word版本hslogic立体图像编码解码.docx
《word版本hslogic立体图像编码解码.docx》由会员分享,可在线阅读,更多相关《word版本hslogic立体图像编码解码.docx(15页珍藏版)》请在冰豆网上搜索。
word版本hslogic立体图像编码解码
立体图像编码解码MATLAB程序设计说明文档
1.系统总体说明
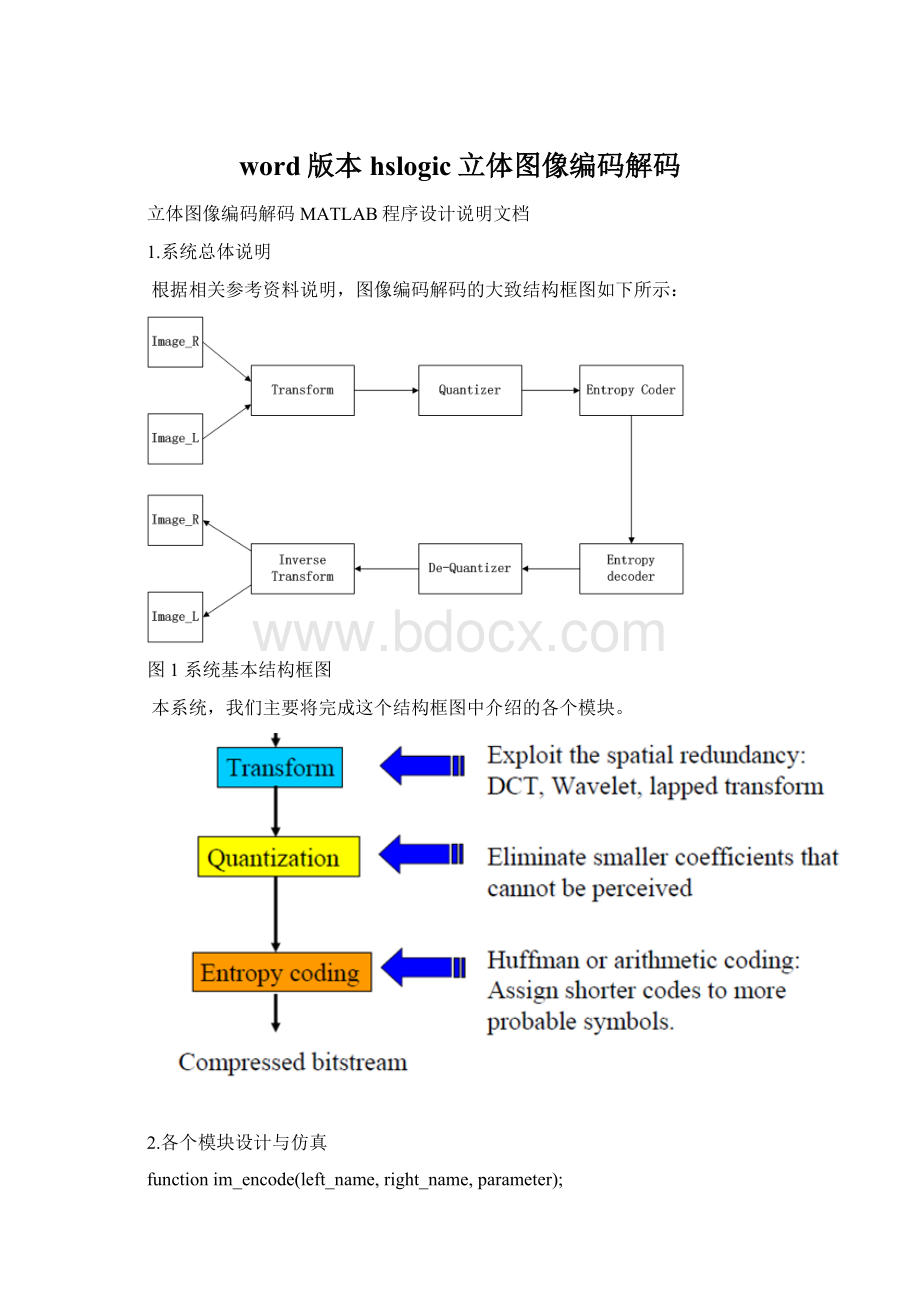
根据相关参考资料说明,图像编码解码的大致结构框图如下所示:
图1系统基本结构框图
本系统,我们主要将完成这个结构框图中介绍的各个模块。
2.各个模块设计与仿真
functionim_encode(left_name,right_name,parameter);
发送端的说明
2.1获得左右两个图像
·MATLAB代码
imag_L=imread('stereo_images/corridor1.pgm');
imag_R=imread('stereo_images/corridor2.pgm');
figure
(1);
subplot(121),imshow(imag_L);title('left');
subplot(122),imshow(imag_R);title('right');
·仿真效果
图2左右眼睛看到的图像
·代码说明
通过读取两个图片,来模拟人两个眼睛所看到的图像。
2.2Transform模块
这个模块主要使用DCT变换,但是这里设计到一个问题,就是将两个图片信号变为一路信号的问题。
就本课题而言,这里有以下几个方法实现;
·由于这两个图片是双目信号,所以可以先进行立体匹配得到一个图片,然后再接收端分解成两个双目图片;
·由小波分解进行融合得到一路信号,然后在接收端进行反变换,但是这种做法也较复杂。
·进行图片的采样处理,对两个图片进行间隔采样,然后在接收端进行内插得到原图像,这种方法比较简单,本模块采用这个方法。
其代码如下所示:
[R,L]=size(imag_L);
fori=1:
R
forj=1:
L
ifmod(i+j,2)==0
image(i,j)=imag_L(i,j);
else
image(i,j)=imag_R(i,j);
end
end
end
2.3DCT变换
我们在这里使用MATLAB内部的dct2函数。
这里就不多做介绍了。
其仿真结果如下所示:
其代码如下所示:
DCT_out=dct2(image);
2.4ZIGZAG算法
其基本原理如下所示:
通过这个方法,我们可以将一个图像的二维数据变为一个串行的数据流。
其对应的代码如下所示:
function[y]=toZigzag(x)
%transformamatrixtothezigzagformat
[rowcol]=size(x);
ifrow~=col
disp('toZigzag()fails!
!
Mustbeasquarematrix!
!
');
return
end
y=zeros(row*col,1);
count=1;
fors=1:
row
ifmod(s,2)==0
form=s:
-1:
1
y(count)=x(m,s+1-m);
count=count+1;
end;
else
form=1:
s
y(count)=x(m,s+1-m);
count=count+1;
end
end
end
ifmod(row,2)==0
flip=1;
else
flip=0;
end
fors=row+1:
2*row-1
