Kettle42源代码分析.docx
《Kettle42源代码分析.docx》由会员分享,可在线阅读,更多相关《Kettle42源代码分析.docx(41页珍藏版)》请在冰豆网上搜索。
Kettle42源代码分析
Kettle4.2源代码分析
史磊石
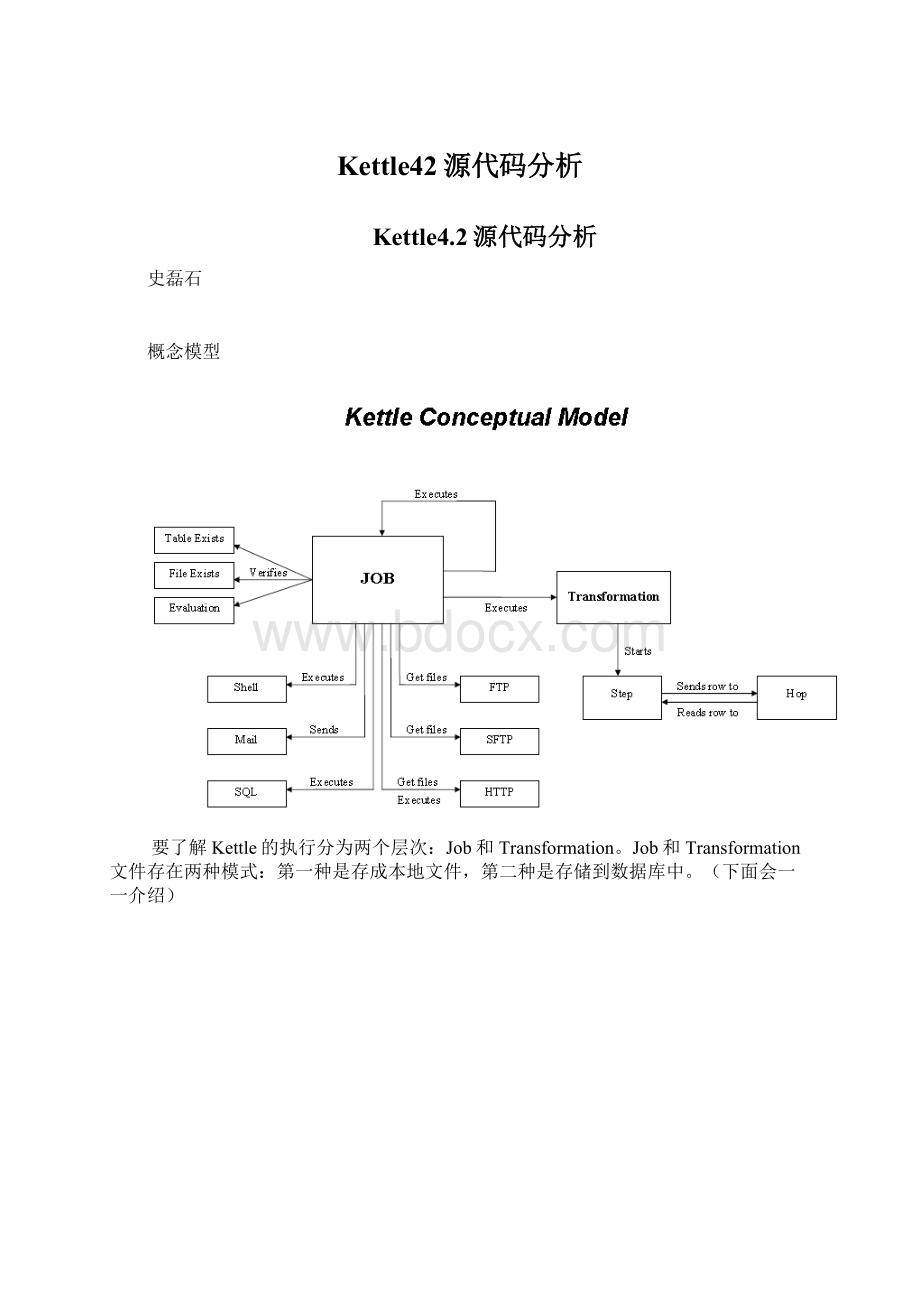
概念模型
要了解Kettle的执行分为两个层次:
Job和Transformation。
Job和Transformation文件存在两种模式:
第一种是存成本地文件,第二种是存储到数据库中。
(下面会一一介绍)
1.源代码结构
1.1.总体结构
Kettle源代码由7个sourcefolder组成,分别是:
src-core、src、src-ui、src-db、test、src-dbdialog、src-plugins。
1.1.1.src-core源代码文件夹
1.1.1.1.patibility包
系统用到的数值类型及对应接口。
1.1.1.2.org.pentaho.di.core.exception包
异常类
1.1.1.3.org.pentaho.di.core.xml包
XML相关接口及封装类。
这些类涉及
1.1.1.4.org.pentaho.di.core.config包
只有两个类,OgnlExpression用来封装ognl表达式的。
PropertySetter辅助类。
1.1.1.5.org.pentaho.di.core.encryption包(kettle的密码的加密与解密)
1.1.1.6.org.pentaho.di.core.exception包kettle中的各种关于kettle异常管理,如文件、数据库、自定义的kettleException等。
1.1.1.7.org.pentaho.di.core.logging包
Log设置。
1.1.1.8.org.pentaho.di.core.plugins包
组件加载。
1.1.1.9.org.pentaho.di.core.row包
行的数据、元信息、操作。
1.1.1.10.org.pentaho.di.core.gui包
界面接口类和一些基础图形类。
1.1.1.11.其他
org.pentaho.di.Const类维护系统常量及配置文件地址。
Org.
