大数据分析培训机构学习路线.docx
《大数据分析培训机构学习路线.docx》由会员分享,可在线阅读,更多相关《大数据分析培训机构学习路线.docx(29页珍藏版)》请在冰豆网上搜索。
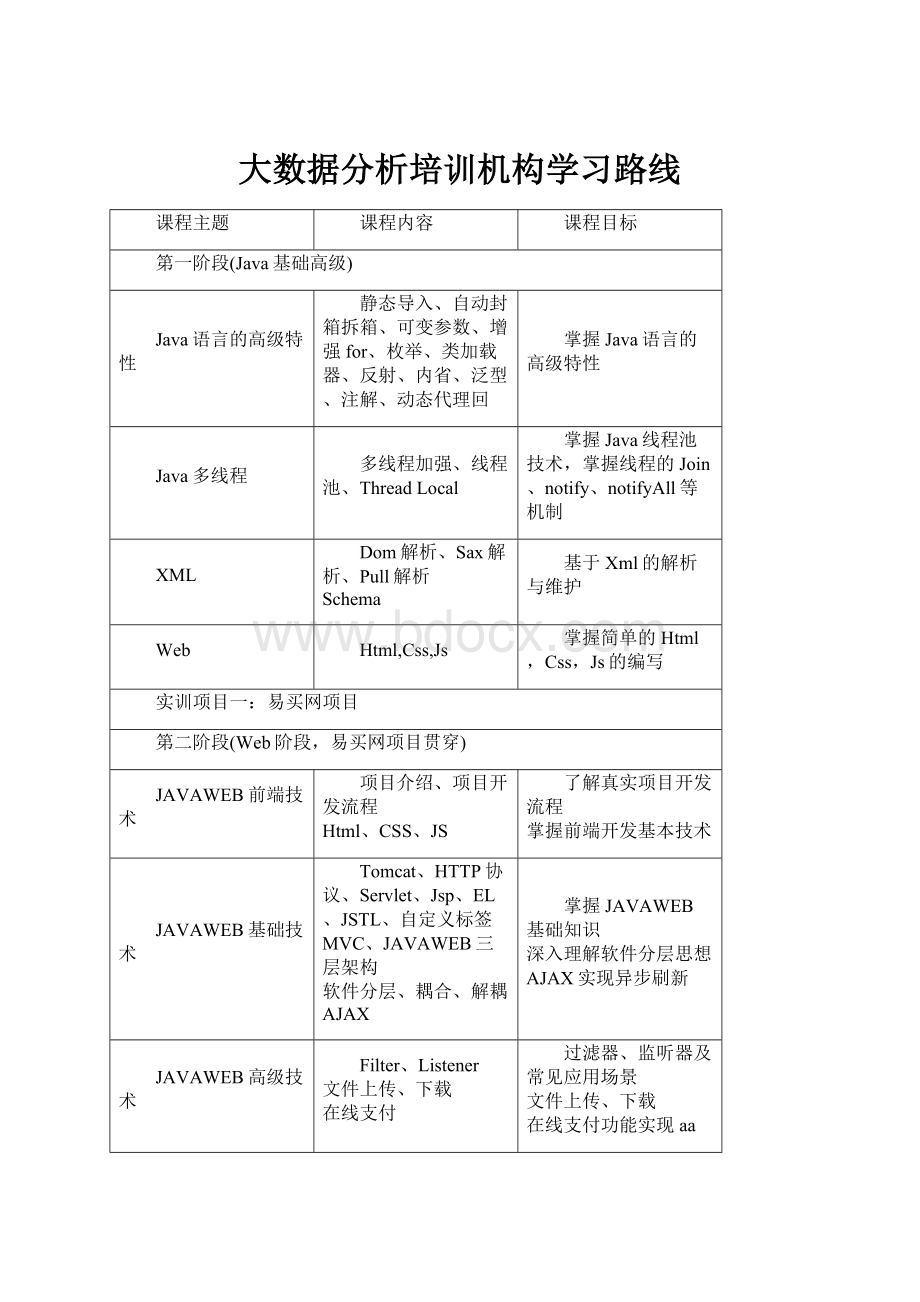
大数据分析培训机构学习路线
课程主题
课程内容
课程目标
第一阶段(Java基础高级)
Java语言的高级特性
静态导入、自动封箱拆箱、可变参数、增强for、枚举、类加载器、反射、内省、泛型、注解、动态代理回
掌握Java语言的高级特性
Java多线程
多线程加强、线程池、ThreadLocal
掌握Java线程池技术,掌握线程的Join、notify、notifyAll等机制
XML
Dom解析、Sax解析、Pull解析
Schema
基于Xml的解析与维护
Web
Html,Css,Js
掌握简单的Html,Css,Js的编写
实训项目一:
易买网项目
第二阶段(Web阶段,易买网项目贯穿)
JAVAWEB前端技术
项目介绍、项目开发流程
Html、CSS、JS
了解真实项目开发流程
掌握前端开发基本技术
JAVAWEB基础技术
Tomcat、HTTP协议、Servlet、Jsp、EL、JSTL、自定义标签
MVC、JAVAWEB三层架构
软件分层、耦合、解耦
AJAX
掌握JAVAWEB基础知识
深入理解软件分层思想
AJAX实现异步刷新
JAVAWEB高级技术
Filter、Listener
文件上传、下载
在线支付
过滤器、监听器及常见应用场景
文件上传、下载
在线支付功能实现aa
JAVAWEB框架加强
面向切面编程
通过注解控制事务
java基础加强、框架加强
JAVA高级特性
熟悉常见设计模式
通过模拟实现框架功能,为后续学习SSH打基础
实训项目二:
国际物流项目
第三阶段(Struts,Hibernate,Spring,SSH项目贯穿)
Struts2
分析Servlet缺点,进行重构
Struts.xml配置文件
ValueStack
Ognl表达式
属性驱动、模型驱动、拦截器、文件上传、token机制等
掌握Struts2在项目开发时用到的各种知识点,能够应用
该框架熟练的开发
Hibernate
ORM的概念、CRUD的完成、Hibernate常用的配置、API详细的分析、对象的三种状态、关联关系、检索、优化、缓存机制
熟练掌握利用Hibernate框架完成项目的开发,深入理解ORMapping的概念,深入理解缓存机制
Spring
IOC、DI、动态代理模式、AOP、基于Spring的数据库编程、Spring的声明式事务处理,Struts2与Hibernate与Spring的整合
深入理解SpringIOC、DI在软件架构中的作用,深入理解SpringAOP的实现机制和应用场景,Struts2的高级特性(对象工厂、静态注入、插件机制、ThreadLocal针对ActionContext的封装、Struts2的核心流程、结果集架构)、深入理解SSH整合的原理
JQuery
JQuery常见选择器的应用
利用JQuery控制Web界面
JS高级
JS面向对象的特征
对象、原型、闭包、JQuery内部结构解析等
Maven
Maven的概念、使用、原理、
Module的概念、仓库
能用Maven搭建项目环境
熟练使用Maven的依赖和继承机制
SSH项目:
国际物流
项目背景、系统USECASE图、系统功能结构图、系统框架图、国际物流核心业务货运管理、购销合同业务、购销合同下货物、出口报运单、装箱单、委托书、发票、财务统计、海量数据导出、出口报运、装箱业务、Shiro高级安全框架、工作流Activiti5
