蚂蚁环境拓扑图部署任务同步.docx
《蚂蚁环境拓扑图部署任务同步.docx》由会员分享,可在线阅读,更多相关《蚂蚁环境拓扑图部署任务同步.docx(9页珍藏版)》请在冰豆网上搜索。
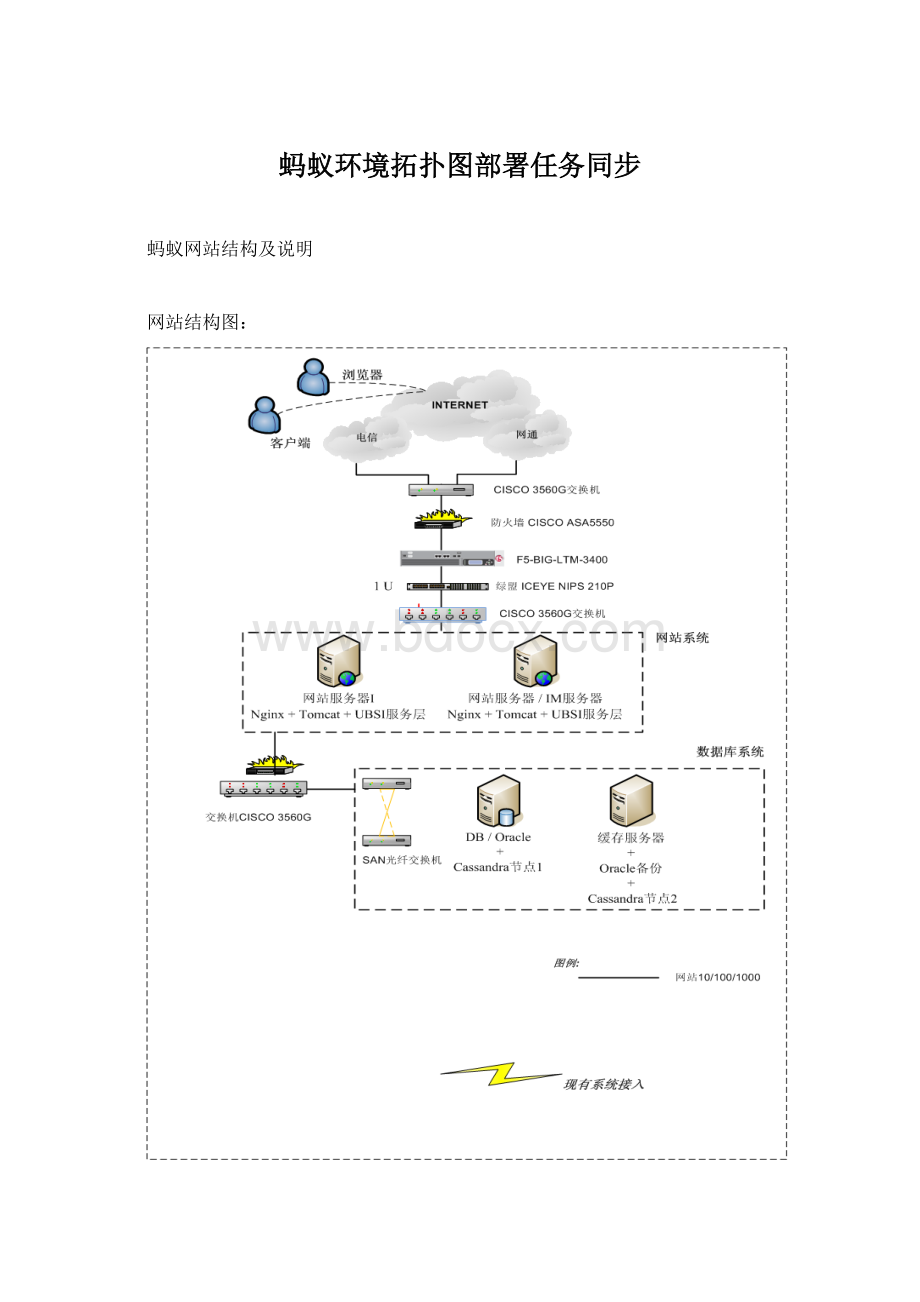
蚂蚁环境拓扑图部署任务同步
蚂蚁网站结构及说明
网站结构图:
硬件配置
功能
硬件配置
DB主1台
2U机架式/处理器:
2×英特尔®至强®内存:
8G
硬盘:
146G×2(raid0+1)+300G×2(raid0+1)
DB备1台
2U机架式/处理器:
2×英特尔®至强®内存:
4G
硬盘:
146G×2(raid0+1)+300G×2(raid0+1)
Webapp主1台
2U机架式/处理器:
2×英特尔®至强®内存:
4G
硬盘:
146G×2(raid0+1)
Webapp备1台
2U机架式/处理器:
2×英特尔®至强®内存:
4G
硬盘146G×2(raid0+1)
软件版本
操作系统:
--CentOSenterpriseLinux5.4
应用软件:
--Tomcat6
--ApacheorNginx
--Oracle10g
--UBSI
--rsync
--JDK1.6
--Cassandra0.6
--Memcached
开放的端口
--WebPort:
80
--IMPort:
443
文件备份策略
注:
文件指用户上传的头像、图片、文件等。
流程示意图
备份方案:
Ø网站系统使用rsync服务进行实时同步
✓rsync服务属于linux系统级服务
✓rsync服务客户端会先比对资源,并同步自己没有的和较新的文件
✓rsync服务占用资源小
Ø设计将网站主DB服务器用于文件存放地点;
✓DB服务器相比网站应用服务器有更加强大的保护,不易受到攻击
✓DB服务器的空间比较充裕
✓DB服务器与主备网站服务器物理联通,无论做数据存储点或作为数据中转点都比较理想
Ø网站主web/app服务器每日夜间0:
00点向网站主DB服务器同步文件
Ø网站主DB服务器每日凌晨向网站备用web/app服务器同步文件
数据备份策略
方案一:
数据库导入导出采用增量方式
增量导出是一种常用的数据备份方法,它只能对整个数据库来实施,并且必须作为SYSTEM来导出。
在进行此种导出时,系统不要求回答任何问题。
导出文件名缺省为export.dmp,如果不希望自己的输出文件定名为export.dmp,必须在命令行中指出要用的文件名。
增量导出包括三个类型:
(1)“完全”增量导出(Complete)
即备份整个数据库,比如:
$exp system/manager inctype=complete file=990702.dmp
(2) “增量型”增量导出
备份上一次备份后改变的数据。
比如:
$exp system/manager inctype=incremental file=990702.dmp
(3) “累计型”增量导出(Cumulative)
累计型导出方式只是导出自上次“完全” 导出之后数据库中变化了的信息。
比如:
$exp system/manager inctype=cumulative file=990702.dmp
数据库管理员可以排定一个备份日程表,用数据导出的三个不同方式合理高效地完成。
比如数据库的备份任务可作如下安排:
星期一:
完全导出(A)
星期二:
增量导出(B)
星期三:
增量导出(C)
星期四:
增量导出(D)
星期五:
累计导出(E)
星期六:
增量导出(F)
星期日:
增量导出(G)
