隐层各节点反传一计算各隐层权值的调整量△V.
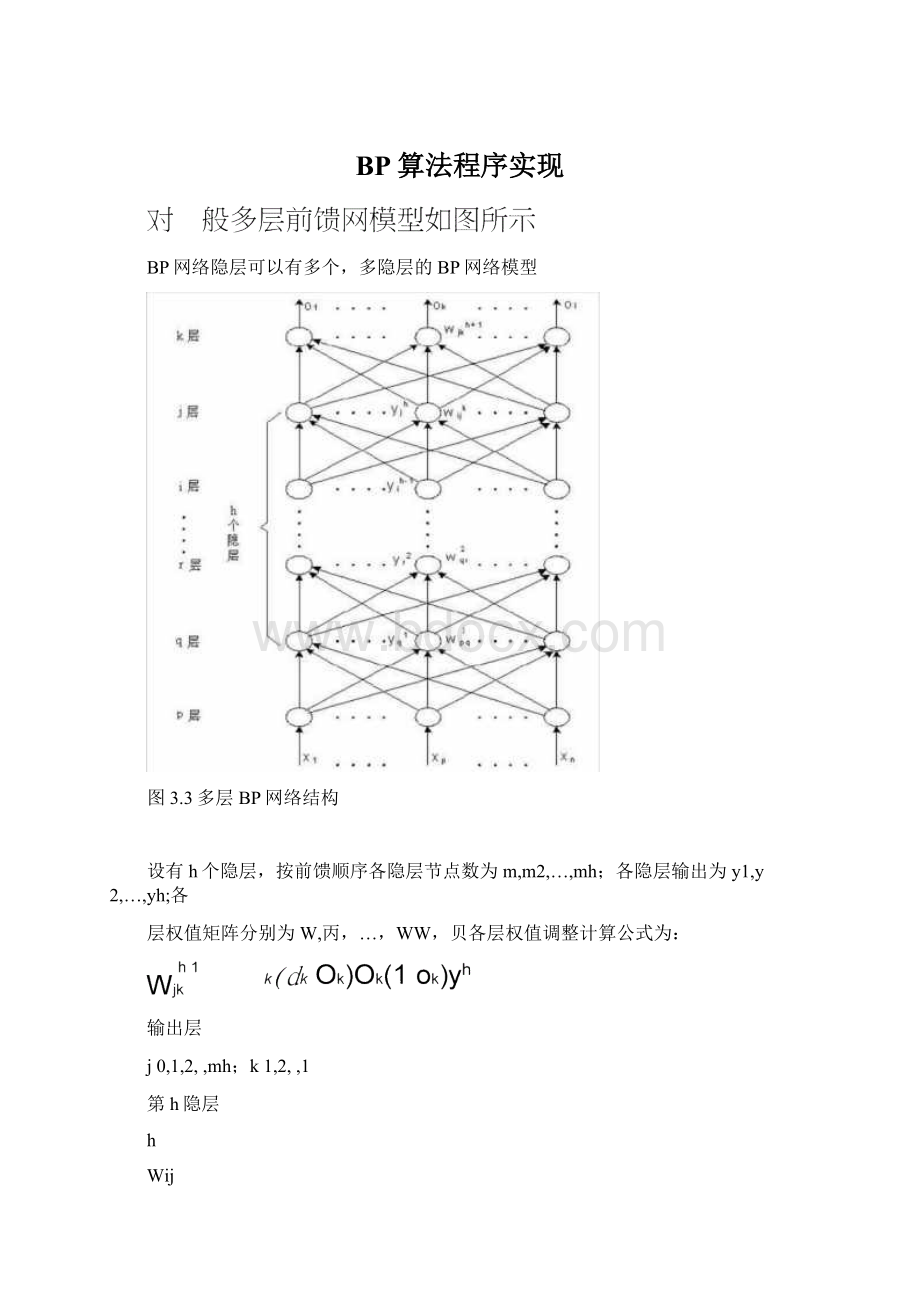
例采用BP网络映射下图曲线规律。
设计BP网络结构如下:
单隐层1—4—1BP网络
权系数随机选取为:
W2=0.2,wi3=0.3,wm=0.4,w15=0.5,
w
26=0.5,W36=0.2,W46=0.1,W56=0.40
取学习率n=1
按图中曲线确定学习样本数据如下表(每0.05取一学习数据,共80对)
x(输入信号)
y(教师信号)
•••
0.0000
0.5000
•…
3.0000
1.0000
…
4.0000
按表中数据开始进行学习:
第一次学习,输入x;
=0.0000(1节点第1次学习),d60.5000,计算2、3、4、5单
元状态netj:
1
netiw1ix1w1i?
