Trie图.docx
《Trie图.docx》由会员分享,可在线阅读,更多相关《Trie图.docx(14页珍藏版)》请在冰豆网上搜索。
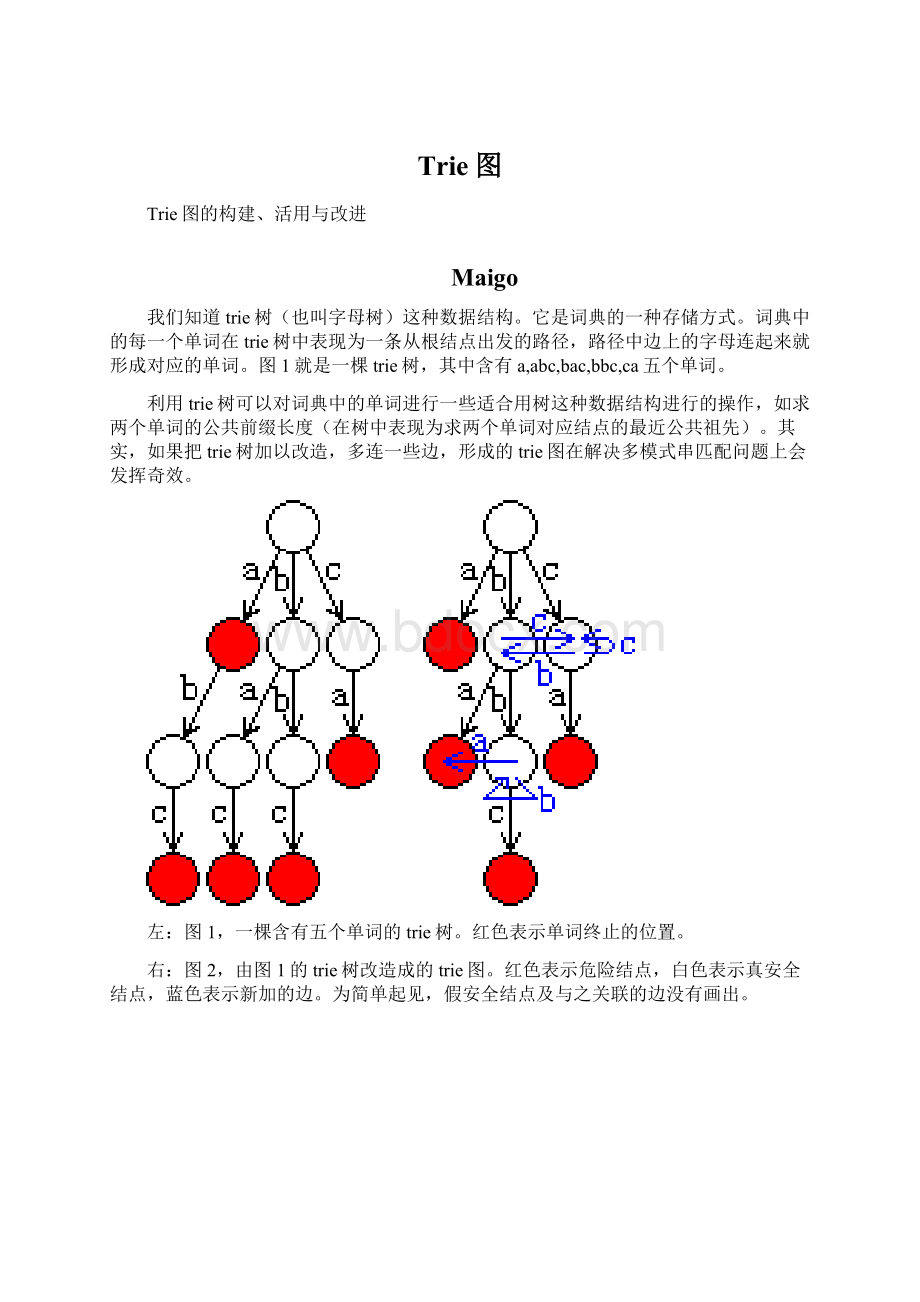
Trie图
Trie图的构建、活用与改进
Maigo
我们知道trie树(也叫字母树)这种数据结构。
它是词典的一种存储方式。
词典中的每一个单词在trie树中表现为一条从根结点出发的路径,路径中边上的字母连起来就形成对应的单词。
图1就是一棵trie树,其中含有a,abc,bac,bbc,ca五个单词。
利用trie树可以对词典中的单词进行一些适合用树这种数据结构进行的操作,如求两个单词的公共前缀长度(在树中表现为求两个单词对应结点的最近公共祖先)。
其实,如果把trie树加以改造,多连一些边,形成的trie图在解决多模式串匹配问题上会发挥奇效。
左:
图1,一棵含有五个单词的trie树。
红色表示单词终止的位置。
右:
图2,由图1的trie树改造成的trie图。
红色表示危险结点,白色表示真安全结点,蓝色表示新加的边。
为简单起见,假安全结点及与之关联的边没有画出。
一、Trie图的构建
我们通过一个例题来探究trie图的构建方法。
Aho-Corasick自动机和trie图的差别
左边的图是一个Trie,红色的节点表示终结点。
右边的就是Trie图了,注意观察和左边的图的区别,发现有两个改变:
1.所有Trie中红色的点往后的点都去掉了;
2.所有白色的点都有a,b,c三个链接。
3.bac被缩短了成为ba(改造trie树)
4.指向trie树树根的边没有画出(除了危险结点,其他结点都是完备结点,trie[i].next[j]=0是有意义的,也就是后缀结点是trie树根结点),根节点相当于空串
首先要说的是,并不是所有Trie都将终结点后的点都去掉了。
其次,假设我们的字母表为E,将第2点推广说明一下,就是所有的非终结点都有|E|个链接。
回忆一下AC自动机,当一个节点不存在某个链接时,它便开始向前回溯(类似KMP算法),而在Trie图上游历就没有这种情况,因为任何一个点都有字母表中任何一个链接。