如果在星期日,数据库遭到意外破坏,数据库管理员可按以下步骤来恢复数据库:
第一步:
用命令CREATE DATABASE重新生成数据库结构;
第二步:
创建一个足够大的附加回段。
第三步:
完全增量导入A:
$imp system./manager inctype= RECTORE FULL=Y FILE=A
第四步:
累计增量导入E:
$imp system/manager inctype= RECTORE FULL=Y FILE =E
第五步:
最近增量导入G:
$imp system/manager inctype=RESTORE FULL=Y FILE=G
方案二:
OracleStream
OracleStream利用高级队列技术,通过解析归档日志,将归档日志解析成DDL及DML语句,从而实现数据库之间的同步。
这种技术可以将整个数据库、数据库中的对象复制到另一数据库中,通过使用Stream的技术,对归档日志的挖掘,可以在对主系统没有任何压力的情况下,实现对数据库对象级甚至整个数据库的同步。
1.1设定初始化参数
使用pfile的修改init.ora文件,使用spfile的通过altersystem命令修改spile文件。
主、从数据库分别执行如下的语句:
Sqlplus‘/assysdba’
altersystemsetaq_tm_processes=2scope=both;
altersystemsetglobal_names=truescope=both;
altersystemsetjob_queue_processes=10scope=both;
altersystemsetparallel_max_servers=20scope=both;
altersystemsetundo_retention=3600scope=both;
altersystemsetnls_date_format='YYYY-MM-DDHH24:
MI:
SS'scope=spfile;
altersystemsetstreams_pool_size=25Mscope=spfile;
altersystemsetutl_file_dir='*'scope=spfile;
altersystemsetopen_links=4scope=spfile;
执行完毕后重启数据库。
1.2将数据库置为归档模式
设置log_archive_dest_1到相应的位置;设定log_archive_start为TRUE,即启用自动归档功能;设定log_archive_format指定归档日志的命令格式。
数据库置为归档模式后,可以按如下方式检验一下:
SQL>archiveloglist
1.3创建stream管理用户
1.3.1创建主环境stream管理用户
以sysdba身份登录创建主环境的Stream专用表空间,将logminer的数据字典从system表空间转移到新建的表空间,防止撑满system表空间,创建Stream管理用户,授权Stream管理用户
1.3.2创建从环境stream管理用户
#以sysdba身份登录,创建Stream专用表空间,这一步也可以参见3.3.1。
同样,将logminer的数据字典从system表空间转移到新建的表空间,防止撑满system表空间,创建Stream管理用户,授权Stream管理用户。
1.4配置网络连接
1.4.1配置主环境tnsnames.ora
主数据库(tnsnames.ora)中添加从数据库的配置。
H10G=
(DESCRIPTION=
(ADDRESS_LIST=
