数据库实验二报告.docx
《数据库实验二报告.docx》由会员分享,可在线阅读,更多相关《数据库实验二报告.docx(15页珍藏版)》请在冰豆网上搜索。
数据库实验二报告
《数据库原理与应用》实验报告
实验名称:
数据定义和查询
班级:
学号:
姓名:
一、实验目的
1、掌握使用SQL语句创建和删除数据表,创建各种完整性约束。
2、掌握使用SQL语句修改表的结构。
3、掌握查询语句的使用方法,重点掌握连接查询和嵌套查询。
二、实验过程
1.使用SQL语句建立4个关系,如下:
供应商表S(Sno,Sname,City)
零件表P(Pno,Pname,Color,Weight)
工程项目表J(Jno,Jname,City)
供应情况表SPJ(Sno,Pno,Jno,QTY)
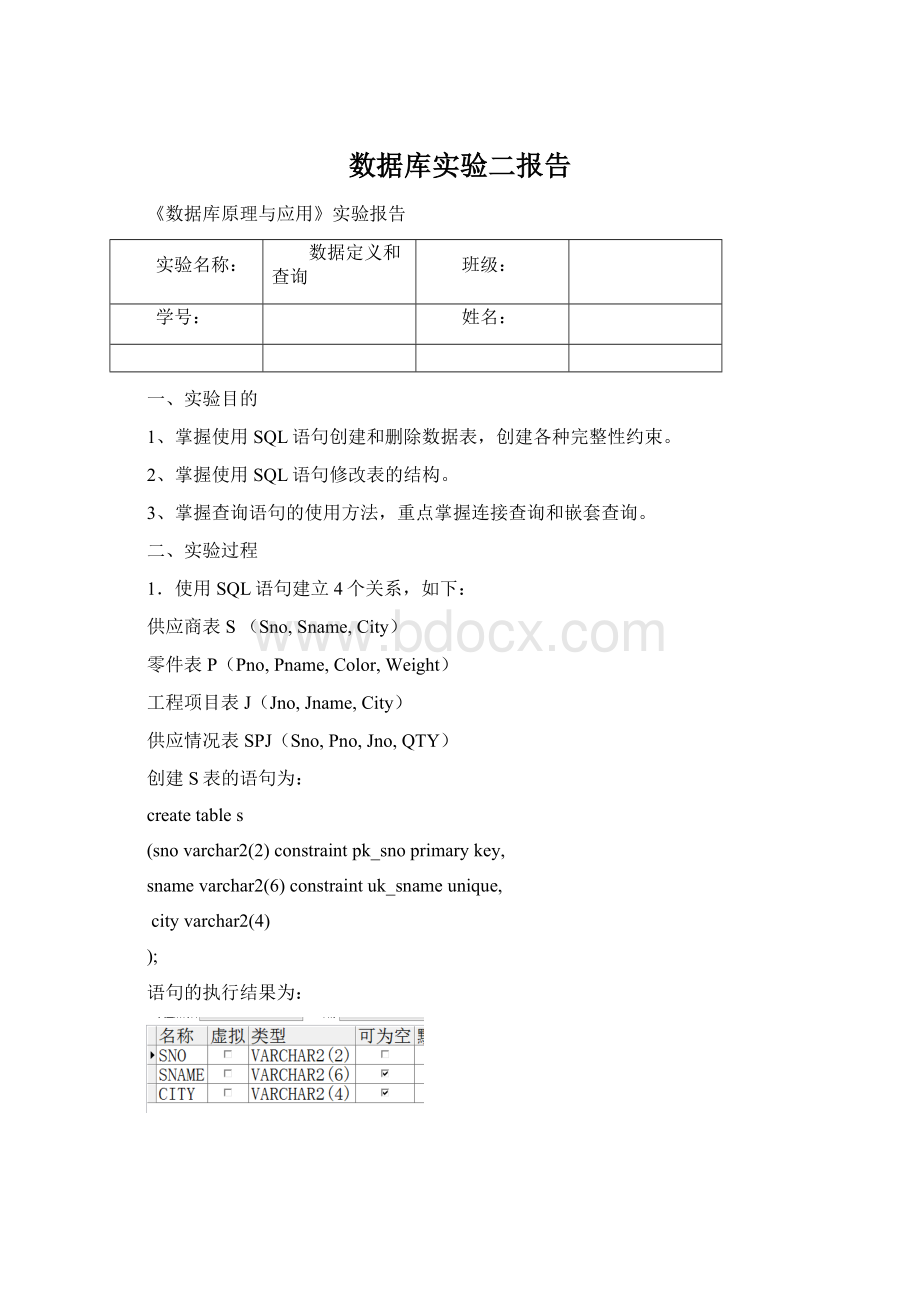
创建S表的语句为:
createtables
(snovarchar2
(2)constraintpk_snoprimarykey,
snamevarchar2(6)constraintuk_snameunique,
cityvarchar2(4)
);
语句的执行结果为:
创建P表的语句为:
createtablep
(pnovarchar2
(2)constraintpk_pnoprimarykey,
pnamevarchar2(6),
colorvarchar2
(2),
weightnumberconstraintck_weightcheck(weight>=1andweight<=50)
);
语句的执行结果为:
创建J表的语句为:
createtablej
(jnovarchar2
(2)constraintpk_jnoprimarykey,
jnamevarchar2(8)notnullconstraintuk_jnameunique,
cityvarchar2(4)
);
语句的执行结果为:
创建SPJ表的语句为:
createtablespj
(snovarchar2
(2)constraintfk_snoforeignkeyreferencess(sno),
pnovarchar2
(2)constraintfk_pnoforeignkeyreferencesp(pno),
jnovarchar2
(2)constraintfk_jnoforeignkeyreferencesj(jno),
qtyNUMBER(5),
primarykey(sno,pno,jno)
);
语句的执行结果为:
2.用SQL语句完成以下操作:
(1)给S表增加Sphone和Semail两个属性列,分别用来存放供应商的联系电话和电子信箱。
语句:
altertablesaddsphonevarchar2(11),
altertablesaddsemailvarchar2(20)
执行结果:
(2)删除Jname属性列取值唯一的约束。
语句:
altertablejdropunique(jname)
执行结果:
(3)将QTY属性列的数据类型修改为Integer型。
语句:
altertablespjmodifyqtyinteger
执行结果:
(4)删除S表中的属性列Semail
语句:
altertablesdropcolumnsemail
执行结果:
3.在J表的Jname属性列上创建唯一性索引。
语句:
createuniqueindexjjnameonj(jname)
执行结果:
4.使用EXP命令将创建的四张数据表导出。
5.在创建的S,P,J和SPJ表中完成以下查询:
(1)查询所有供应商所在的城市。
语句:
selectcityfromj
执行结果:
(2)查询零件重量在10-20之间(包括10和20)的零件名和颜色。
语句:
selectpname,colorfrompwhereweight>=10andweight<=20
执行结果:
(3)查询工程项目的总个数。
语句:
selectcount(jno)fromj
执行结果:
(4)查询所有零件的平均重量。
语句:
selectavg(weight)fromp
执行结果:
(5)查询供应商S3供应的零件号。
语句:
selectpnofromspjwheresno='S3'
执行结果:
(6)查询各个供应商号及其供应了多少类零件。
语句:
selectsno,count(pno)fromspjgroupbysno
执行结果:
(7)查询供应了2类以上零件的供应商号。
语句:
selectsno,count(pno)fromspjgroupbysnohavingcount(pno)>2
执行结果:
(8)查询零件名以“螺”字开头的零件信息。
语句:
select*frompwherepnamelike'螺%'
执行结果:
(9)查询工程项目名中最后一个字为“厂”字的工程项目所在的城市。
语句:
selectcityfromjwherejnamelike'%厂'
执行结果:
(10)查询给每个工程供应零件的供应商的个数。
语句:
selectjno,count(sno)fromspjgroupbyjno
执行结果:
(11)查询供应数量在1000—2000之间(包括1000和2000)的零件名称。
语句:
selectpname,sum(qty)fromp,spjwherep.pno=spj.pnogroupbypnamehavingsum(qty)between1000and2000
执行结果:
6.将实验一中创建的三张表student,course和sc用IMP命令导入,在导入的三张表中完成以下查询:
(1)查询“信息管理与信息系统”专业学生的姓名和年龄。
语句:
selectsname,2017-to_char(birth,'yyyy')as年龄fromSTUDENTwheremajor='信息管理与信息系统'
执行结果:
(2)查询107号课程的最高成绩。
语句:
selectmax(grade)fromSCwherecno='107'
执行结果:
(3)统计每个专业的学生人数。
语句:
selectmajor,count(sno)fromSTUDENTgroupbymajor
执行结果:
(4)统计每门课程的修课人数和考试最高分。
语句:
selectcname,count(sno),max(grade)fromCOURSE,SCwhereo=ogroupbycname
执行结果:
(5)查询总成绩超过200分的学生,要求列出学号和总成绩。
语句:
selectsno,sum(grade)fromSCgroupbysnohavingsum(grade)>200
执行结果:
(6)查询姓名为田丕龙的学生所学课程的课程名与学分。
语句:
selectsname,cname,creditfromstudent,course,scwherestudent.sno=sc.snoando=oandsname='田丕龙'
执行结果:
(7)查询选修课程号为“160”或“304”的学生的学号。
语句:
selectsnofromscwherecno='160'unionselectsnofromscwherecno='304'
执行结果:
(8)查询选修了课程号为“160”和“304”的学生的学号。
语句:
selecta.snofromsca,scbwherea.sno=b.snoando='160'ando='304'
执行结果:
(9)查询学习全部课程的学生姓名。
语句:
selectdistinctsnamefromstudent,scwherestudent.sno=sc.sno