ifmod(flip,2)==0
form=row:
-1:
s+1-row
y(count)=x(m,s+1-m);
count=count+1;
end
else
form=row:
-1:
s+1-row
y(count)=x(s+1-m,m);
count=count+1;
end;
end;
flip=flip+1;
end
2.5量化模块
μ律压扩的数学解析式:
其中:
x为输入信号的归一化值;y为压扩后的信号。
对话音信号编码,常采用μ=255,这样适量化信噪比改善约24dB。
由于上式的是一个近似的对数关系,因此也称为近似对数压缩律,其15折线:
近似律:
表3-2U律压缩和15折线的特性对比
μ律(m-Law)压扩主要用在北美和日本等地区的数字电话通信中。
m为确定压缩量的参数,它反映最大量化间隔和最小量化间隔之比,通常取100≤m≤500。
由于m律压扩的输入和输出关系是对数关系,所以这种编码又称为对数PCM。
A律(A-Law)压扩主要用在欧洲和中国大陆等地区的数字电话通信中。
A为确定压缩量的参数,它反映最大量化间隔和最小量化间隔之比。
A律压扩的前一部分是线性的,其余部分与μ律压扩相同。
15折线特性给出的小信号的信号量噪比约是13折线特性的两倍。
但是,对于大信号而言,15折线特性给出的信号量噪比要比13折线特性时稍差。
在保证小信号的量化间隔相等的条件下,均匀量化需要11比特编码,而非均匀量化只要7比特就够了。
其对应的待明如下所示:
functionypcm=mulaw(yn)
x=yn;
s=sign(x);
x=abs(x);
ypcm=zeros(length(x),1);
%进行基于15折线的分段映射
fori=1:
length(x)
ifx(i)<1/255%序列值位于第1折线
ypcm(i)=255/8*x(i);
elseifx(i)<3/255%序列值位于第2折线
ypcm(i)=255/16*x(i)+1/16;
elseifx(i)<7/255%序列值位于第3折线
ypcm(i)=255/32*x(i)+5/32;
elseifx(i)<15/255%序列值位于第4折线
ypcm(i)=255/64*x(i)+17/64;
elseifx(i)<31/255%序列值位于第5折线
ypcm(i)=255/128*x(i)+49/128;
elseifx(i)<63/255%序列值位于第6折线
ypcm(i)=255/256*x(i)+129/256;
elseifx(i)<127/255%序列值位于第7折线
ypcm(i)=255/512*x(i)+321/512;
else%序列值位于第8折线
ypcm(i)=255/1024*x(i)+769/1024;
end
end
ypcm=ypcm.*(2^7);
ypcm=floor(ypcm);
ypcm=ypcm.*s;
2.6编码模块
发送的最后我们需要将量化后的数据进行压缩,得到二进制比特率进行发送,这里我们使用huffman编码。
Huffman编码的基本原理如下所示:
哈夫曼编码是用于数据文件压缩的一个十分有效的编码方法,其压缩率通常在20%~90%之间。
哈夫曼编码算法使用字符在文件中出现的频率表来建立一个0,1串,以表示各个字符的最优表示方式。
它是一种编码方式,哈夫曼编码是可变字长编码(VLC)的一种。
Huffman于1952年提出一种编码方法,该方法完全依据字符出现概率来构造异字头的平均长度最短的码字,有时称之为最佳编码,一般就叫作Huffman编码。
