学位论文学术不端行为检测系统使用说明.docx
《学位论文学术不端行为检测系统使用说明.docx》由会员分享,可在线阅读,更多相关《学位论文学术不端行为检测系统使用说明.docx(30页珍藏版)》请在冰豆网上搜索。
学位论文学术不端行为检测系统使用说明
学位论文学术不端行为检测系统
研制介绍与使用方法
第一章系统简介
1.1系统概述
学位论文学术不端行为检测系统(简称“TMLC”)以《中国学术文献网络出版总库》为全文比对数据库,实现了对抄袭与剽窃、伪造、篡改等学术不端行为的快速检测,可供用户检测学位论文,并支持用户自建比对库。
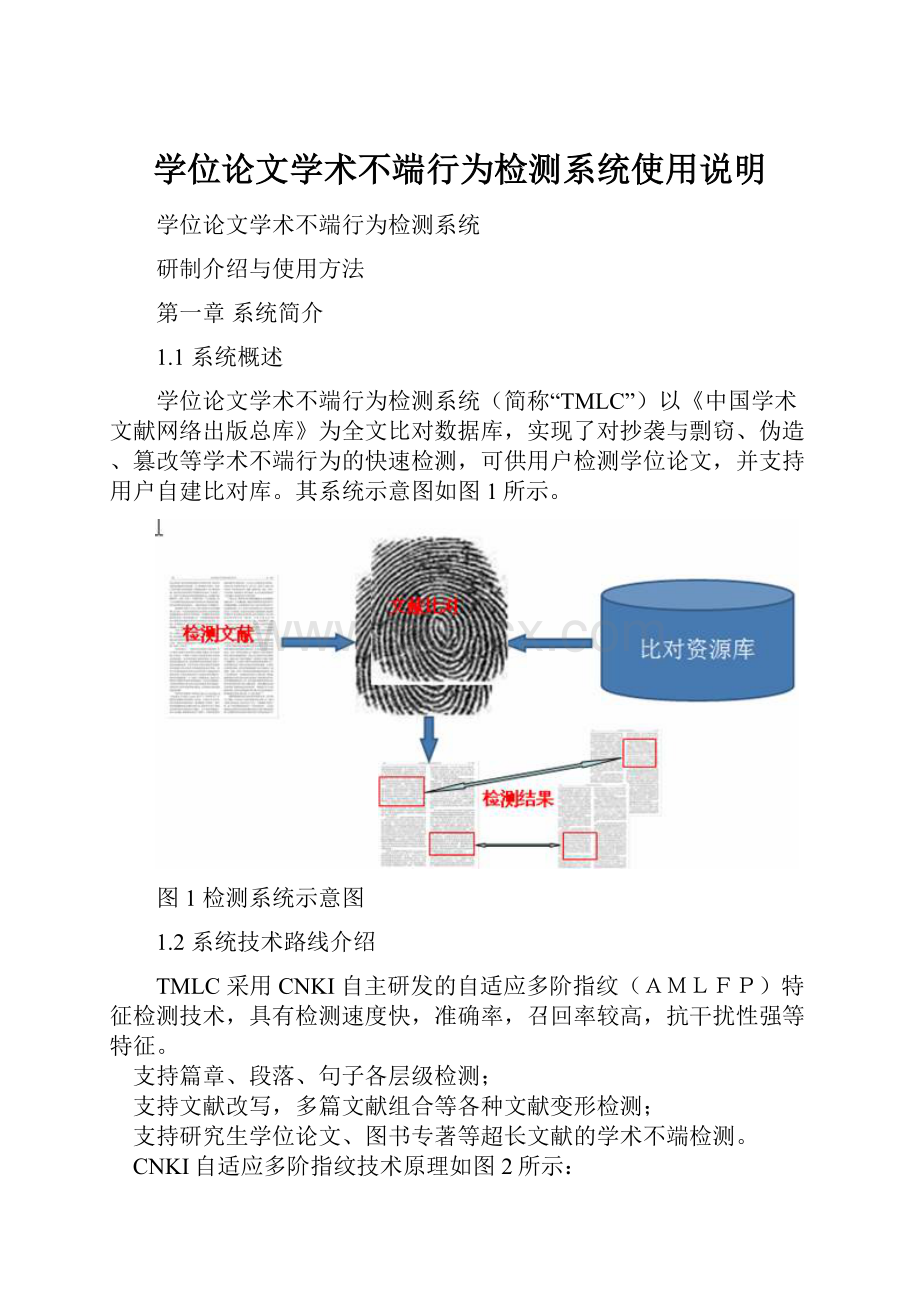
其系统示意图如图1所示。
图1检测系统示意图
1.2系统技术路线介绍
TMLC采用CNKI自主研发的自适应多阶指纹(AMLFP)特征检测技术,具有检测速度快,准确率,召回率较高,抗干扰性强等特征。
支持篇章、段落、句子各层级检测;
支持文献改写,多篇文献组合等各种文献变形检测;
支持研究生学位论文、图书专著等超长文献的学术不端检测。
CNKI自适应多阶指纹技术原理如图2所示:
图2CNKI自适应多阶指纹技术原理图
对任意一篇需要检测的文献,系统首先对其进行分层处理,按照篇章、段落、句子等层级分别创建指纹,而比对资源库中的比对文献,也采取同样技术创建指纹索引。
这样的分层多阶指纹结构,不仅可以满足我们对超长文献的快速检测,而且,因为我们的最小指纹粒度为句子,因此,也满足了系统对检准率和检全率的高要求。
原则上,只要检测文献与比对文献存在一个相同的句子,就能被检测系统发现。
1.3系统功能概述
系统主要功能包括:
已发表文献检测、论文检测、问题库查询、自建比对库管理等。
◆已发表文献检测:
指检测系统能够自动将属于用户的已正式发表的学位论文检索出来,并对每一篇已发表文献进行实时检测,快速给出检测结果。
◆论文检测:
主要实现论文实时在线检测功能。
◆问题库查询:
指用户可以将检测结果中确认有问题的文献放入到问题库,便于用户集中管理。
◆自建比对库:
指管理人员可以选择将检测文献放入个人比对库或者批量上传文献作为个人比对库,该个人比对库即可作为以后学术不端文献检测的比对数据库,该自建个人比对库完全属于用户,其他用户无权使用。
1.4系统目的
TMLC的目的是辅助各研究生培养单位对学位论文质量进行评估,为审查论文提供技术服务。
检测系统在对论文进行检测之后,生成检测报告,为判断论文性质提供相关依据。
第二章检测原理及方法
2.1支撑技术
CNKI拥有强大的技术研发队伍,目前已经拥有了具有国际或国内领先水准的全面的数字出版的相关技术,包括资源采集技术,文本数据库加工技术,文本数据库技术,数字资源版权保护技术,知识挖掘技术,自然语言处理技术、快速比对技术等。
在海量的全文数据的基础上实现快速准确的检测,上述技术是基本的保证。
2.2支撑资源
TMLC需要一个尽可能完备的全文数据比对资源库,而CNKI的《中国学术文献网络出版总库》则正好满足这一要求。
