统计制表.docx
《统计制表.docx》由会员分享,可在线阅读,更多相关《统计制表.docx(23页珍藏版)》请在冰豆网上搜索。
统计制表
第三讲:
资料的统计描述
(一):
统计制表
描述性统计概述
描述性统计主要对统计数据的结构和总体情况进行描述,一般并不深入了解统计数据的内部规律。
主要分三方面的内容:
Reports(报表模块)、DescriptiveStatistics(描述统计)Tables(定制表格)。
描述性统计是统计分析和统计推断的基础,在以后的每个过程中几乎都会用到。
本讲将主要介绍Reports与Tables模块中的统计制表
1、Reports
该命令共包含了4个过程,分别是OLAPCubes(OnlineAnalyticalProcessing在线分析),CaseSummaries(案例摘要),ReportSummariesinRows(行摘要),ReportSummariesinColumns(列摘要)。
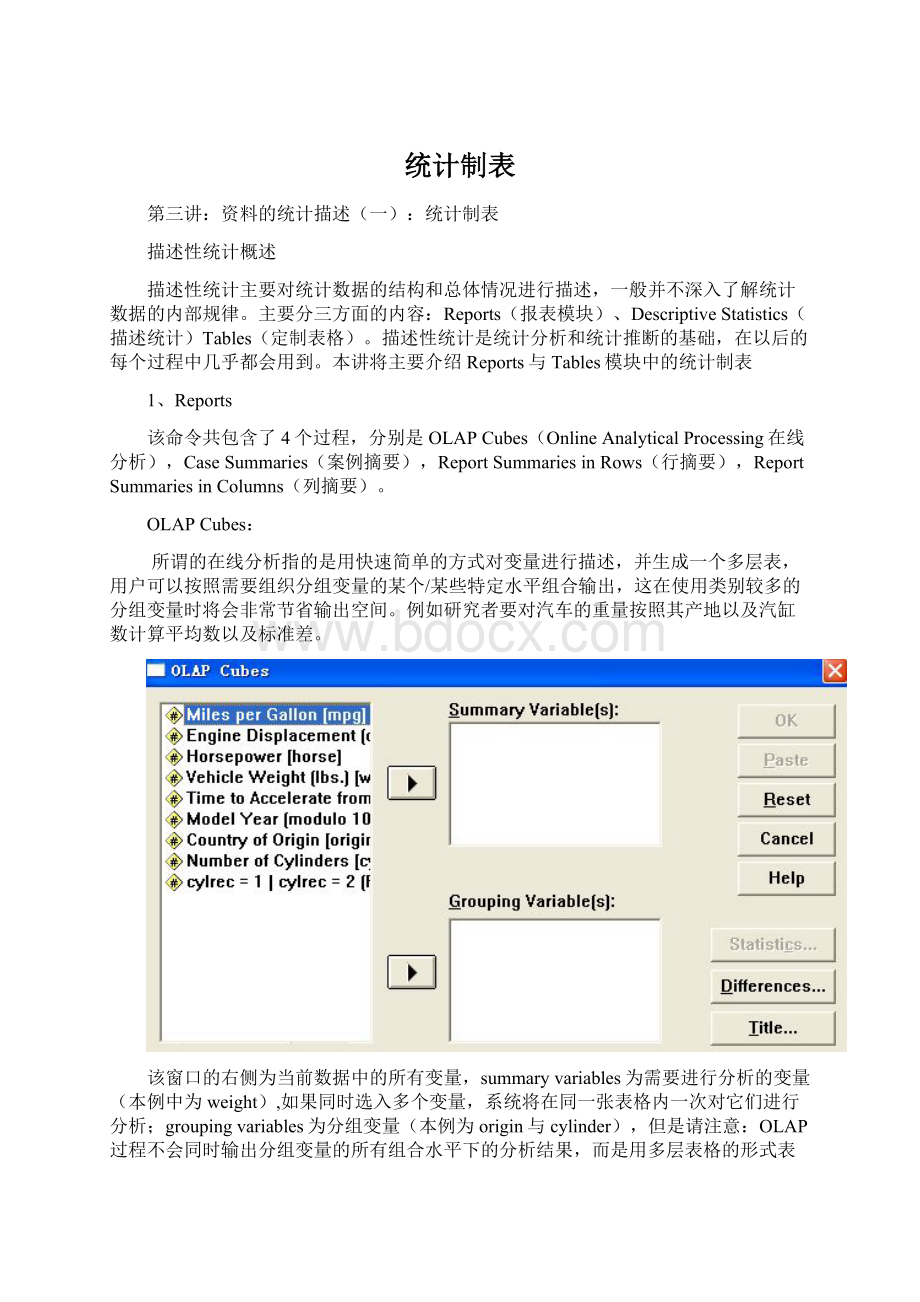
OLAPCubes:
所谓的在线分析指的是用快速简单的方式对变量进行描述,并生成一个多层表,用户可以按照需要组织分组变量的某个/某些特定水平组合输出,这在使用类别较多的分组变量时将会非常节省输出空间。
例如研究者要对汽车的重量按照其产地以及汽缸数计算平均数以及标准差。
该窗口的右侧为当前数据中的所有变量,summaryvariables为需要进行分析的变量(本例中为weight),如果同时选入多个变量,系统将在同一张表格内一次对它们进行分析;groupingvariables为分组变量(本例为origin与cylinder),但是请注意:
OLAP过程不会同时输出分组变量的所有组合水平下的分析结果,而是用多层表格的形式表现,在默认情况仅仅显示合计的情况;同时origin与cylinder两个变量均未缺失的case才可进入最终分析。
Statistics子对话框中提供了几种常用的统计量,可根据研究目的选择合适的数值描述指标:
Differences子对话框用于计算不同汇总变量间、同一变量在各组间的差值或百分比:
定义要所需要的统计描述项目后,点击OK:
上表为进入分析的记录汇总,可见在所有的406条记录中,共有1条记录因为有缺失值而未能入选。
下表即为在线分析结果,可见总共405辆汽车的总重量为1204910磅,均数为2975.09磅,标准差为843.546磅。
注意该表仅仅是汇总结果,实际为一个多层表,请双击该表进入编辑状态后,可以按照产地和汽缸数的取值不同进行组合,得到不同的weight平均值和标准差。
如果研究者想进一步了解欧洲车与日本车在车重的差异,可以使用differences子对话框指定typeofdifferences为arithmeticdiffernce,differencesbetweengroupsofcases中的grouping为origin,category为2、minus为3,点击pairs按钮,OK即可得到下表:
似乎和上表相比没有任何差别,但是双击该表进入编辑状态,在countryorigin的下拉选项中多出了European-Japanese选项,选择它即可。
请注意该表中的每一个指标都是单独计算的。
CaseSummaries:
与OLAP过程可以产生自定义的简洁分层表格不同的是,该命令可以将指定分组变量的所有组合全部列出。
仍然以上题为例,对车重按照产地与汽缸数分类统计其平均数与标准差。
该对话框与OLAP相似,将要分析的weight移入variables中,cylinder与origin移入groupingvariables中;在statistics中选择需要的指标,点击OK即可。
(最好将displaycases前的小勾去掉,使得结果输出较为简洁)。