因此,可以说Trie图和AC自动机非常类似,特别是它们的构建方法,都是采用BFS回溯来做。
因此,从某种意义上说,AC自动机就是Trie图的一个缩微版本。
Trie图其实是KMP的失败数组(通常写作fail[],next[]或shift[])在Trie树上的扩展。
回想到KMP的精髓是模板串通过自匹配产生失败数组的过程,这过程放到Trie图上就是模板串集合的自匹配,只不过失败指针的指向不再局限在一个模板串之内,而是可以从一个模板串的某个字符指向别的模板串的某个字符。
构造所耗时间除了与KMP一样取决于模板串的长度外,还取决于字符集的大小|sigema|,因为需要保证所有Trie树中的非终态结点有完备的状态转移,这点反映到数据结构上就是每个结点都有|sigema|条出边,原Trie树中出边不足的结点需要补边。
可以说Trie图=Trie树+KMP
【例1】不良单词探测器
【题目描述】给出一个词典,其中的单词为不良单词。
单词均为小写字母。
再给出一段文本,文本的每一行也由小写字母构成。
判断文本中是否含有任何不良单词。
例如,若rob是不良单词,那么文本problem含有不良单词。
【输入】第一行为一个整数n,表示不良单词的个数。
接下来n行是词典。
下面一行为一个整数m,表示文本的行数。
接下来m行是文本。
【输出】如果文本包含不良单词,输出一行“Yes”,否则输出一行“No”。
【样例输入】
1
rob
1
internetproblemsolvingcontest
【样例输出】
Yes
【备注】因本题只是用来讨论trie图的构建方法,故未给出数据范围。
【分析】判断文本是否包含不良单词可以一行一行地判断。
而判断长为L的一行文本s是否含有不良单词可以这样进行:
让i从1变化到L,依次判断s的前i个字符构成的字符串是否以不良单词结尾。
然而,我们希望在判断s的前k个字符时,能够利用前k-1个字符的结果,即这两个状态间可以方便地进行转移。
注意到trie树中的边正如一个个“方向标”,因此我们有了一个美好的设想:
从根结点出发,沿着标有s[1]的边走一步,再沿标有s[2]的边走一步,一直这样走下去!