到目前为止,CNKI拥有学术期刊7000余种,期刊全文文献2480万篇,期刊期数和文献收录完整率都大于99.9%,文献量居国际国内同类产品之首;出版503家硕士学位点的72万篇优秀硕士学位论文,368家博士学位点的9.6万篇博士学位论文;1286家重要会议论文106万篇;515家重要报纸500多万篇;1376种重要年鉴787万篇;600多种工具书220多万条;学术引文索引数据600多万条;这些出版物做到平均日更新20000条记录;国家标准、专利、SPRINGER数据库也集成到CNKI网络出版平台中;另外,出版平台还集成整合出版了各类第三方数据库资源1020种。
在收录资源种类上,CNKI在国内具有明显优势,收录了期刊、学位论文、会议论文、报纸、年鉴、工具书、专利、外文文献、学术文献引文等与科学研究、学习相关的主要资源。
在资源收录数量上,CNKI明显优于同类产品,各个资源库收录年限长,期刊等主要资源库回溯到创刊。
在资源更新速度上,CNKI产品除了第三方合作的外文文献以外,其他资源都做到了日更新,单日更新数量大,这是推行产业化、标准化运作的结果。
2.3系统架构模式
2.3.1系统架构图
图3系统架构图
2.3.2系统示意图
检测系统提供整套的文献学术不端行为检测,系统服务器位于CNKI中心网站,用户将待检测的学位论文通过网络在线提交到中心网站服务器,服务器在检测完成后,自动将检测结果返回给用户。
整套系统架构为B/S结构,客户端不需要安装任何软件。
其系统示意如图4所示:
图4系统示意图
2.3.3系统流程图
图5系统核心流程图
2.4用户提供的资源
实现学位论文的学术不端检测,用户需要提供的资源包括:
1.论文全文内容
论文全文内容是检测论文是否存在学术不端行为的基础数据。
本检测系统是对提交的论文全文内容进行分析,在内容分析的基础上,生成各项检测指标。
因此,全文数据是系统所需要的必要资源。
2.元数据信息
元数据指论文相应的作者、作者单位、发表时间、支持基金项目等信息。
元数据是检测系统对学术不端类型进行判断所需的基础数据,为了更准确的便于系统做出预判,用户可以在提交检测文献的同时,一并提交文献的元数据信息。
特别提到的是:
在进行学位论文检测的时候,作者信息是非常必要的。
输入作者信息,在后续的检测过程中,系统能够自动根据作者信息区分比对资源中的文献是属于该作者已发表的文献,还是他人的文献,为用户快速甄别论文是否存在学术不端行为提供更直观的印象。
因为在学位论文中,引用自己以前发表过的文献是合理的。
注意:
元数据不是系统必需的数据,用户在使用检测系统的时候,可以选择不填写元数据。
但我们建议最好输入作者信息。
2.5检测结果内容
在对用户提交的检测文献检测之后,系统生成的检测结果包括:
1. 重合文字来源文献信息。
系统详细列出重合文字来源文献信息,这些文献都是真实存在,而且应是公开发表或得到发表确认的。
2. 比对信息。
检测文献和来源文献的详细比对信息,用户可以快速选择重合文字部分查阅。
3. 总检测指标。
该指标体系从多个角度对检测文献中的文字复制情况进行了概括性描述。