1.1.2.src源代码文件夹
包含调度逻辑和具体的执行代码。
最重要的两个包为org.pentaho.di.job和org.pentaho.di.trans。
1.1.2.1.org.pentaho.di.job包
Job的每个执行单元称为entry。
org.pentaho.di.job.entry包中存放了每个entry必须继承的基类以及必须实现的接口。
org.pentaho.di.job.entries包中存放了不同entry的具体实现。
1.1.2.2.org.pentaho.di.trans包
Transfromation中的每个执行步骤称为step。
org.pentaho.di.job.entry包中存放了每个entry必须继承的基类以及必须实现的接口。
org.pentaho.di.job.entries包中存放了不同entry的具体实现。
1.1.2.3.org.pentaho.di.kitchen包
Job的命令行执行器类。
1.1.2.4.org.pentaho.di.pan包
Transformation的命令行执行器类。
1.1.3.src-ui源代码文件夹
最主要的就是其下的org.pentaho.di.ui包。
结构如上图所示,其中最重要的3个子包为:
org.pentaho.di.ui.job、org.pentaho.di.ui.trans和org.pentaho.di.ui.spoon。
1.1.3.1.org.pentaho.di.ui.job包
每个entry的参数设置面板类、进程对话类及需要继承的基类。
1.1.3.2.org.pentaho.di.ui.trans包
每个step的参数设置面板类、进程对话类及需要继承的基类。
1.1.3.3.org.pentaho.di.ui.spoon包
整个软件的入口对应org.pentaho.di.ui.spoon包中的Spoon类。
选中Job标签后,红框内的编辑区对象对应org.pentaho.di.ui.spoon.job包中的JobGraph类。
选中转换标签后,红框内的编辑区对象对应org.pentaho.di.ui.spoon.trans包中的TransGraph类。
1.1.3.4.其他
org.pentaho.di.core.KettleEnvironment类负责初始化Kettle运行环境,主要包括调用org.pentaho.di.core.plugins.PluginRegistry类的init()方法加载组件。
1.1.4.src-db源代码文件夹
org.pentaho.di.core.database下包含各数据库对应的类以及对应的元数据类,还包括不同类型数据库必须继承的基类和必须实现的接口。
1.1.5.test源代码文件夹
测试代码。
(未阅读)
2.数据流图
2.1.顶层数据流图
2.2.第一层数据流图
2.3.第二层数据流图
2.3.1.作业执行
2.3.2.转换执行
3.Kettle启动
3.1.顶层
对应org.pentaho.di.ui.spoon包中Spoon类:
publicstaticvoidmain(String[]a)throwsKettleException{
try{
...
//3.2.初始化Kettle运行环境
KettleEnvironment.init();
...
//3.3.初始化Spoon界面,读取配置文件(.xul)
staticSpoon=newSpoon(display);
staticSpoon.init(null);
...
//开启Spoon,enable各个组件
staticSpoon.start(splash,commandLineOptions);
}catch(...){
...
