Eviews软件基本操作范本模板.docx
《Eviews软件基本操作范本模板.docx》由会员分享,可在线阅读,更多相关《Eviews软件基本操作范本模板.docx(11页珍藏版)》请在冰豆网上搜索。
Eviews软件基本操作范本模板
Eviews软件基本操作
一、工作文件及建立
(一)主窗口简介
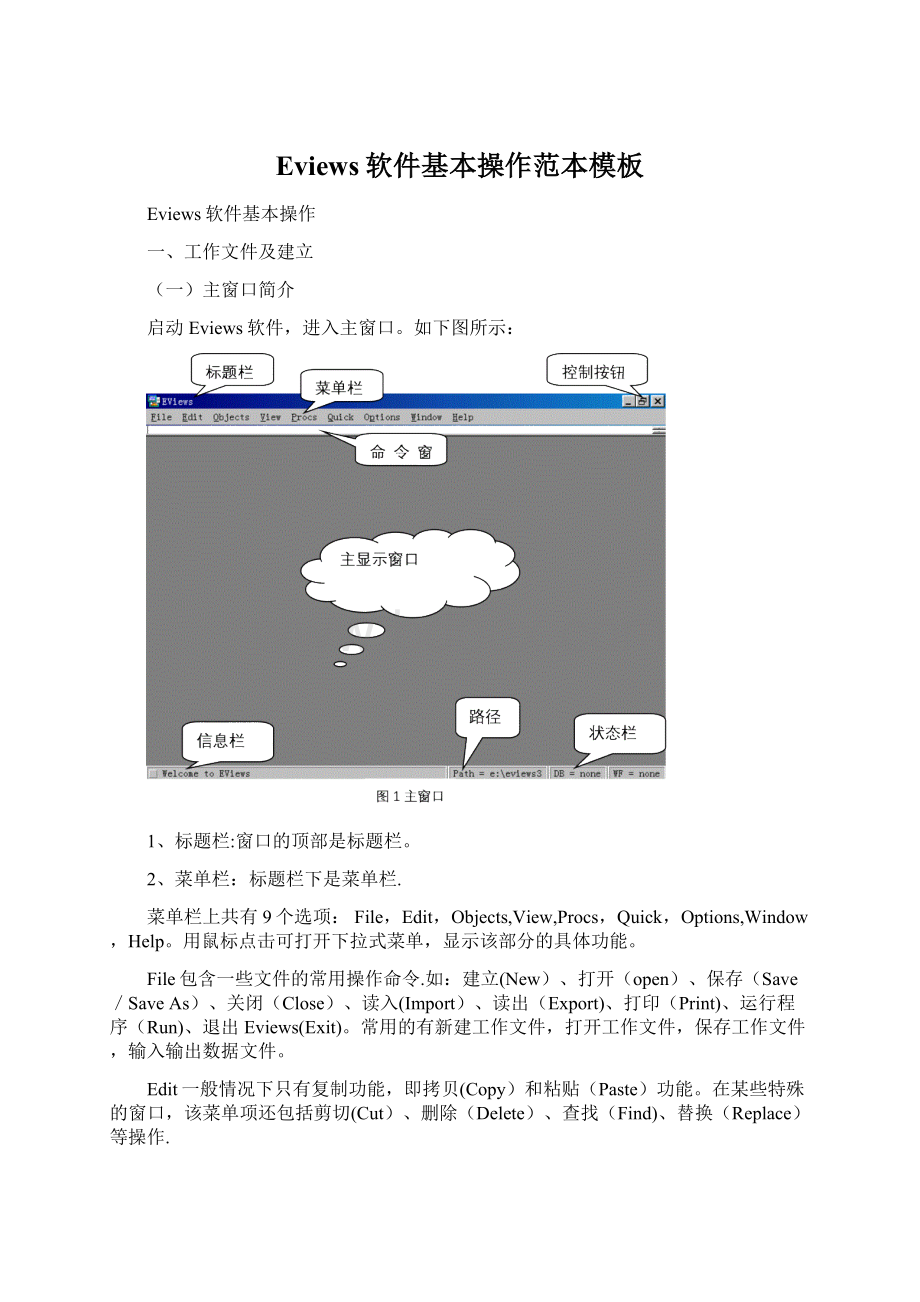
启动Eviews软件,进入主窗口。
如下图所示:
1、标题栏:
窗口的顶部是标题栏。
2、菜单栏:
标题栏下是菜单栏.