4. 子检测指标。
因为学位论文一般较长,因此,系统一般按章检索,并且每一章给出子检测指标,该检测指标从多个角度对该章内容的检测情况进行了详细描述。
5. 诊断类型。
系统根据指标参数以及其他元数据相关信息,自动给出一个预判的诊断类型,供审查人员参考。
6. 检测报告。
检测系统自动生成一个检测报告单,详细列出检测文献的学术不端行为检测情况,用户可以对该报告单进行修改,生成终审报告。
注意:
系统只对疑似存在学术不端行为的论文生成检测报告。
第三章检测指标体系
学位论文学术不端行为检测系统采用的指标体系分为两个部分:
3.1总检测指标
学位论文一般文献篇幅较大,字数多,硕士论文一般为3~5万字,博士论文则多达十多万字。
因此,为了让用户对整个学位论文有一个快速的概况了解,特制定了以下指标体系:
● 总重合字数(CCA)
● 总文字复制比(TTR)
● 总文字数(TCA)
● 疑似章节数(QCA)
● 总章节数(TCA)
● 首部重合文字数(HCCA)
● 尾部重合文字数(ECCA)
上述指标从整体情况描述了论文的检测情况,便于用户快速了解该论文总的检测概况。
下面对上述指标分别进行说明。
3.1.1总重合字数(CCA)
学位论文一般篇幅大,少则3~5万字,多则十多万字,若以文字复制比来衡量一篇论文的文字重合情况,则不太合适。
因为对于一篇十几万字的博士论文来说,10%就已达到1万字,文字复制情况已经非常严重。
因此,对于博硕士论文检测,检测系统使用绝对字数即总重合字数作为检测结果的核心指标。
如图6所示:
图6总重合字数示例
3.1.2总文字复制比(TTR)
总文字复制比则是指学位论文中总的重合字数在总的论文字数中所占的比例。
通过该指标,我们可以直观了解到重合字数在该检测学位论文中所占的比例情况。
3.1.3总文字数(TCA)
总文字数是指该检测论文所有包含的字数,文字复制比与总文字数的乘积即为重合字数。
3.1.4疑似章节数(QCA)、总章节数(TCA)
疑似章节数是则检测论文疑似存在学术不端行为的章节的数量。
总章节数则是指学位论文总的章节数(对于不按章节显示,而是按照固定长度切分的论文,每一段落为一章节)。
3.1.5首部重合文字数(HCCA)、尾部重合文字数(ECCA)
首部重合文字数指学位论文前1万字中重合的文字数量。
尾部重合文字数是指除去前1万字,剩下的部分中重合的文字数量。
对于学位论文,一般开头部分均是综述性的报告介绍,其重要性远低于论文尾部。
3.2子检测指标
对于学位论文的每一章节,又制定了如下检测指标来反映该章节的检测情况,对于一篇学位论文来说,每一章的内容各异,重点也不一样,其核心工作内容一般主要存在某几章中,子检测指标可以让用户迅速了解每一章节的检测情况。
子检测指标包括:
● 文字复制比(TR)
● 重合字数(CNW)
● 最大段长(LPL)
● 平均段长(APL)
● 段落数(PN)
● 段文字比(PR)
● 首部复制比(HR)
● 尾部复制比(ER)
● 引用复制比(RR)*
上述指标从多个角度反映了检测文献的检测情况,便于用户进行针对性审核。