}
}
3.2.初始化Kettle运行环境
对应org.pentaho.di.core包中KettleEnvironment类:
publicstaticvoidinit(booleansimpleJndi)throwsKettleException{
//若未曾初始化
if(initialized==null){
//若不存在则创建一个home文件夹
createKettleHome();
//加载home中kettle.properties文件的内容
EnvUtil.environmentInit();
//Log初始设置:
容量大小、超时时长
CentralLogStore.init();
…
//加载Kettle需要用到的变量值,从Kettle-variables.xml文件
KettleVariablesList.init();
initialized=true;
}
}
3.2.1.Home文件夹
根据用户系统设置建立“.kettle”文件夹。
该文件夹内存放用户对于系统的喜好配置以及历史信息。
这些信息会在启动时被读取。
3.3.初始化Spoon界面
读取ui\*.xul文件进行部署。
对应Spoon类的init()方法:
publicvoidinit(TransMetati){
//对界面布局进行设置
shell.setLayout(layout);
//加入ktr、kjb文件读写监听器
addFileListener(newTransFileListener());
addFileListener(newJobFileListener());
…
//加载初始化一些变量
…
try{
//SwtXulLoader类没有提供src
xulLoader=newSwtXulLoader();
…
}catch(…){
…
}
//加载部分固定组件及对应监听器
…
}
源代码无法查看的截图:
这里分析的源代码是最新的4.0版本。
3.2版本的这部分代码是可以查看的,但两者结构不同:
上图为4.0版本
上图为3.2版本。
4.Job、Transformation界面调用
通过用户界面操作(点击运行按钮)触发监听器,调用Spoon的runFile()方法。
4.1.Spoon类runFile()
publicvoidrunFile(){
executeFile(true,false,false,false,false,null,false);
}
4.2.Spoon类executeFile()
在这一层决定执行Job还是Transformation。
publicvoidexecuteFile(booleanlocal,booleanremote,booleancluster,booleanpreview,booleandebug,DatereplayDate,booleansafe){
//获取当前活跃的Transformation元信息
TransMetatransMeta=getActiveTransformation();
if(transMeta!
=null)
executeTransformation(transMeta,local,remote,cluster,preview,debug,replayDate,safe);
//获取当前活跃的Job元信息
JobMetajobMeta=getActiveJob();
if(jobMeta!
=null)
executeJob(jobMeta,local,remote,replayDate,safe);
}
4.3.Spoon类getActiveTransformation()、getActiveJob()
publicTransMetagetActiveTransformation(){
EngineMetaInterfacemeta=getActiveMeta();
if(metainstanceofTransMeta){
return(TransMeta)meta;
}
returnnull;
}
getActiveJob()类的实现同getActiveTransformation()。
如上图,JobMeta和TransMeta都实现了EngineMetaInterface。
上图可见,EngineMetaInterface包含Job、Transformation的整体操作。
4.4.Spoon类getActiveMeta()
publicEngineMetaInterfacegetActiveMeta(){
if(tabfolder==null)
returnnull;
TabItemtabItem=tabfolder.getSelected();
if(tabItem==null)
returnnull;
//通过当前活跃的Tab标签确定返回类型。
TabMapEntrymapEntry=delegates.tabs.getTab(tabfolder.getSelected());
EngineMetaInterfacemeta=null;
if(mapEntry!
=null){
if(mapEntry.getObject()instanceofTransGraph)
meta=(mapEntry.getObject()).getMeta();
if(mapEntry.getObject()instanceofJobGraph)
meta=(mapEntry.getObject()).getMeta();
}
returnmeta;
}
下图红色方框内为活跃的Tab。
4.5.选择执行时序图
下图总结了4.1-4.4节内容,即系统如何判定执行Job还是Transformation。
4.6.Job调用后续步骤
最终转交给JobGraph负责执行。
实现方法同4.7。
4.7.Transformation调用后续步骤
最终转交给TransGraph负责执行。
4.7.1.Spoon类executeTransformation()
publicvoidexecuteTransformation(…){
newThread(){
…
//利用trans执行代理执行trans
delegates.trans.executeTransformation(transMeta,local,remote,cluster,preview,debug,
replayDate,safe);
…
}.start();
}
4.7.2.SpoonTransformationDelegate类executeTransformation()
publicvoidexecuteTransformation(…){
…
//获取当前活跃的trans
TransGraphactiveTransGraph=spoon.getActiveTransGraph();
…
//将配置设置入executionConfiguration后调用TransGraph实例执行
activeTransGraph.start(executionConfiguration);
…
}
5.Job执行
5.1.相关类和接口
5.1.1.JobGraph
维护整个Job编辑区的信息和相应操作。
主要成员变量:
privateJobMetajobMeta;由Job编辑面板动态维护
privateRepositoryrep;
privateJobparentJob;
privateJobTrackerjobTracker;用于跟踪日志记录