0.00000.0000i=2,3,4,5
计算2、3、4、5各隐层单元输出yi(i=2,3,4,5)
y1f(neti)1/(1eneti)0.5
计算输出层单元6的状态值net6及输出值y:
0.5
t0.5
net6W6Yi0.50.20.10.40.6
y61/(1enet6)1/(1e0.6)0.6457
反推确定第二层权系数变化:
0y1(d1y;
)(1y6)0.6457(0.50.6457)(10.6457)0.0333
001rC▲L
Wi6Wi6i6yiI2,3,4,5
第一次反传修正的输出层权为:
0.4833
0.2
0.1833
1?
(0.0333)
0.1
0.0833
0.4
0.3833
反推第一层权系数修正:
10011\
1ii6Wi6yi(1yi)i2,3,4,5
011
W〔iW〔i11X1
Wi0.20.30.40.5T
第二次学习,x20.0500,d620.5250
2
netiw1ix1I2,3,4,5
y22
1/[1
e
(w12x12)]
e(0.20.0500)]e]
0.5025
y32
(w13x1)]
e(0.30.0500)]e]
0.5037
y4
(0.40.0500)
]0.5050
y520.5062
计算6单元状态net6:
T0.5037net6W6TYi0.48330.18330.08330.38330.5713
66i0.5050
0.5062
y62f(net6)1/(1e0.5713)0.6390
按表中数据依次训练学习,学习次数足够高时,可能达到学习目的,实现
权值成熟。
一般网络学习训练次数很高,采用手工计算是不可能的,需要用计算机程
序求解。
343BP算法的程序实现
前面推导的BP网络算法是BP算法基础,称标准BP算法。
目前神经网络的实现仍以软件
编程为主。
现以如图的三层BP网络为例,说明标准BP算法的编程步骤:
斯Xj**•Xf***X挖“
图3.2三层BP网络结构
0[。
1。
2Ok。
1]输出层输出向量;
V[V1V2VjVm]――输入层到隐层间的权值矩阵;
Vj—隐层第j个神经元对应的权列向量;
wWWWkW1]——隐层到输出层间的权值矩阵;
Wk——输出层第k个神经元对应的权列向量;
d=[did2dkdJT――网络期望输出向量。
标准BP算法的程序实现
网络正向传播阶段
误羞反向传播阶段
输人样本,计算各层输岀yi=/(血
o*-/(WjYkk=1*2*…,/
尹增It增1
N
计算误差
E=0"
・1
初始化V・W计数器q=1」=】
EP=]试¥
(以木节二层BP网络为例)
il薛齐13滾差信号
釁=(山-叩)(1-0()o*TA=1*2,…“
t
町=(另晔j)门-J=1Z…皿
调幅各层权憤:
<
E
初始化V.w*n.E.P.Enihi计数器g二1,p二1
输入样本,计算各层输岀
yi=f(v]x).j=1,2,…皿心=/(w]Y).k-1.2,…J
wW■权值矩阵初始化为随机矩阵:
巴训练样木对总数;
q■训练次数记数器;
p•样本模式记数器:
几一学习率,0~1小数帛E•误差变量*初值取0;
Emin-网络训练精度,止小数。
用牛沉样木X”川
对向量数组X、dx计綫◎中各
分出
EP=
-of)2
计算网络输出谋差.设仃P对训练样本.