从根结点出发,沿着文本字母所标识的边走下去,若能走到危险结点则说明该单词中有不良单词,否则一直在trie图中循环
现在有了一个问题:
如果从当前走到的结点出发,没有需要走的边,该怎么办?
只要“创造”一条这样的边即可。
那么这条边应该指向哪个结点呢?
如果同样“创造”一个结点,那是毫无意义的。
解决这个问题,要从我们“沿边走”的动机谈起。
我们之所以“沿边走”,是因为我们把结点看成了状态,把边看成了状态间转移的途径。
要确定新加的边应连到哪个结点,就需要找我们想走到但去不存在的那个结点与已有的哪个结点是等价的。
那么“等价”的标准是什么呢?
我们先来解决另一个问题:
定义trie树中从根结点到某个结点的路径上的边上的字符连起来形成的字符串为这个结点的路径字符串。
如果一个结点的路径字符串以不良单词结尾,那么称这个结点为危险结点,否则称之为安全结点。
那么如何判断某个结点是否危险呢?
显然根结点是安全结点。
对于一个非根结点,它是危险结点的充要条件是:
它的路径字符串本身就是一个不良单词,或者它的路径字符串的后缀(一个字符串去掉第一个字符后剩下的部分叫做它的后缀)对应的结点是危险结点。
如果称一个结点的路径字符串的后缀对应的结点为它的后缀结点,那么如何求任一结点的后缀结点呢?
一个结点和其后缀结点是等效的,即从树根到该结点的后缀结点的路径字符串恰好是从树根到该结点的路径字符串去掉第一个字符所剩下的路径字符串,这样若该结点没有某一后继结点则那个后继结点可以看成是该结点的后缀结点的特定后继结点,这样递归,可以使安全结点全都成为完备结点
根结点的后缀结点是它本身。
处于trie树第二层的结点的后缀结点也是根结点。
对于再往下的某个结点,设它的路径字符串的最后一个字符为c,那么这个结点的后缀为从它在trie树中父结点的后缀结点出发,沿标有c的边走一步后到达的结点。
(下文中称从x结点出发,沿标有字符c的边走一步到达的结点为x的c孩子)
那么,如果它的父结点的后缀结点没有c孩子怎么办呢?
到此,我们看到两个问题已经合而为一了。
我们假设有这样一个c孩子(记作x),并且从x出发又繁衍出无数的子子孙孙。
我们来判断x的危险性。
显然x本身的路径字符串不是不良单词,且它的子孙的路径字符串也不是不良单词。
因此以x为根的子树中任一结点y的危险性与y的后缀结点的危险性相同。
这也就是说,以x为根的子树与以x的后缀结点为根的子树是一模一样的。
因此,我们把需要新建的从x的父亲指向x的边直接指向x的后缀结点即可。
由此我们可以把trie树改造成一个有向图:
Step1:
求根结点的的危险性和后缀结点,补齐由它出发的边。
补充的边应指向本身。
Step2:
从第二层起,按层次遍历trie树,求每个结点的后缀结点并补齐由它出发的边。
危险性与后缀结点的求法在上文已有说明;若x没有c孩子,则新建一条这样的边,指向x的后缀结点的c孩子。
处理某个结点的过程中需要用到深度比它小的结点的后缀结点及各个孩子。
由于我们按层次遍历trie树,这些信息都已求得。
这样由trie树改造成的有向图就叫做trie图。
图2就是由图1的trie树改造成的trie图。
我们美好的设想终于变成了现实。
由根结点出发,按照文本中的字符一步步走下去。
若走到一个危险结点,则发现了一个不良单词;若一直没走到危险结点,则文本不含不良单词。
本题的算法还可稍加优化。
把安全结点分为两类:
如果在trie树中由根结点到某个安全结点的路径上没有危险结点,那么称这个安全结点为真安全结点,否则称之为假安全结点。
由于新建的边的终点的深度不会大于起点的深度,因此要到达一个假安全结点,必须经过一个危险结点。
而在本题中,一旦到达一个危险结点,程序就会停止,因此假安全结点是没有用的,也就是说,在trie图的构建过程中,若发现一个危险结点,那么它及它的子孙的属性都不必计算了。
如果用L1、L2分别表示不良单词和文本的总长度,用a表示字符集中字符的个数,那么trie图的时间复杂度为O(L1a+L2),空间复杂度为O(L1a)。
二、Trie图的活用
如果仅仅用trie图来做多模式匹配,那就太大材小用了。
下面将通过两个例题来说明trie图的一些活用。