执行结果:
(10)查询1994年1月1日以前出生的学生的姓名和专业。
语句:
selectsname,major,birthfromstudentwhereto_char(birth,'yyyymmdd')<19940101
执行结果:
(11)查询选修了“大学英语4”课程且成绩在90分以上的学生姓名。
语句:
selectstudent.sname,ame,sc.gradefromstudent,course,sc
wherestudent.sno=sc.snoando=oandcname='大学英语4'andgrade>90
执行结果:
(12)查询选修了5门以上课程的学生学号和姓名。
语句:
selectstudent.sno,student.sname,count(o)
fromstudent,scwherestudent.sno=sc.snogroupbystudent.sname,student.snohavingcount(o)>5
执行结果:
(13)查询未选修“政治经济学”课程的学生情况。
语句:
selectdistinctstudent.*fromstudent,course,sc
wherestudent.sno=sc.snoando=oandcname!
='政治经济学'
执行结果:
(14)统计102和378号课程的选课人数及平均成绩。
语句:
selectcno,count(sno),avg(grade)fromscwherecno='102'groupbycno
union
selectcno,count(sno),avg(grade)fromscwherecno='378'groupbycno
执行结果:
(15)查询比所有“信息管理与信息系统”专业学生年龄都大的学生。
语句:
selectsno,sname,sex,nation,political,college,major,trunc((sysdate-birth)/365)age
fromstudent
wheretrunc((sysdate-birth)/365)>all
(selecttrunc((sysdate-birth)/365)age
fromstudent
wheremajor='信息管理与信息系统')
andmajor!
='信息管理与信息系统'
执行结果:
(16)将“计算机科学与技术”专业的学生按出生时间先后排序。
语句:
select*fromstudentwheremajor='计算机科学与技术'orderbybirth
执行结果:
三、实验总结
在实验过程中,我学到了很多。
定义基本表的时候注意列级完整性约束和表级完整性约束。
在查询的过程中,先看需要查询的属性列是否都在同一个表中,如果不在同一张表中,就要使用连接查询,有时也要注意,当两个表都出现相同的列名时,引用时必须加上表的前缀,用来区分。
如果查询结果中出现取值相同的元组,可以用distinct取消。
使用通配符时,当要查询的字符串本身就含有%和/时,就要用escape对通配符进行转义。
当涉及到出生日期或者是年龄的比较时,要用to_char函数对birth类型进行转化,再进行比较。
我认为嵌套查询有一定难度,以后需要多加练习。
这次实验有一个问题使我疑惑不解。
在语句
“selectstudent.sno,student.sname,count(o)fromstudent,scwherestudent.sno=sc.snogroupbystudent.sname,student.snohavingcount(o)>5”中,Groupby后必须加上“student.sname,student.sno”,而不能只加“student.sname”,或者是只加“student.sno”。
 升级会员
升级会员 