下面对各项指标分别进行说明。
3.2.1文字复制比(TR)
因为学位论文一般文字量较多,为了便于用户快速浏览检测结果。
系统会自动对学位论文进行切分处理。
有如下两种处理方式:
1.若用户提交的论文是MSWord格式,且按照MSWord格式生成了文档目录,检测系统会自动识别论文章节,按论文实际章节信息显示论文内容。
2.若学位论文不存在明显的章节信息,或者不是MSWord格式论文,则系统会自动按照每段1万余字符切分学位论文,按照切分后的结果显示。
文字复制比即指论文切分后每一章节段落的文字复制情况。
文字复制比即指学位论文的某一章节与比对文献比较后,重合文字部分在该章节中所占的比例。
比例越高,反映该章节越多的文字来自于其他已发表文献。
文字复制比反映了文章“抄袭”的文字数量比例,一般来说,文字复制比越高,存在学术不端行为的可能性越大。
文字复制比情况如图7所示。
图7文字复制比示例
3.2.2重合字数(CNW)
重合字数指学位论文该章节与比对文献比较后,重合部分的字数。
一般来说,不管文字复制比如何,重合字数越多,存在学术不端行为的可能性越大。
如图8所示,在图中,虽然文字复制比只有16%,比例不高,但图中左文标红部分实际上是抄袭了右文的标红部分。
图8重合字数示例
3.2.3最大段长(LPL)、平均段长(APL)、段落数(PN)
在学位论文检测中,当连续文字超过一定比例时,称之为段。
在本系统中,一般认为,连续200以上文字称为段。
与比对文献重合的最大段长度即为最大段长。
最大段长反映成段抄袭特征。
连续的文字越长,抄袭的可能性越大。
在学位论文中,所有段的长度的平均值即为平均段长。
在学位论文中,所有段的数量为段落数。
平均段长和段落数反映了重合文字在学位论文中的分布情况,一般来说,指标参数越高,存在学术不端行为的可能性越大。
如图9所示,标红部分的连续文字构成了段,而且它是算法设计的抄袭,审查人员比较容易判断;而在图10中,标红文字不构成段,连续文字较少,对它的性质判断则可能需要更多的信息。
图9 段落复制示例
图10句子复制示例
3.2.4段文字比(PR)
在学位论文的某一章节中,所有该章节文字重合段的字数之和占该章节文字数的比例为段文字比。
段文字比反映了抄袭连续特征。
一般来说,连续文字出现的越多,比文字分散出现的情况更可能存在学术不端行为。
3.2.5首部复制比(HR)
学位论文某一章节的前20%称之为章节首部,首部的文字复制比为首部复制比。
就中文文献来说,一般每一章节正文开头部分出现的是综述性语言,重要性相对偏低。
如图11所示,左文和右文开头大段相同,但文字内容基本都是综述性的介绍。
图11首部复制比示例
3.2.6尾部复制比(ER)
每一章节的后80%称之为章节尾部,尾部的文字复制比为尾部复制比。
通常情况下,尾部文字内容就重要性来说,比前部文字内容要高。
如图12所示,我们仔细查阅比较图11和图12的内容发现,图11中首部文献是综述他人工作,而图12中尾部文献则是阐述自己的研究工作的目的和意义,应该是作者个人工作的体现,在这部分直接抄袭他文,性质要严重得多。