privateDatestartDate,endDate,currentDate,logDate,depDate;
privatebooleanactive,stopped;状态位
privateListsourceRows;返回结果的数据内容
privateResultresult;每次执行完一个jobentry返回结果
5.1.2.JobMeta
维护整个Job的元数据。
主要成员变量:
protectedStringname;
protectedStringfilename;
publicListjobentries;保存jobentry列表
publicListjobhops;保存jobentries之间的链接关系。
publicListdatabases;
5.1.3.JobEntryInterface
每个具体org.pentaho.di.job.entries包下的entry类需要实现的接口。
包含execute()方法。
5.1.4.Result
每一个jobEntryInterface的实现类在完成相应功能时,返回结果的类型。
主要成员变量:
privatebooleanresult;执行是否出现异常
privateintexitStatus;执行结果状态
privateListrows;一个jobEntry完成处理后的数据(若存在)
privateMapresultFiles;
5.1.5.JobEntryCopy
维护每一个不同entry或者相同entry的不同副本的信息
主要成员:
privateJobEntryInterfaceentry;具体entry,执行入口
privateintnr;副本数,一个编辑区里可以出现多个相同组件
privatebooleanselected;
privatePointlocation;图标位置
privatebooleandraw;
privatelongid;
5.2.Job执行过程时序图
下图描述了上面各类之间的总体调用关系。
5.3.代码执行说明
5.3.1.JobGraph类start()
该类主要功能是实例化job、开启job的线程。
主要代码如下:
job=newJob(log,jobMeta.getName(),jobMeta.getFilename(),null);
……
job.start();
5.3.2.JobGraph类start()
设置状态位,调用execute方法1,部分代码代码如下:
publicvoidrun(){
……
stopped=false;
finished=false;
initialized=true;
……
result=execute(false);
……
}
5.3.3.Job类execute()方法1
主要工作是从JobMeta的JobHopMeta找到job入口jobentry信息,根据开始条件调用真正执行jobentry的execute方法2,代码如下所示:
startpoint=jobMeta.findJobEntry(JobMeta.STRING_SPECIAL_START,0,false);
//找到Job开始组件
JobEntrySpecialjes=(JobEntrySpecial)startpoint.getEntry();
//JobEntrySpecial是启动job的job项目
Resultres=null;
while((jes.isRepeat()||isFirst)&&!
isStopped()){
//符合开始条件时,调用execute方法2
isFirst=false;
res=execute(0,null,startpoint,null,
Messages.getString("Job.Reason.Started"));
}
5.3.4.Job类execute()方法2
主要功能是根据参数startpoint,提取对应的jobentry,执行对应的jobentry操作,再根据JobMeta的hop信息依次得到下一个jobentry,嵌套调用execute方法2调用,代码如下:
JobEntryInterfacejei=startpoint.getEntry();
JobEntryInterfacecloneJei=(JobEntryInterface)jei.clone();
//以下是执行JobEntryInterface的实现类的execute()方法。
finalResultresult=cloneJei.execute(prevResult,nr,rep,this);
//根据jobMeta的Hop信息找到下一跳的个数
intnrNext=jobMeta.findNrNextJobEntries(startpoint);
for(inti=0;iisStopped();i++){
//对于每一个下一跳分别找到每一个入口。
JobEntryCopynextEntry=jobMeta.findNextJobEntry(startpoint,i);
//得到startpoint,nextEntry的信息,找到hop元数据信息,判断是否应该执行
JobHopMetahi=jobMeta.findJobHop(startpoint,nextEntry);
……
//如果应该执行,则把前一个JobEntry执行结果result和应该执行的jobentry作为参数嵌套调用execute方法2。
res=execute(nr+1,result,nextEntry,startpoint,nextComment);
}
5.4.执行示例说明
调试一个Job,其拓扑如下:
黑色Hop代表无条件执行下一个JobEntry,红色代表结果为false执行下一jobEntry,绿色代表结果为true执行下一跳。
7
6
5
4
3
2
1
General-ChangelogProcessing和General-ChangelogProcessin2是两个trans。
job的执行顺序为jobEntry的深度遍历,如标号所示。
5.5.JobEntry执行
5.5.1.JobEntry类
具体每个组件的执行体对应org.pentaho.di.job.entries包内每个entry的具体实现。
execute()方法2中调用jobEntry的execute()完成jobEntry的具体功能。
5.5.2.不同jobEntry的实现
finalResultresult=cloneJei.execute(prevResult,nr,rep,this);
不同的Job项目(JobEntry)实现差别很大。
5.5.2.1.JobEntrySpecial
功能是开启一个job,只是简单地对传递来的preResult设置它的的result属性值为true,(Job项目据此判断前一结果执行完毕)。
返回该对象即可。
5.5.2.2.JobEntryTableExit
功能是判断一个table是否存在数据库中。
JobEntryTableExitJob项目有属性tablename和DatabaseMeta(对数据库的元数据信息描述)根据DatabaseMeta得到一个Dabase对象db,建立连接db.connect();调用db.checkTableExists(tablename)根据此返回值设置preResult的result属性为否为true。
返回preResult对象。
5.5.2.3.JobEntryTrans
JobEntryJob和JobEntryTrans是嵌套job或trans的Job项目(JobE
 升级会员
升级会员 