掌握画USECASE图、系统结构图、系统框架图。
面试能顺畅讲述国际物流核心业务,包括:
购销合同、出口报运、装箱、委托、发票、财务。
了解大型数据库设计思路,及数据库在设计上如何优化。
熟练实现合同、货物、附件两级主从结构。
熟练POI制式表单应用。
熟练应用Shiro高级安全框架。
熟练应用工作流Activiti5实现货运管理流程控制。
实训项目三:
易买电商项目
第四阶段(SpringMVC,Mybaties,SSM项目贯穿)
SpringMVC
模拟SpringMVC的核心部件写一个例子、核心分发器、处理器映射、适配器、控制器、注解开发实例、标签机制、拦截器机制、AJAX与JSON调用
熟练掌握SpringMVC的各个组件,理解SpringMVC的架构原理,利用SpringMVC开发项目
MyBaties
CRUD操作、SqlSessionFactory对象、SqlSession对象、集合参数、动态SQL语句、代码优化、Mapper的接口、关联关系、缓存机制、拦截器、MyEclipse插件的使用
熟练掌握SpringMVC的各个组件,理解SpringMVC的架构原理,利用SpringMVC开发项目
SSM项目(易买电商)
项目需求讲解、环境的搭建、后台系统实现、前台系统搭建、内容管理实现、Redis缓存解决前台访问性能问题、单点登录、异步订单系统处理、Lucene与Solor实现文件的检索、ActivityMQ实现消息的异步通信、MySQL的数据库的读写分离、分布式环境的部署和实施
了解电商项目的需求分析,掌握用pom.xml文件构建项目,实现电商项目的前台的内容管理、菜单管理、购物等。
掌握Redis缓存如何提供性能、利用Solor做全文检索、利用ActivityMQ的异步机制把缓存中的改动同步到各个环节、掌握MySQL的主从复制和读写分离。
利用lvs,keepalived,nginx,tomcat搭建高并发的web环境
实训项目四:
电信项目
第五阶段(分布式、高并发、集群、电信项目贯穿)
网络编程
Socket、Io、Nio、Mina、RPC技术、多线程、线程池
把电信项目的部分环节利用mina、RPC技术实现
数据仓库
数据仓库基础知识
ETL
MySQL的导入工具、分表,分区、读写分离、存储过程级多维分析
掌握数据仓库的知识内容,这是大数据分析的基础
分布式缓存
学习MemoryCache与Redis两种缓存
掌握两种缓存的原理、以及操作
Zookeeper
Zookeeper的选举、数据的同步、Zookeeper的部署、Follow与Leader
了解Zookeeper的选举算法、同步机制、掌握Zookeeper的集群的搭建
集群
Keepalived的Loadblancing机制、Nginex反向代理服务器、Tomcat集群、Lvs
利用Lvs、Keepalived、Nginx、Tomcat搭建高并发、分布式的Web服务器
SOA
Rest风格的服务架构、基于Rest风格的WebService的使用、dubbo服务框架的使用
利用服务性框架使得系统的耦合性更弱,扩展性更强
云计算
云计算的概念、Iaas、Paas、Saas的理解、虚拟化的概念
理解云计算
电信项目
把上面所学的知识点全部结合起来做电信行业的日志分析系统
通过项目掌握MySQL的集群、读写分离、优化、掌握Mina框架的通信机制、掌握Zookeeper的高可用机制、利用MySql掌握数据仓库的概念、利用分布式缓存提高系统的性能
实训项目五:
电信项目