从例1可以看到,危险结点在图中往往是一些障碍,在多数用到trie图的问题中,有用的结点只有真安全结点。
我们把trie图中的真安全结点以及它们之间的边构成的子图叫做安全图。
【例2】病毒(题目来源:
POI#7)
【题目描述】已知某些特定的01串是病毒的特征代码。
如果一个01串不含有任何病毒特征代码,则称它为一段安全代码。
给定病毒特征库,判断是否存在无限长的安全代码。
【输入(文件wir.in)】第一行为一个整数n,表示病毒特征代码的条数。
下面n行,每行一段病毒特征代码。
所有代码长度之和不超过30000。
【输出(文件wir.out)】若存在无限长的安全代码,输出一行“TAK”,否则输出一行“NIE”。
【样例输入】
3
01
11
00000
【样例输出】
NIE
【分析】“无限长”的安全代码是什么意思呢?
就是说从根结点出发,在安全图中可以走无限步。
“无限步”又是什么意思呢?
就是说安全图中有环(因为不包括危险结点)。
因此我们建立一个trie图并对其安全图进行拓扑排序(能进行拓扑排序则说明没有回路和自环),若成功,则安全图无环,输出“NIE”,否则输出“TAK”。
【例3】Censored!
(题目来源:
Ural1158)
【题目描述】已知一个由n(1<=n<=50)个字符组成的字符集及p(0<=p<=10)个不良单词(长度均不超过10),求长度为m(1<=m<=50)且不含不良单词的字符串的数目。
【输入(标准输入)】第一行为三个整数n,m,p。
第二行为n个字符,表示字符集。
下面p行,每行一个不良单词。
【输出(标准输出)】一个整数,表示长度为m且不含不良单词的字符串的数目。
【样例输入】
333
QWE
QQ
WEE
Q
【样例输出】
7
【分析】求长度为m且不含不良单词的字符串的数目,就是求在安全图中从根结点出发走m步有多少种走法。
用count[step,x]表示从根结点出发走step步到结点x的走法数,则容易写出下面的伪代码:
fillchar(count,sizeof(count),0);
count[0,根]:
=1;
forstep:
=1tomdo
for安全图中每条边(i,j)do
inc(count[step,j],count[step-1,i]);//inc:
+
ans:
=0;
for安全图中每个结点xdo
inc(ans,count[m,x]);
显然,本题还需要用高精度。
我们看到,trie图的安全图上还是大有文章可做的。
因为它是一个有向图,所以可以对它进行拓扑排序,也可以利用它的有向性实施动态规划。
#include
#include"queue"
#include
usingnamespacestd;
constintMAXP=10;
constintMAXL=10;
constintMAXN=50;
constintMAXNODS=MAXP*MAXL+1;
constintbase=1e9;
intsize,
n,
a,
b;
inttrie[MAXNODS][MAXN];
intqueu[MAXNODS],suffix[MAXNODS];//suffix可以为每一个trie树结点标记前缀
booldanger[MAXNODS],visited[MAXNODS];
charletter[MAXP+10];
intcounter[2][MAXNODS][21],ans[21];//一个数用个int来存
mapdic;
voidBuild_Trie(){//按照一般方法构建trie树
intt,
len,
p=0;
len=strlen(letter);
for(inti=0;it=dic[letter[i]];
if(trie[p][t]==0)trie[p][t]=++size;
p=trie[p][t];
if(danger[p])break;//新单词的某一子串为危险单词
}
danger[p]=true;//对每个单词标记为危险结点
}
voiddebug()
{//对有向图的拓扑来打印出有效信息
memset(visited,0,sizeof(visited));
queueque;
que.push(0);
visited[0]=true;
while(!