菜单栏上共有9个选项:
File,Edit,Objects,View,Procs,Quick,Options,Window,Help。
用鼠标点击可打开下拉式菜单,显示该部分的具体功能。
File包含一些文件的常用操作命令.如:
建立(New)、打开(open)、保存(Save/SaveAs)、关闭(Close)、读入(Import)、读出(Export)、打印(Print)、运行程序(Run)、退出Eviews(Exit)。
常用的有新建工作文件,打开工作文件,保存工作文件,输入输出数据文件。
Edit一般情况下只有复制功能,即拷贝(Copy)和粘贴(Paste)功能。
在某些特殊的窗口,该菜单项还包括剪切(Cut)、删除(Delete)、查找(Find)、替换(Replace)等操作.
objects提供有关对象的基本操作。
包括建立新对象(NewObjects)、从数据库获取使新对象(Fetch/UpdateFromDB)、将工作文件中的对象存储到数据库(StoretoDB)、复制对象(CopySelected)、重命名(Rename)、删除(Delete)。
View其功能随窗口的不同而变化,主要涉及变量的各种查看方式。
Procs它的功能也是随窗口的不同而变化,其主要功能为变量的预算过程。
Quick提供快速统计分析过程.
Options系统参数设定选项.
Window在使用Eviews的过程中将会有多个子窗口。
该菜单提供子窗口的切换和关闭功能。
Help帮助功能。
提供索引方式和目录方式的帮助功能。
3、命令窗口:
菜单栏下是命令窗口.
窗口最左端的竖线是提示符,允许用户在提示符后通过键盘输入EViews(TSP风格)命令.如果熟悉TSP(DOS)版的命令可以直接在此键入,如同DOS版一样地使用EViews。
按F1键(或移动箭头),键入的历史命令将重新显示出来,供用户选用。
4、主显示窗口:
命令窗口之下是Eviews的主显示窗口.
以后操作产生的窗口(称为子窗口)均在此范围之内,不能移出主窗口之外。
5、状态栏:
主窗口之下是状态栏。
左端显示信息,中部显示当前路径,右下端显示当前状态,例如有无工作文件等。
(二)工作文件的创建
Eviews要求数据的分析处理过程要在特定的工作文档(Workfile)中进行,并且该文档需要在具体数据的录入之前建立。
工作文档的作用在于存储分析数据和分析结果。
创建方法:
点击File→New→Workfile(见图2)。
屏幕上出现一个工作文件定义对话框,要求用户指定序列观测数据的频率和样本大小(见图3)。
图2建立工作文档操作
图3工作文档定义对话框
在图3的对话框中,工作频率项(Workfilefrequency)可根据具体情况选择年度(Annual)、季度(Quarterly)、月度(Monthly)等样式,并在下面的空格输入数据的起止时间。
其中:
Annual用四位数表示年份,如1950、2000.Startdate后输入开始年份,Enddate后输入终止年份。
Quarterly输入格式如1960:
l,年份后面跟1、2、3、4四个数字,代表四个季度。
Monthly输入格式如1970:
03,年份后面是月份.
Weekly和Daily选项,格式为“月:
日:
年”,如10:
31:
1980。
Undatedorirregular表示其他数据类型,如无时间限定的数据。
起止项分别输入1和100,表示一个有100个数的序列。
输入完毕后,点击OK,工作文档创建完毕,工作文件窗口同时打开(见图4)。
(四)工作文件窗口简介
图4工作文件窗口
工作文件窗口是各种类型数据的集中显示区域,拥有很多功能。
窗口最上方显示工作文件名称(上图中显示的是未命名).
下面一行是常用工具栏,提供各种运算功能。
工具栏下方的长条空白框显示的是有关当前数据的基本情况,如数据区间(Range)、样本期(Sample)等。
通常,新建立的工作文件窗口内只有两个对象:
系数常量(C)和残差(resid),来保存回归方程的估计系数和残差,初始值分别为0和空值(NA),多次方程估计时,这两个对象的数值也会发生变化。
对于工作文件窗口中的对象,可以双击打开需要查看的对象以查看其数值。
(五)工作文件的存储与调用
保存新建工作文件的方法有两种:
一种是点击主窗口菜单,File/Save或SaveAs;另一种是直接点去工作文件窗口工具栏中的Save按钮。
注意:
给工作文件命名时,不能超过八个字符,且没有空格、逗号、句号.
打开以前保存的工作文档,要点击主窗口菜单,File→Open→Workfile,并选择路径和文件名。
(六)工作文件时间范围的调整
在软件的应用过程中,经常需要追加数据或对变量进行预测,而新增加的数据或预测的结果将会超过原先设定的起止日期,此时需对工作文件的时间范围进行调整.