第六阶段(Hadoop,Spark,电信项目贯穿)
Hadoop的分布式文件系统HDFS
HDFS的概念、HDFS的API的应用、NameNode与SecondaryNameNode与DataNode的原理与通信机制、数据块Block的概念、NameNode的文档目录树、NameNode与DataNode的关联
Hadoop伪分布式的搭建、利用HDFS的API对分布式文件系统进行操作、掌握NameNode与SecondaryNameNode的通信原理、掌握NameNode与DataNode的通信原理
Hadoop的计算框架MapReduce
利用MapReducer的计算框架实现电信日志的分析、深入理解Shuffle机制、FileOutPutFormat、FileInPutFormat
熟练Map、Reducer、Sort、Partition的编程、深入理解Shuffle机制、深入理解OutPutFormat与InputFormat、基于Hadoop的对象序列化机制
Hadoop的资源管理与资源调度
Yarn框架
深入理解MapReducer的通信机制:
利用Yarn的资源管理和资源调度机制。
理解进程ResourceManager,NodeManager,ApplicationMaster等进程的作用
深入理解Yarn的资源管理与资源调度机制。
掌握整个MapReducer的计算流程和资源调度流程
HBase
搭建NOSQL数据库HBase的集群、利用Zookeeper做HBase的HA机制
掌握HBase的集群的的搭建
HIVE
数据仓库基础知识、Hive定义、Hive体系结构简介、Hive集群、客户端简介、HiveQL定义、HiveQL与SQL的比较、数据类型、外部表和分区表、表的操作与CLI客户端演示、数据导入与CLI客户端演示、查询数据与CLI客户端演示、数据的连接与CLI客户端演示、用户自定义函数(UDF)的开发与演示
利用HIVE做日志分析的查询
Spark
Spark介绍:
Spark应用场景、Scala编程语言、Scala高级编程、Spark集群部署等
利用Spark流式编程做日志的分析
电信项目
把第四阶段的电信项目用Hadoop与Spark实现
熟练应用Hadoop的MapReducer,Hive与Spark
走心课程全面覆盖实力熬炼技术骨干
8大授课阶段全力培养未来高端大数据人才
课程详情
∙第一阶段
Java语言基础
∙第二阶段
HTML、CSS与JavaScript
∙第三阶段
JavaWeb和数据库
∙第四阶段
Linux基础
∙第五阶段
Hadoop生态体系
∙第六阶段
Spark生态体系
∙第七阶段
Storm实时开发
∙第八阶段
项目案例
01
第一阶段Java语言基础
∙01Java开发介绍
-Java的发展历史
-Java的应用领域
-Java语言的特性
-Java面向对象
-Java性能分类
-搭建Java环境
-Java工作原理
∙02熟悉Eclipse开发工具
-Eclipse简介与下载
-安装Eclipse的中文语言包
-Eclipse的配置与启动
-Eclipse工作台与视图
-“包资源管理器”视图
-使用Eclipse
-使用编辑器编写程序代码
∙03Java语言基础
-Java主类结构
-基本数据类型
-变量与常量
-Java运算符
-数据类型转换
-代码注释与编码规范
-Java帮助文档
∙04Java流程控制
-复合语句
-条件语句
-if条件语句
-switch多分支语句
-while循环语句
-do…while循环语句
-for循环语句
∙05Java字符串