que.empty()){
intcur=que.front();
que.pop();
printf("%c%d:
",danger[cur]?
'!
':
'',cur);
for(inti=0;iif(trie[cur][i]){
printf("%d(%c)",trie[cur][i],'a'+i);
if(!
visited[trie[cur][i]]){
que.push(trie[cur][i]);
visited[trie[cur][i]]=true;
}
}
}
printf("\n");
}
printf("\n\n");
}
voidBuild_Graph(){
inthead=1,//从根结点的第一个孩子还是广搜
tail=0;
queu[0]=0;
for(inti=0;i//根节点所有子节点的后缀结点均为根节点
while(head<=tail){
//该结点和其后缀结点是完全等效的,这样就可以在trie树中能够从树根结点开始已边为状态转移不断进行结点转移
danger[queu[head]]|=danger[suffix[queu[head]]];//后缀结点为危险节点,该节点也为危险节点
if(!
danger[queu[head]]){
for(inti=0;iif(trie[queu[head]][i]==0)trie[queu[head]][i]=trie[suffix[queu[head]]][i];
//如果不存在i孩子,则指向后缀结点的i孩子
else{
queu[++tail]=trie[queu[head]][i];
suffix[queu[tail]]=trie[suffix[queu[head]]][i];//计算后缀结点
}
}
}
++head;
}
}
voidadd(int*p,int*q){
if(p[0]for(intk=1;k<=p[0];k++){
p[k]+=q[k];
p[k+1]+=(p[k]/base);
p[k]%=base;
}
if(p[p[0]+1])p[0]++;//是否产生高位进位
}
voidbfs(intnode){
if(visited[node])return;
visited[node]=true;
for(inti=0;iif(!
danger[trie[node][i]]){
add(counter[a][trie[node][i]],counter[b][node]);
bfs(trie[node][i]);
}
}
}
voidbfs_ans(intnode){
if(visited[node])return;
visited[node]=true;
add(ans,counter[a][node]);//走m步后累加每个结点的个数
for(inti=0;idanger[trie[node][i]])bfs_ans(trie[node][i]);
}
intmain(){
//freopen("pku.txt","r",stdin);
//n=0;//字母表的数目
//for(inti=0;i<26;i++)dic['a'+i]=i;
//while(scanf("%s",letter)!
=EOF){
//for(inti=0;letter[i]!