ReportSummariesinRows
该命令是专门用于生成复杂表格的,而且其输出格式为.txt格式。
例如研究者想将系统自带数据Breastcancersurvey观测对象,按照淋巴结是否转移、组织学分级分别统计患者的生存时间与肿瘤大小的平均数、标准差;并统计在不同组织学分级中,计算肿瘤大小超过1.5公分所占的比例。
如果通过前面介绍的命令,需要多步处理后才可以得到想要的结果;但是通过该命令可以仅仅运行一次就得到想要的结果。
Datacolumns为需要对其进行汇总的变量,breakcolumns为分组变量
分别点击datacolumns中的time与size,定义其format,窗口如下:
同理也可以在breakcolumns中定义的淋巴结转移情况、组织学分级;另外可以定义如何对这两个分组变量所对应的time和size进行统计描述:
定义结束后直接点击ok,系统运行后得出结果表格如下(节选),如果需要修改表格中的数据可以直接双击该表格编辑。
ReportSummariesinColumns
该过程与reportsummariesinrows十分相似;但是输出的结果更加紧凑。
例如上述例题,改用本命令:
其操作步骤同reportsummariesinrows,分别将time与size移入datacolumns,再将淋巴节转移以及组织学分级移入breakcolumns;
与reportsummariesinrows不同的是在上述窗口中多了:
inserttotal按钮,以及summary按钮被放在datacolumns框中。
Inserttotal可以在输出的表格中加入一个名为total的汇总变量。
接着我们可以对datacolumns中的pathsize、time作汇总设定;点击summary,分别设定size为超过1.5公分,time为取平均值:
在format中设定其中文标目以及对其方式:
同样对breakcolumns中的两个分组变量也做类似设定,完成上述设定后点击OK得到结果:
*试对系统自带文件cars按不同产地和汽缸数计算汽车平均功率,以及加速至60mph所需时间的均数以及标准差;并给出在不同产地中该项时间为20秒以上的车型所占比例。
*试对系统自带文件cars按不同产地和汽缸数计算汽车平均功率以及平均车重;并计算平均车重与平均输出动力的比值。
2、Tables
上述Reports命令中的汇总设置主要针对定量资料(从其statistics或summary选项中可以看出主要是计算平均数、标准差、最大值、最小值、偏度系数、峰度系数等专门针对计量资料的统计指标);而很多时候我们将要对分类变量进行汇总并制定相应表格,这时repots命令就无能为力了。
Tables命令正是用于分类变量的统计汇总和分类变量的统计制表。
BasicTables:
该命令为最基本的tables过程,但是已经可以对分类资料/计量资料(二者中选择一种)进行各种复杂的描述,只不过与tables中的其他命令相比较为basic而已;另外它还具有一个特点,可以按照研究者的需要定做适当的表格输出。
例如在某次高血压调查中,收集了患者的一些个人资料以及血压控制情况,详见高血压.sav。
某研究者想按照不同性别、文化程度、和肥胖程度计算高血压控制程度的频数分布;另外的研究者仅仅想了解轻度肥胖、文化程度为初中及以下的患者血压控制程度。
对话框中down为表格的横标目,across为表格纵标目;separatetables为分层变量(如果研究者仅仅想了解分组因素的某个水平的汇总情况,从而简化输出结果,可以考虑将原先down中的一些变量移入separatetables中)。
表格的输出的编排方式有两种:
allcombination[nested]嵌套式表格、eachseparately[stacked]分列式表格。
系统默认为嵌套式。