网络对应不同样不的i吴差庄
•H询实际应用屮冇两种权值调整方法。
•上述标准BP算法屮,每输入一个样本,都要回传误差并调整权值,亦称单样本训练,只针对每个样本产生的误差进行调整,难免顾此失彼,实践表明,使整个训练次数增加,导致收敛速度过慢。
•另一种方法是在所右样木输入后,计算网络的总误差Kp
1pt
E萨第若族-。
"
然肩根据总误差环计盲名层矗误差信号并调整权值,这种累积误差的批处理方式称为批(B;
di)训练或周期(epoch)训练口批训练遵循了以减小全局误差为目标的原则,因而可以保证误差向减小方向变化*在样本数较多时,批训练比单样本训练吋的收敛速度快。
检查训纟*精度可用E=g,也可用E^:
幣人第」对样本
计TJ误蛙
e世~|~E2a-如)*
调塾各E我值
血
N
■*[£
==1」
站束
计算全部训练样本对的网络的总误差
用E计算各层误差信号
调整备层权值
结束
所冇样木对输入后,用网络的总误差调整权
值,记作一次权训练。
训练次数
程序可用一般咼级语言编写,如C等,但考虑方便,最好米用MATLA
E语言,特别是MATLAE环境中开发了工具箱(Toolboxes),其中神经网络开发工具(NeuralNetwork)提供很丰富的手段来完成EP等ANN设计与分析。
NeuralNetwork中提供了网络初始化函数用语构建基本网络,可自动生成权值,提供各种转移函数,提供各种训练或学习方法与手段,并实现仿真运算,监视网络训练误差等。
BP网络的训练,可概括归纳为输入已知数据,权值初始化,训练网络三大步。
用神经网络工具箱训练BP网络,权值初始化和训练网络都可调用BP网络
的相应工具函数。
调用时,用户只需要将这些工具函数视为黑箱,知道输入什么得到什么即可,不必考虑工具函数内部究竟如何。
EP网络的一些重要函数和功能(与版本有关)如表3.1o
表3.1BP网络的一些函数及功能
函数
功能
newff
创建一前馈EP网络(网络初始化函数)
Initff
前馈网络初始化(不超3层初始化函数)
purelin
线性传递(转移)函数
tansig
正切S型传递函数(双极性S函数)
logsig
对数正切S型传递函数(单极性S函数)
deltalin
purelin神经元的S函数
deltatan
tansig神经元的S函数
deltalog
logsig神经元的S函数
trainbp
EP算法训练函数(标准)
trainbpx
快速EP算法训练函数
trainlm
Levenberg-Marquardt训练函数
traingd
梯度下降训练函数
traingdm
梯度下降、动量训练函数
traingda
梯度下降、自适应学习率训练函数
traingdx
梯度下降、动量和自适应学习训练函数
simuff
前馈网络仿真函数(网络计算和测试网络)
errsurf
计算误差曲面函数
plotes
绘制误差曲面函数
ploterr
绘制网络误差相对训练步曲线
现行MATLAE工具中,神经元及网络模型表达略有差别基本神经元模型:
厂个输人矢量X=[x
(1)Tr权值矢量附j
=[w51),W(;
2人・rd(八刀],偏置最®
则该神经元净输入为输
传递函数(转移函数):
y=1/(1+es);
双曲正切S型传递函数tansig(s)即二tansigs,即y二(1-es)/
BP算法的
3.4.4多层前馈网络的主要能力多层前馈网络是目前应用最多的神经网络,这主要归结于基于多层前馈网络具有一些重要能力:
(1)非线性映射能力
2)泛化能力
3)容错能力
345误差曲面与BP算法的局限性
误差曲面与BP算法的局限性
多层前馈网络的谋差是各层权值和输入样木对的函数:
E=F(Xp,W,V,<
P)
特别是权空间的维数较高,误差卫是一个高维极英复杂的曲面一称误差曲面。
它有三个特点:
(1)
存在平坦区域
(2)全局极小点不唯一
(3)存在多个局部极小点
ErrorSurface
WeightW1BiasB
ErrorConlaur
Tl
在某些初始值的条件下,算法的結果会陷入局部极小点,而不能自拔,使训练无法收敛于给定误差。
误差曲面的多极值点的特点•使BP
 升级会员
升级会员 