图12尾部复制比示例
3.2.7引用复制比(RR)
引用复制比指与存在引证关系的文献的文字重合部分的比例。
对于学位论文来说,存在引证关系与不存在引证关系的复制部分应区别对待。
复制了他文内容,而不注明引用,性质要更加严重。
同时我们也认为,不是所有的注明了引用的,就不存在抄袭,引用也应有一个度和范围的限制。
第四章类型及实例介绍
按照上面的检测方法和指标体系,TMLC能够处理多种的学术不端类型。
在学位论文检测中,一般不存在不当署名、一稿多投等学术不端行为。
对于学位论文检测中的各类学术不端行为,按照性质的严重性由低到高排序,主要包括:
抄袭、篡改、伪造等。
下面分别进行介绍。
4.1抄袭
针对各种类型,下面分别举例说明:
图16段落抄袭示例
4.2篡改
篡改是指按照期望值随意篡改或取舍数据,以符合自己的研究结论,一般有主观取舍数据和篡改原始数据等形式。
对于篡改,系统也具有一定的手段进行检测,首先来看一个例子,在一篇文献中提到:
分词的准确率为99.66%,词性标注的准确率为99.07%,利用CNKI已有的相关技术,系统可以快速检测与分词准确率和词性标注准确率有关的数值信息,供审查人员参考,对文献中数据值远高于当前公布的数据值的情况,提醒审查人员仔细核查,如图19所示。
图19篡改检测示例
在图中,上面黄色标示的是检测文献中描述的分词准确率和词性标注准确率,下面部分则是在CNKI特色搜索功能——数值搜索中检索到的当前关于分词准确率和词性标注准确率的描述。
我们可以观察到,当前检测到的所有关于分词准确率和词性标注准确率的描述文字中,其数值均低于检测文献中所描述的数值,因此,我们有理由对检测文献中的分词准确率产生怀疑,提示审查人员进一步核查。
4.3伪造
伪造的特点:
新研究成果中提供的材料、方法、数据、推理等方面不符合实际,无法通过重复试验再次取得,有些甚至连原始数据都被删除或丢弃,无法查证。
伪造包括的方面很多,可以伪造数据、伪造基金、伪造项目、伪造数值、表格、图形等。
伪造基金/伪造项目:
有些论文中虚设基金、项目支持,这种情况可通过查询政府相关基金项目库可以快速验证;
伪造数值、图表等知识元,则可以通过CNKI已有的成熟的数值搜索技术、图表搜索技术进行查证,起到警示作用。
注意:
伪造是检测难度最高的不端行为,还需要做进一步、更深的研究。
4.4其他类型
学术不端类型肯定不止上面列出的几种,其他目前能够有所处理的类型还包括:
1.引用杜撰
别人根本没有说过的话,自己编造,却作为他人的话引用。
尤其是杜撰引用国外学者。
2.引文杜撰
根本就不存在的文献,杜撰一篇引文。
第五章系统功能及实例分析
TMLC主要功能包括:
已发表文献检测、论文检测、问题库查询、自建比对库管理等,下面分别结合例子进行介绍。
5.1已发表文献检测
各注册用户可在权限范围内查看本单位已被CNKI正式收录论文的检测结果。
对于确定有问题的文献,还可以将其直接放入问题记录库。
其流程图如图20所示:
图20已发表文献检测流程图