在工作文件窗口的工具栏中,选择Procs/ChangeWorkfileRange,然后在弹出的对话框中输入新的观测起止时间即可。
注意,如果新输入的起止时间未包含以前的设置,Eviews将会要求用户确认,因为未包括部分的数据会丢失。
二、序列对象的基本操作
Eviews中共有19种功能不同的对象。
对象是构成工作文件的基本元素,也是实现所有分析过程的载体。
对象的名称包括系数向量(CoefficientVector)、序列(Series)、方程(Equation)等。
最常用的为序列和方程对象。
(-)序列的建立和打开
工作文件建立之后,应创建待分析的数据序列。
创建方法:
点击工作文件窗口的工具栏,Object/NewObject,屏幕出现对象定义对话框(见图5)。
图5对象定义对话框
用户可以在对话框左侧列表中选择新建对象的类型,如序列(Series)。
在对话框右上方的空格处,用户可以为新对象命名,缺省为Untitled.当定义了正确的对象类型和输入对象名称之后,点击OK确认。
注意,在给对象进行命名时,不能使用保留字符:
ABSACOSARASINCCONCNORM
COEFCOSDDLOGDNORMELSE
ENDIFEXPLOGLOGITLPT1LPT2MA
NANRNDPDLREISDRNDSARSIN
SMASQRTHEN
同时,在Eviews中不区分对象名称的大小写,如:
P和p被视为同一序列。
打开已有对象的方法很多。
直接双击选定的对象打开;
在工作文件窗口点击View→OpenSelected→OneWindow打开;
在工作文件窗口中点击Show或在主窗口中点击Quick→Show后,输人需要打开的对象的名称打开。
(二)序列对象窗口简介
对象窗口用户显示对象包含的内容,既可以是数据,也可以是有关计算结果。
假设建立了一个名称为X的序列,打开该序列后的序列对象窗口如图6所示.
图6序列对象窗口
序列对象窗口是一个类似Excel电子表格形式的窗口。
窗口的上方是一排工具栏按钮,它们通常根据对象的不同而变化。
这里不展开介绍,有兴趣的同学可以参考介绍Eviews的有关书籍。
(三)序列数据的录入、调用和编辑
在Eviews软件中,用户可以选择多种输入数据的方法。
1.手工输入。
打开一个序列对象窗口(见图6)。
在工具栏上点击Edit+/一进入编辑状态,此时用户可以在相应位置输入或修改序列观测值。
2.调入已有数据文件。
Eviews支持三种格式的数据文件:
文本格式(ASCII)、Lotus和Excell作表.调入已有数据时,用户点击Procs→Import→ReadText—Lotus-Excel,然后找到并打开目标文件。
要导入的excel,需要注意的是excel要保存为97-2003工作簿.
其中,upper-leftdatacell为开始读取的第一个数据的位置(不包含行列名),sheetname为打开的是这个excel文件中的哪个工作表,namesforseriesornumberifnamedinfiles为工作表中序列的名字。
三、统计图形绘制
将某个序列画成图,双击工作文件中该序列的名称,打开序列表格窗口,单击“view—graph”,在graphoptions对话框中的“specific"中选择要绘制的图形类型,单击确定。
常用的有bar(条形图),dotplot(散点图),boxplot(箱线图)等.
四、序列的描述性统计量
单击序列窗口的“view-descriptivestatistics”,其中
“histogramandstatistic”是直方图合同计量,显示的是选定序列的直方图以及一些描述性统计量的值.包括均值、中位数、最大最小值、标准差、偏度、峰度等。
Statstable是把所有的描述统计输出成表格。
要注意的是,如果是单序列描述统计表格,输出只有上面这一种情况,如果我们打开的是一个序列组,在descriptivestats里有两个选项,commonsample和individualsample。
这两个选项是有差别的。
假设序列组的两个变量分别为x和y,x的样本数和y的样本数是相同的,则commonsample和individualsample的输出结果是一样的。
当x和y的样本个数不相同的时候,commonsample输出的是当x和y都有观测值的时候的统计量,所以在commonsample中,x和y的观测值数量是相同的。
而individualsample则分别计算x和y的统计量,所以如果x和y的样本数不相同的时候,在individualsample中的观测值数量是会不同的.
选择View→DescriptiveStatistics→StatsbyClassification,屏幕出现分组描述统计定义对话框。
序列的分组描述统计分析是将样本期分为若干子集后,对各组观测值分别进行描述统计。
对话框左边统计量(Statistics)下面有10个选项,用户选择一个或多个输出统计量的种类。
在分组序列(Series/GroupforClassify)下面输入分组变量的名称,此处分组变量的数目可以不止一个.
 升级会员
升级会员 