-String类
-连接字符串
-获取字符串信息
-字符串操作
-格式化字符串
-使用正则表达式
-字符串生成器
∙06Java数组与类和对象
-数组概述
-一维数组的创建及使用
-二维数组的创建及使用
-数组的基本操作
-数组排序算法
-Java的类和构造方法
-Java的对象、属性和行为
∙07数字处理类与核心技术
-数字格式化与运算
-随机数与大数据运算
-类的继承与Object类
-对象类型的转换
-使用instanceof操作符判断对象类型
-方法的重载与多态
-抽象类与接口
∙08I/O与反射、多线程
-流概述与File类
-文件输入/输出流
-缓存输入/输出流
-Class类与Java反射
-Annotation功能类型信息
-枚举类型与泛型
-创建、操作线程与线程安全
∙09Swing程序与集合类
-常用窗体
-标签组件与图标
-常用布局管理器与面板
-按钮组件与列表组件
-常用事件监听器
-集合类概述
-Set集合与Map集合及接口
02
第二阶段HTML、CSS与JavaScript
∙01PC端网站布局
-HTML基础,CSS基础,CSS核心属性
-CSS样式层叠,继承,盒模型
-容器,溢出及元素类型
-浏览器兼容与宽高自适应
-定位,锚点与透明
-图片整合
-表格,CSS属性与滤镜
-CSS优化
∙02HTML5+CSS3基础
-HTML5新增的元素与属性
-CSS3选择器
-文字字体相关样式
-CSS3位移与变形处理
-CSS32D、3D转换与动画
-弹性盒模型
-媒体查询
-响应式设计
∙03WebApp页面布局
-移动端页面设计规范
-移动端切图
-文字流式/控件弹性/图片等比例/特殊设计的布局
-等比缩放布局
-viewport/meta
-rem/vw的使用
-flexbox详解
-移动web特别样式处理
∙04原生JavaScript交互功能开发
-什么是JavaScript
-JavaScript使用及运作原理
-JavaScript基本语法
-JavaScript内置对象
-事件,事件原理
-JavaScript基本特效制作
-cookie存储
-正则表达式
∙05Ajax异步交互
-Ajax概述与特征
-Ajax工作原理
-XMLHttpRequest对象
-同步与异步
-Ajax异步交互
-Ajax跨域问题
-Ajax数据的处理
-基于WebSocket和推送的实时交互
∙06JQuery应用
-各选择器使用,及应用优化
-Dom节点的各种操作
-事件处理、封装、应用
-jQuery中的各类动画使用
-可用性表单的开发
-jQueryAjax、函数、缓存;
-jQuery编写插件、扩展、应用
-理解模块式开发及应用
03
第三阶段JavaWeb和数据库
∙01数据库
-Mysql数据库
-JDBC开发
-连接池和DBUtils
-Oracle介绍
-MongoDB数据库介绍
-apache服务器/Nginx服务器
-Memcached内存对象缓存系统
∙02JavaWeb开发核心
-XML
-HTTP及Tomcat
-Servlet工作原理解析
-深入理解Session与Cookie
-Tomcat的系统架构与设计模式
-JSP语法与内置对象
-JDBC技术
-大浏览量系统的静态化架构设计
∙03JavaWeb开发内幕
-深入理解Web请求过程
-JavaI/O的工作机制
-JavaWeb中文编码
-Javac编译原理
-class文件结构
-ClassLoader工作机制
-JVM体系结构与工作方式
-JVM内存管理
04
第四阶段Linux基础
∙01Linux安装与配置