用户可以选择具体某一年的论文进行查阅检测,也可以通过页面提供的检索功能,检索某一个作者的论文或者按照论文篇名检索具体的某一篇文献,如图21所示。
图21已发表文献检测列表
注意:
因为相关原因,所有示例中涉及具体单位和个人的信息基本都隐去。
选择某一篇论文,点击论文标题,进入下一个页面,对于学位论文来讲,一般会被切分成几个到十几个段落,用户可以依次点击查阅,如图22所示。
图22已发表文献切分段落
点击每一段落查看详细的检测结果,包括:
检测指标,重合文字来源文献的信息以及与其文字复制比,在页面下部还标红了所有重合的文字。
让用户快速了解到选择文献大约有多少文字与其他文献重合以及重合文字所处的位置等,如图23所示。
图23检测结果页面
(1)
再选择点击某篇重合文字来源文献篇名,进入下一页面,该页面显示了检测文献与重合文字来源文献具体的比对信息,两篇文献所有重合文字部分均有蓝色字体标示,用户可以选择左文的任意蓝色文字点击,其字体颜色变为红色,同时,右文中与之相同的文字段将自动标红,并自动定位到页面的上部,便于用户查阅,如图24所示。
图24已发表文献检测页面
(2)
点击图24页面中的“查看原版比对”按钮,还可以查看论文的原版比对,原版是指文献发表时的排版样式,这使得用户可以快速的确定网页所指文献是否与原版文献文字一致,如图25所示。
图25原版比对页面
5.2论文检测
该项功能提供对论文的实时在线检测。
将待检测文献通过互联网提交到检测系统服务器,系统根据论文长度大小将在数秒内返回检测结果给用户。
包括以下特点:
1)多手段论文提交方式。
在线提交论文的方式包括三种:
一是单篇论文在线提交,可以选择需要检测的某一论文直接上传提交;二是批量论文在线提交,可以将需要检测的多篇论文压缩为一个zip格式或rar格式的压缩文件,然后提交压缩文件至检测服务器,系统将自动处理压缩文件,完成压缩文件内所有论文的检测;三是手工录入方式,可以在线录入一段文字进行检测,如图26所示。
2)多格式论文处理能力。
系统能够自动处理MSWord、PDF、CAJ、HTML、TXT等多种格式文档,如图26所示。
图26提交文献页面
3)文件夹式管理方式。
为便于用户管理,系统采取了用户完全自主的文件夹式管理方法。
用户可以创建文件夹,设定文件夹的各项系数,包括:
比对专业范围选择、检测时间选择、比对数据库类型选择等。
在创建文件夹之后,当用户将文献提交到选择的文件夹之后,系统将自动根据该文件夹设定的各项系数进行检测,而用户无需每次都进行系数设置操作。
而且用户可以随时对文件夹系数进行修改,重新设定文件夹系数,如图27所示。
图27文件夹式管理页面
4)便捷的文件夹系数设置。
用户可以设置比对专业,例如只选择医学领域文献作为比对数据库;可以设置检测时间,例如只选择2000年到2007年的文献作为比对数据库;可以设置比对库类型,CNKI收录了期刊、学位论文、会议论文、报纸、年鉴、工具书、专利、外文文献、学术文献引文等与科学研究、学习相关的主要资源,这些资源构成了检测系统丰富的比对库类型,用户可以选择一种或多种比对库进行检测,在检测系统中,用户在提交论文页面下,选择创建文件夹链接,将出现如图28所示页面,供用户设置文件夹各项系数。