以哈夫曼树─即最优二叉树,带权路径长度最小的二叉树,经常应用于数据压缩。
在计算机信息处理中,“哈夫曼编码”是一种一致性编码法(又称"熵编码法"),用于数据的无损耗压缩。
这一术语是指使用一张特殊的编码表将源字符(例如某文件中的一个符号)进行编码。
这张编码表的特殊之处在于,它是根据每一个源字符出现的估算概率而建立起来的(出现概率高的字符使用较短的编码,反之出现概率低的则使用较长的编码,这便使编码之后的字符串的平均期望长度降低,从而达到无损压缩数据的目的)。
这种方法是由David.A.Huffman发展起来的。
例如,在英文中,e的出现概率很高,而z的出现概率则最低。
当利用哈夫曼编码对一篇英文进行压缩时,e极有可能用一个位(bit)来表示,而z则可能花去25个位(不是26)。
用普通的表示方法时,每个英文字母均占用一个字节(byte),即8个位。
二者相比,e使用了一般编码的1/8的长度,z则使用了3倍多。
倘若我们能实现对于英文中各个字母出现概率的较准确的估算,就可以大幅度提高无损压缩的比例。
三、Huffman编码的步骤
设信源X的信源空间为:
其中,
,现用二进制对信源X中的每一个符号
(i=1,2,…N)进行编码。
根据变长最佳编码定理,Huffman编码步骤如下:
(1)将信源符号xi按其出现的概率,由大到小顺序排列。
(2)将两个最小的概率的信源符号进行组合相加,并重复这一步骤,始终将较大的概率分支放在上部,直到只剩下一个信源符号且概率达到1.0为止;
(3)对每对组合的上边一个指定为1,下边一个指定为0(或相反:
对上边一个指定为0,下边一个指定为1);
(4)画出由每个信源符号到概率1.0处的路径,记下沿路径的1和0;
(5)对于每个信源符号都写出1、0序列,则从右到左就得到非等长的Huffman码。
其对应的代码如下所示:
function[compression,dict]=huffman_module(image);
s=image;
%entropy
p=hist(s,length(s));
idx=find(p~=0);
prob=p(idx)/length(s);
entropy=-prob*log2(prob)';
%redundancy
entropymax=log2(length(prob));
redundancy=(entropymax-entropy)/entropymax;
reff=sort(s);
ref2=reff(2:
end);
ref=reff(1:
end-1);
chg=ref2-ref;
idx2=find(chg~=0);
sig=ref2(idx2);
symbols=[ref
(1);sig];
%huffmantable
set(0,'RecursionLimit',2000);
[dict,avglen]=huffmandict(symbols,prob);
%%huffmanencoder
compression=huffmanenco(s,dict);
以上就是发送端的基本过程。
其对应的算法流程图如下所示:
3.各个模块设计与仿真
function[imag_LS2,imag_RS2,image]=im_decode(bitstream,dict);
接收端的说明
接收端其主要流程和发送端相反,这里我们就不多做介绍了。
其原理如下所示:
3.系统总体仿真说明
系统的仿真结果如下所示:
读入两个图片
DCT变换值
量化值
压缩比特流
最后接收到的双目图片。
最后我们可以得到PSNR值为
 升级会员
升级会员 