-Linux常见版本及VMware
-安装Linux至硬盘及虚拟机安装Linux系统
-虚拟机网络配置(IP地址、主机名、防火墙)
-超级用户root
-关于硬件驱动程序
-进阶:
配置Grub
-CSS预处理器LESS框架使用
-CSS组件框架编写
∙02系统管理与目录管理
-Shell基本命令
-使用命令行补全和通配符
-find命令、locate命令
-查找特定程序:
whereis
-Linux文件系统的架构
-移动、复制和删除
-文件和目录的权限
-文件类型与输入输出
∙03用户与用户组管理
-软件包管理
-磁盘基本管理命令(df、du、fdisk、mount)
-高级硬盘管理RAID和LVM
-进阶:
备份你的工作和系统
-用户与用户组管理
-内存使用监控命令(top、free等)
-软件安装方式(rpm、tar、yum)
-进程管理
∙04Shell编程
-Shell脚本编程概述
-正则表达式
-字符集和单词、字符类
-Shell脚本编程
-脚本执行命令和控制语句
-Shell定制
-个性化设置:
修改.bashrc文件
-Shell脚本调试
∙05服务器配置
-系统引导
-管理守护进程
-通过xinetd启动SSH服务
-配置inetd
-Apache基础
-设置Apache服务器
-PHP基础
-配置DHCP服务器
∙06Vi编辑器与Emacs编辑器
-vi中的常用命令
-vi中的字符与文件操作
-vi中的窗口操作
-emacs概述
-emacs文本编辑
-emacs缓冲区和窗口
-emacs的扩展工具
05
第五阶段Hadoop生态体系
∙01Hadoop起源与安装
-大数据概论
-Google与Hadoop模块
-Hadoop生态系统
-Hadoop常用项目介绍
-Hadoop环境安装配置
-Hadoop安装模式
-Hadoop配置文件
∙02MapReduce快速入门
-WordCount准备开发环境
-MapReduce编程接口体系结构
-MapReduce通信协议
-导入Hadoop的JAR文件
-MapReduce代码的实现
-打包、部署和运行
-打包成JAR文件
∙03Hadoop分布式文件系统
-认识HDFS及其HDFS架构
-Hadoop的RPC机制
-HDFS的HA机制
-HDFS的Federation机制
-Hadoop文件系统的访问
-JavaAPI接口与维护HDFS
-HDFS权限管理
∙04Hadoop文件I/O详解
-Hadoop文件的数据结构
-HDFS数据完整性
-文件序列化
-Hadoop的Writable类型
-Hadoop支持的压缩格式
-Hadoop中编码器和解码器
-gzip、LZO和Snappy比较
∙05MapReduce工作原理
-MapReduce函数式编程概念
-MapReduce框架结构
-MapReduce运行原理
-Shuffle阶段和Sort阶段
-任务的执行与作业调度器
-自定义Hadoop调度器
-YARN架构及其工作流程
∙06MapReduce编程开发
-WordCount案例分析
-输入格式与输出格式
-压缩格式与MapReduce优化
-辅助类与Streaming接口
-MapReduce二次排序
-MapReduce中的Join算法
-从MySQL读写数据
-Hadoop系统调优
∙07Hive数据仓库工具
-Hive工作原理、类型及特点
-Hive操作及Hive复合类型
-Hive的JOIN详解
-Hive优化策略
-Hive内置操作符与函数
-Hive用户自定义函数接口
-Hive的权限控制
∙08开源数据库HBase