图28文件夹系数设置
5)用户完全自主的控制模式。
对于用户提交的所有文献,用户拥有完全的处置能力,可以随时进行删除。
不仅可以删除某一篇文献,还可以删除整个文件夹,如图27所示。
注意:
对于学位论文,因篇幅较大,系统只允许用户重新检测每一章节,不能对整个论文进行重新检测。
6)快速的检测结果浏览方式。
当系统检测完成后,用户可以快速的比对检测文献与抄袭来源文献,系统自动将两篇文献文字重合的部分标示出来,便于用户进行快速查阅检查。
同样,系统实现了在文献原始格式(即发表时格式)上的标示比对,更便于用户准确把握检测结果,如图29,30,31所示。
图29论文章节列表
图30检测结果详细信息页面
图31检测结果比对页面
7)用户可以选择将上传论文放入个人比对库,以作为以后检测的比对数据库,该个人比对库完全属于用户,其他用户无权使用。
8)风格简约的文本复制检测报告单,系统能够生成一份针对检测文献的文件复制检测报告单,在报告单上,列出了检测文献篇名、作者、字数等信息,也列出了重合文字来源文献的篇名、作者、发表时间、发表刊物、字数等信息,还列出了重合比例、主要重合文字索引(即每段重合文字开始的前100字符)等信息,如图32所示。
图32系统检测报告单
用户可以对系统检测报告单进行修改,对文献的检测结果重新选择学术不端类型,并写下自己的审查意见,生成最终的终审报告单。
5.3问题库查询
该项功能主要是便于高校管理单位集中保存和浏览确认有问题的毕业论文。
用户利用检测系统对论文进行检测后发现该论文存在较严重学术不端行为,则将该论文放入问题库。
另外,用户还可以随时将已在问题库中的论文删除,操作非常便捷,如图33所示。
图33 问题文献列表
5.4自建比对库管理
用户可以将个人文献或文献库批量上传到服务器,或者把某篇检测文献放入到个人比对库。
以后上传的文献,用户只要在创建文件时,在选择比对库时,选择个人比对库,上传到该文件夹的文献将自动与自建比对库中的文献进行比对。
图34是用户上传个人比对库的界面,用户可以选择上传单篇文档,也可以选择批量上传文档到个人比对库。
图34上传个人比对库
图35是个人比对库文献列表,用户可以选择删除一篇或多篇文献,该文献只是从个人比对库删除,并不是真的删除该条记录,若该文献是检测文献,在检测结果中仍然可以浏览。
图35个人比对库浏览
注意:
自建比对库完全属于用户个人,其他用户无权使用
5.5用户注册
只有注册用户才能使用本系统,注册方法如下图36所示:
图36注册页面
注册资料审核通过后成为注册用户即可使用该系统。
注册用户可对注册资料修改,可修改信息包括用户密码、用户地址等,修改操作如下图37所示:
图37修改资料页面
注意:
重新修改个人资料后,需重新审核后该账号才能使用。
用户可以修改密码,如图38所示。
修改个人密码并不影响账号的使用,但基于安全的考虑,密码长度不能小于8位。
图38修改密码页面
 升级会员
升级会员 