='\0';i++)if(letter[i]-'a'>n)n=letter[i]-'a';
//Build_Trie();
//}
//n++;
//debug();
//Build_Graph();
//debug();
//return0;
intp,
m,
ch,
i;
memset(danger,0,sizeof(danger));
memset(trie,0,sizeof(trie));//注意初始化,既可以表示该结点未利用也可以表示指向trie树树根
scanf("%d%d%d\n",&n,&m,&p);
for(i=0;ifor(i=0;idebug();
Build_Graph();
debug();
a=1,b=0;
counter[1][0][0]=counter[1][0][1]=1;
for(i=0;iswap(a,b);//交换构成滚动数组
memset(visited,0,sizeof(visited));
memset(counter[a],0,sizeof(counter[a]));
bfs(0);
}
memset(visited,0,sizeof(visited));
memset(ans,0,sizeof(ans));
bfs_ans(0);
printf("%d",ans[ans[0]]);
for(i=ans[0]-1;i>0;i--)printf("%.9d",ans[i]);
printf("\n");
return0;
}
三、Trie图的改进
再看一道例题:
【例4】不良单词过滤器(题目来源:
Ural1269)
【题目描述】给出一个词典,其中的单词为不良单词。
再给出一段文本,文本的每一行可能是除chr(0),chr(10),chr(13)外的任何字符。
若文本中有不良单词,找出文本中不良单词第一次出现的位置,若没有,输出一行“Passed”。
【输入(标准输入)】第一行为一个整数n(1<=n<=10000),表示不良单词的个数。
接下来n行是词典。
词典的大小不超过100KB,每个不良单词的长度不超过10000。
下面一行为一个整数m,表示文本的行数。
接下来m行是文本。
文本的大小不超过900KB。
【输出(标准输出)】若文本中有不良单词,输出一行两个整数,表示不良单词第一次出现的行和列,用一个空格隔开。
若文本中无不良单词,输入一行“Passed”。
【样例输入】
2
rob
Problem
1
InternetProblemSolvingContest
【样例输出】
110
【注意】样例中“第一次出现”的不良单词是Problem而不是rob,虽然rob比Problem先结束。
【时间限制】1s。
【内存限制】5000KB。
【分析】乍一看,这道题与例1不是一模一样的吗?
其实不然。
与例1相比,这道题的字符集大得多,如果直接建trie图,从每个结点出发要建253条边,而结点数最多为100000,严重超内存。
试想一下,如果要做一个汉字的多模式匹配系统,岂不是要从每个结点出发建几千几万条边呢?
所以,为解决此问题,trie图的改进势在必行。
我们看到,在本题中,算法的瓶颈在于从每个结点出发的边数。
那么我们自然会想到:
一定要存储所有的边吗?
答案是否定的。
Trie树中的边自然是要存储的,但新建的边则不必存储。
如果不存储新建的边,那么如何实现状态间的转移呢?
我们用一个函数child(x,c)来获得结点x的c孩子。
函数内部的程序其实完全是按照加边的原则编写的:
如果x本来就有c孩子,那么就返回这个孩子;如果x没有c孩子,根据加边的原则,函数应该返回x的后缀结点的c孩子,也就是令x为它的后缀结点,重新执行函数。
如果x变成了根结点仍然没有c孩子,同样根据加边的原则,函数的返回值就应该是根结点本身。
经过这样的处理,算法的空间复杂度由O(L1a)降到了O(L1),对于本题来说是足够低的了。
但是,由于child函数的执行时间的不确定性,我们对算法的时间复杂度产生了疑问。
其实,算法的时间复杂度为O(L1+L2),数量级并没有受到影响,只是增加了一点常数系数。
为什么呢?
显然,在调用child(x,c)的时候,只有当x没有c孩子,需要重复执行child函数时运行时间才会增加。
我们分别讨论增加的这点时间对建图过程和文本检查过程所需时间的影响:
✧建图过程:
由于我们并不存储一个结点的所有孩子指针,所以建图的过程其实就是求每个结点的后缀结点的过程。
若b是trie树中a结点的一个孩子,那么b的后缀结点的深度至多比a的后缀结点大1。
如果把trie树中某条路径上的结点的后缀结点的深度排成一个数列,那么相邻两项中,后一项减一项的差一定小于等于1。
当后一项减前一项的差小于1时,child函数就会被重复执行。
但是,由于数列增长是缓慢的,child函数的重复执行的次数与trie树的深度之差的
 升级会员
升级会员 