实验3-MapReduce编程初级实践_精品文档.docx
《实验3-MapReduce编程初级实践_精品文档.docx》由会员分享,可在线阅读,更多相关《实验3-MapReduce编程初级实践_精品文档.docx(7页珍藏版)》请在冰豆网上搜索。
实验3MapReduce编程初级实践
实验3MapReduce编程初级实践
1.实验目的
1.通过实验掌握基本的MapReduce编程方法;
2.掌握用MapReduce解决一些常见的数据处理问题,包括数据去重、数据排序和数据挖掘等。
2.实验平台
已经配置完成的Hadoop伪分布式环境。
3.实验内容和要求
1.编程实现文件合并和去重操作
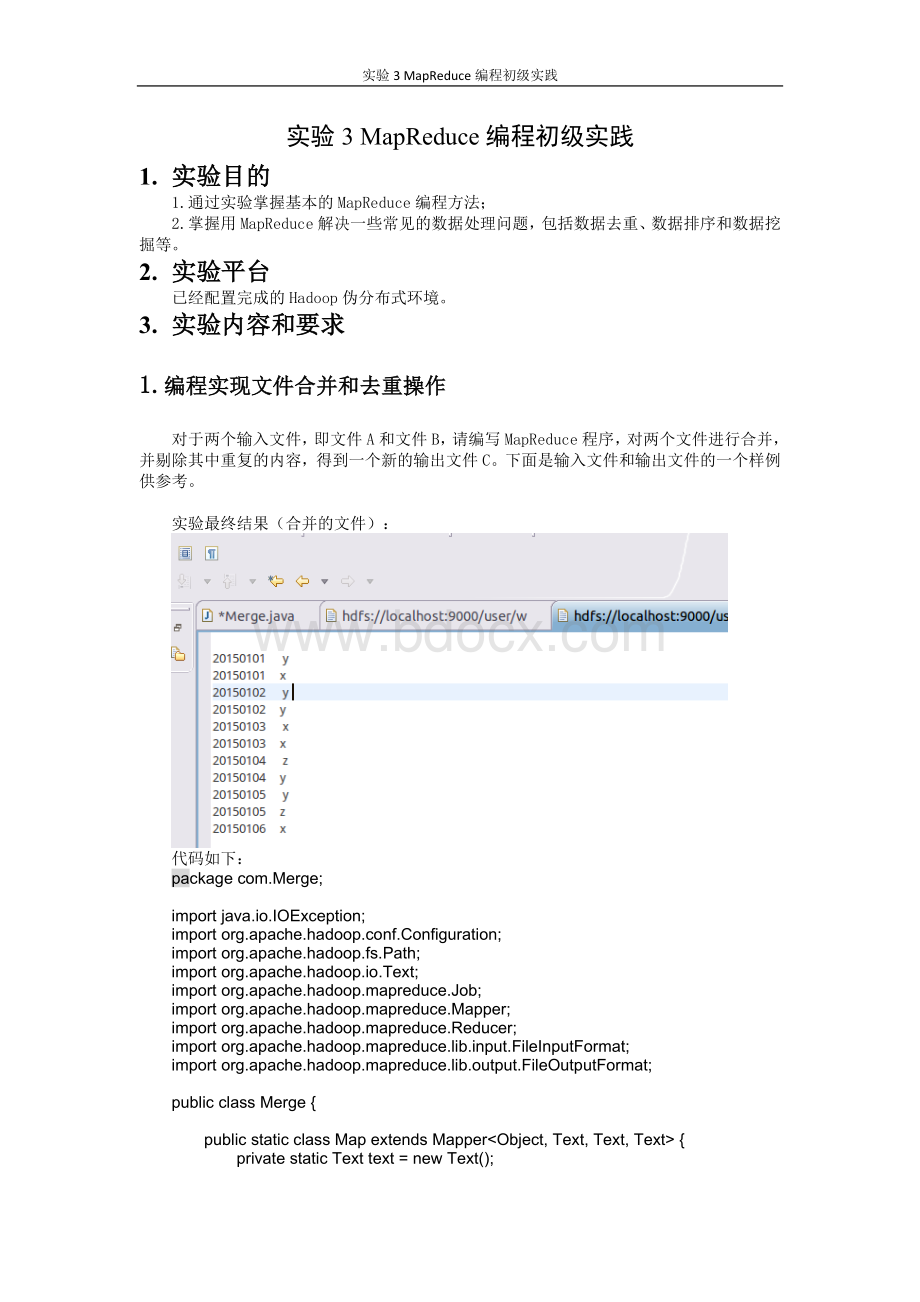
对于两个输入文件,即文件A和文件B,请编写MapReduce程序,对两个文件进行合并,并剔除其中重复的内容,得到一个新的输出文件C。
下面是输入文件和输出文件的一个样例供参考。
实验最终结果(合并的文件):
代码如下:
packagecom.Merge;
importjava.io.IOException;
importorg.apache.hadoop.conf.Configuration;
importorg.apache.hadoop.fs.Path;
importorg.apache.hadoop.io.Text;
importorg.apache.hadoop.mapreduce.Job;
importorg.apache.hadoop.mapreduce.Mapper;
importorg.apache.hadoop.mapreduce.Reducer;
importorg.apache.hadoop.mapreduce.lib.input.FileInputFormat;
importorg.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
publicclassMerge{
publicstaticclassMapextendsMapper{
privatestaticTexttext=newText();
publicvoidmap(Objectkey,Textvalue,Contextcontext)
throwsIOException,InterruptedException{
text=value;
context.write(text,newText(""));
}
}
publicstaticclassReduceextendsReducer{
publicvoidreduce(Textkey,Iterablevalues,Contextcontext)
throwsIOException,InterruptedException{
context.write(key,newText(""));
}
}
publicstaticvoidmain(String[]args)throwsException{
Configurationconf=newConfiguration();
conf.set("fs.defaultFS","hdfs:
//localhost:
9000");
String[]otherArgs=newString[]{"input","output"};
if(otherArgs.length!