Statistics对话框为表格中的数据的统计方式,本例仅仅要了解频数分布情况,所以选择count。
Total中,可以选择在表格中加入合计栏/列。
接着我们定义以下如果表格中出现频数为0时应该如何显示,系统默认为空格;我们选择填0。
点击ok系统运行结果如下,当然也可以选择输出eachseparately[stacked]分列式表格:
该表为嵌套式表格,所有分组变量依次进入表格,后进入的嵌套在先进入变量的下一级。
如果研究者仅仅想按照各分组变量的单独汇总结果,可以选择分列式表格输出:
表格中将分别按照性别、文化程度、肥胖程度各自输出控制情况的频数分布。
另外研究者仅仅想了解轻度肥胖、文化程度为初中及以下的患者血压控制程度。
则可以选择使用分层表:
将肥胖程度与文化程度选入separatetables中,其他设置同前,点击ok,系统将输出如下表格:
该表格为分层表,可以双击该表格,选择需要的因素组合水平(本例中为轻度肥胖、文化程度为初中及以下),系统将给出针对性的表格:
GeneralTables:
Basictables过程已经为我们提供了良好的制表功能,但是还是有些不足;例如:
它只能分别对分类或计量资料作汇总,如果要同时对二者进行统计则无能为力;它不支持对多选题数据进行汇总。
为此SPSS提供了比basictables过程更强大的generaltables命令。
例如针对同一高血压疗效调查,研究者希望对不同文化程度与性别汇总下列信息:
A.血压控制的频数分布
B.输出患者年龄的均数与标准差
C.输出非药物控制措施的实施情况(非药物措施有饮食、运动、情绪和其他四种选项,一个患者可能同时选择其中的多种),包括频数和构成比。
如果将上述三个问题一一拆解可能需要不少的时间,而且容易在汇总过程中出错。
使用generaltables过程可以一次性解决三个问题,并将三部分结果输出在同一个表格中。
对话框中的rows为横标目,columns为纵标目,multresponse选项框为多选题定义框
在本例题中可以将性别、文化程度选入rows中(当然选入columns中也可以)作为分组依据;将血压控制情况、年龄、非药物控制措施(该变量存在于multresponse框中)选入columns中。
但是在入选非药物控制措施之前,要对该选项作设定:
先将setdefinition中的method1至method4全部选上,移入variablesinset中。
在下方的variablesarecodedas可以定义变量集中变量的取值:
dichotomies表示变量采用二分法(即所谓的二项分类),在之后的countedvalues中填入入选的变量值(例如本题中定义所有非药物措施中变量值为2的表示有采用本措施被系统选中);categories为多项分类法,如果采用本方法最好在分析开始前对变量进行适当编排(例如在医科大学研究生教育过程中要开设20门选修课,现要分析研究生最喜欢的3门选修课,如果将所有开设的研究生课程一一列出,然后在每门课程的变量取值中定义0为不喜欢,1为喜欢,则需要设定20个课程变量,而后再一一取值十分麻烦;可以考虑将每个同学的3次选择作为三个变量,录入数据时直接输入课程编码即可,这种处理方法就是多分类法)。
在本例中由于不同的观测对象可能采用的非药物疗法的种类数不同,例如有的采用两种,有的采用三种,有的一种都不采用,所以本题采用对每个非药物疗法进行二分类的方法进行编码。
在multresponsesets中显示多选题的变量名,可以单击该变量名进行修改,修改后点击save保存设置回到generaltables主对话框:
接着要对汇总的的变量(年龄、血压控制情况以及非药物疗法的采用情况)进行汇总统计量设定。
对于不同类型的变量(计量或分类)必须先制定类型。
Definescells用于分类变量(即血压控制),Issummarized则用于计量资料(年龄);根据题意分别通过editstatistics设定汇总统计量:
定义后可以点击OK系统输出下列表格:
该表格为分列式,即分组变量性别与文化程度分别并排列出;如果要得到嵌套式表格,必须将性别或文化程度中的某个移入layers中,并在输出结果中用pivotingtrays设定。
先在结果输出中用右键单击——spsspivottableobject——open,在出现的窗口中选择pivot——pivotingtrays。
系统将弹出以下对话框,其行与列的含义与前面的设置相同,将layers变量拖拽至column中即可。
需要解释的是“比例%”;原先它的含义为该数据占列合计的百分比;比如男性初中以下文化,调整饮食有11例,所占比例为31.4%(男性初中以下共有35人,其中有12人的血压控制情况为缺失,所以从血压控制情况计算处的合计人数只有7+6+10=23人;35人中采用调整饮食的有11人,占该人群比例的11/35=31.4%;由于同一个观测对象可能同时选择两种或多种方法,所以该列的比例之和超过100%)。
MultipleResponseTables:
该过程专门为多项选择题而设立。
例如对上述例题我们采用multipleresponsetables过程操作:
变量的放置同generaltables,与generaltables不同的是在multipleresponse中系统已经自动定义好多选题,并已经生成一个为nodrug的变量;另外该过程默认情况下就已经输出嵌套式表格,省去generaltables中的复杂转换过程。
但是该命令也有不足之处,那就是它只可以用于分类变量(因为多项选择本身就是分类结果),对于定量变量例如年龄等不再适用。
所以只要将性别与文化程度放入rows中,将血压控制情况与非药物控制措施放入columns中,点击statistics设定统计指标;在本例中仅仅需要计数(count)与行百分比(row%);表格输出是默认是nesting(嵌套式),而且不论行或列均以嵌套方式输出:
如果觉得没有必要对纵标目(columns)也按照嵌套式输出,则可以将nesting下columns前的勾去掉,得到如下表格:
TablesofFrequencies:
该过程的最大特点是在一张表格中为多个分类变量提供其频数分布情况,其功能较前面的几个过程相对较简单,但是其输出较为专一。
例如研究者要了解不同性别研究对象的婚姻情况、职业、收入级别、居住情况的频数分布情况,并给出百分比例和合计。
Frequenciesfor框中入选的是希望计算频数的变量(需要注意的是,入选变量的value最好相同,例如本例文件中对婚姻情况、职业、收入级别、居住情况均没有规定其value;因为它们间的value值必定不同,例如婚姻取值1为“未婚”、2为“已婚”,但是对于职业取值1和2时value并非“已婚”和“未婚”。
所以在使用该过程时,当变量间的value不同时最好不要对value作设定。
)Subgroups为分组变量,本例中为性别。
接着对frequenciesfor中的变量进行频数统计设定,点击statistics按钮,如上图。
依照题意将percents选上,同时也将total选上,分别定义其label。
设定结束后点击OK运行系统输出频数分布表如下:
表格的横标目为要统计频数变量的取值,所有变量共用相同的变量取值(这就是为什么在前面强调变量间的value最好相同的原因)。
*CustomTables:
自定义表格过程,其实它是一个直观的鼠标拖拽变量创建表格的过程,其最大的优点就是直观,只需要按照设想要求将变量拖拽到适当的横、纵标目位置即可,而且所有操作结果都可以快速预览,功能强大,相当于generaltables过程。
*MultipleResponseSets:
设定多选题;该过程对话框与generaltables中的多选题定义一样。
 升级会员
升级会员 