-HBase的特点
-HBase访问接口
-HBase存储结构与格式
-HBase设计
-关键算法和流程
-HBase的Shell操作
-HBase客户端
∙09Sqoop与Oozie
-安装部署Sqoop
-Sqoop数据迁移
-Sqoop使用案例
-Oozie简介
-Oozie与Hive
-Azkaban工作流
06
第六阶段Spark生态体系
∙01Spark简介
-什么是Spark
-Spark大数据处理框架
-Spark的特点与应用场景
-SparkSQL原理和实践
-SparkStreaming原理和实践
-GraphXSparkR入门
-Spark的监控和调优
∙02Spark部署和运行
-部署准备与下载
-Spark生态和安装部署
-LocalYARN模式部署
-Local模式运行
-SparkStandaloneHA安装
-YARN模式运行Spark
-Spark应用程序部署工具spark-submit
∙03Spark程序开发
-启动SparkShell
-加载text文件
-RDD操作及其应用
-RDD缓存
-构建Eclipse开发环境
-构建IntelliJIDEA开发环境
-创建SparkContext对象
-编写编译并提交应用程序
∙04Spark编程模型
-RDD特征与依赖
-集合(数组)创建RDD
-存储创建RDD
-RDD转换执行控制操作
-广播变量
-累加器
∙05作业执行解析
-Spark组件
-RDD视图与DAG图
-基于Standalone模式的Spark架构
-基于YARN模式的Spark架构
-作业事件流和调度分析
-构建应用程序运行时环境
-应用程序转换成DAG
∙06SparkSQL与DataFrame
-SparkSQL架构特性
-DataFrame和RDD的区别
-创建操作DataFrame
-RDD转化为DataFrame
-加载保存操作与Hive表
-Parquet文件JSON数据集
-分布式的SQLEngine
-性能调优数据类型
∙07深入SparkStreaming
-SparkStreaming工作原理
-DStream编程模型
-InputDStream
-DStream转换状态输出
-优化运行时间及内存使用
-文件输入源
-基于Receiver的输入源
-输出操作
∙08SparkMLlib与机器学习
-机器学习分类级算法
-SparkMLlib库
-MLlib数据类型
-MLlib的算法库与实例
-ML库主要概念
-算法库与实例
∙09GraphX与SparkR
-SparkGraphX架构
-GraphX编程与常用图算法
-GraphX应用场景
-SparkR的工作原理
-R语言与其他语言的通信
-SparkR的运行与应用
-R的DataFrame操作方法
-SparkR的DataFrame
∙10spark项目实战
-大数据分析系统
-系统资源分析平台
-在Spark上训练LR模型
-获取二级邻居关系图
∙11scala编程
-scala编程介绍
-Scala基本语法
-Scala开发环境搭建
-Scala开发Spark应用程序
∙12Python编程
-Python编程介绍
-Python的基本语法
-Python开发环境搭建
-Pyhton开发Spark应用程序
07
第七阶段Storm实时开发
∙01storm简介与基本知识
-storm的诞生诞生与成长
-storm的优势与应用
-storm基本知识概念和配置
-序列化与容错机制
-可靠性机制—保证消息处理
-storm开发环境与生产环境
-storm拓扑的并行度
-sto
 升级会员
升级会员 