=2){
System.err.println("Usage:
Mergeandduplicateremoval");
System.exit
(2);
}
Jobjob=Job.getInstance(conf,"Mergeandduplicateremoval");
job.setJarByClass(Merge.class);
job.setMapperClass(Map.class);
job.setReducerClass(Reduce.class);
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(Text.class);
FileInputFormat.addInputPath(job,newPath(otherArgs[0]));
FileOutputFormat.setOutputPath(job,newPath(otherArgs[1]));
System.exit(job.waitForCompletion(true)?
0:
1);
}
}
2.编写程序实现对输入文件的排序
现在有多个输入文件,每个文件中的每行内容均为一个整数。
要求读取所有文件中的整数,进行升序排序后,输出到一个新的文件中,输出的数据格式为每行两个整数,第一个数字为第二个整数的排序位次,第二个整数为原待排列的整数。
下面是输入文件和输出文件的一个样例供参考。
实验结果截图:
代码如下:
packagecom.MergeSort;
importjava.io.IOException;
importorg.apache.hadoop.conf.Configuration;
importorg.apache.hadoop.fs.Path;
importorg.apache.hadoop.io.IntWritable;
importorg.apache.hadoop.io.Text;
importorg.apache.hadoop.mapreduce.Job;
importorg.apache.hadoop.mapreduce.Mapper;
importorg.apache.hadoop.mapreduce.Reducer;
importorg.apache.hadoop.mapreduce.lib.input.FileInputFormat;
importorg.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
publicclassMergeSort{
publicstaticclassMapextends
Mapper{
privatestaticIntWritabledata=newIntWritable();
publicvoidmap(Objectkey,Textvalue,Contextcontext)
throwsIOException,InterruptedException{
Stringline=value.toString();
data.set(Integer.parseInt(line));
context.write(data,newIntWritable
(1));
}
}
publicstaticclassReduceextends
Reducer{
privatestaticIntWritablelinenum=newIntWritable
(1);
publicvoidreduce(IntWritablekey,Iterablevalues,
Contextcontext)throwsIOException,InterruptedException{
for(IntWritableval:
values){
context.write(linenum,key);
linenum=newIntWritable(linenum.get()+1);
}
}
}
publicstaticvoidmain(String[]args)throwsException{
Configurationconf=newConfiguration();
conf.set("fs.defaultFS","hdfs:
//localhost:
9000");
String[]otherArgs=newString[]{"input2","output2"};/*直接设置输入参数*/
if(otherArgs.length!
=2){
System.err.println("Usage:
mergesort");
System.exit
(2);
}
Jobjob=Job.getInstance(conf,"mergesort");
job.setJarByClass(MergeSort.class);
job.setMapperClass(Map.class);
job.setReducerClass(Reduce.class);
job.setOutputKeyClass(IntWritable.class);
job.setOutputValueClass(IntWritable.class);
FileInputFormat.addInputPath(job,newPath(otherArgs[0]));
FileOutputFormat.setOutputPath(job,newPath(otherArgs[1]));
System.exit(job.waitForCompletion(true)?
0:
1);
}
}
3.对给定的表格进行信息挖掘
下面给出一个child-parent的表格,要求挖掘其中的父子辈关系,给出祖孙辈关系的表格。
实验最后结果截图如下:
代码如下:
packagecom.join;
importjava.io.IOException;
importjava.util.*;
importorg.apache.
 升级会员
升级会员 