(ADDRESS=(PROTOCOL=TCP)(HOST=192.168.10.43)(PORT=1521))
)
(CONNECT_DATA=
(SID=h10g)
(SERVER=DEDICATED)
)
)
1.4.2配置从环境tnsnames.ora
从数据库(tnsnames.ora)中添加主数据库的配置。
PROD=
(DESCRIPTION=
(ADDRESS_LIST=
(ADDRESS=(PROTOCOL=TCP)(HOST=192.168.10.35)(PORT=1521))
)
(CONNECT_DATA=
(SID=prod)
(SERVER=DEDICATED)
)
)
1.5启用追加日志
可以基于Database级别或Table级别,启用追加日志(SupplementalLog)。
在建立根据Schema粒度进行复制的OracleStream环境中,如果确认Schema下所有Table都有合理的主键(PrimaryKey),则不再需要启用追加日志。
#启用Database追加日志
#启用Table追加日志
1.6创建DBlink
根据Oracle10gR2Stream官方文档,针对主数据库建立的数据库链的名字必须和从数据库的global_name相同。
如果需要修改global_name,执行“alterdatabaserenameglobal_nametoxxx”。
1.6.1创建主数据库数据库链
#以strmadmin身份,登录主数据库。
建立数据库链
createdatabaselinkh10gconnecttostrmadminidentifiedbystrmadminusing'h10g';
1.6.2创建从数据库数据库链
#以strmadmin身份,登录从数据库。
建立数据库链
createdatabaselinkprodconnecttostrmadminidentifiedbystrmadminusing'prod';
1.7创建流队列
1.7.1创建Master流队列
#以strmadmin身份,登录主数据库。
connectstrmadmin/strmadmin
begin
dbms_streams_adm.set_up_queue(
queue_table=>'prod_queue_table',
queue_name=>'prod_queue');
end;
/
1.7.2创建Backup流队列
#以strmadmin身份,登录从数据库。
connectstrmadmin/strmadmin
begin
dbms_streams_adm.set_up_queue(
queue_table=>'h10g_queue_table',
queue_name=>'h10g_queue');
end;
/
1.8创建捕获进程
#以strmadmin身份,登录主数据库。
提醒一下,本文档以hr用户做示例。
connectstrmadmin/strmadmin
begin
dbms_streams_adm.add_schema_rules(
schema_name=>'hr',
streams_type=>'capture',
streams_name=>'capture_prod',
queue_name=>'strmadmin.prod_queue',
include_dml=>true,
include_ddl=>true,
include_tagged_lcr=>false,
source_database=>null,
inclusion_rule=>true);
end;
/
1.9实例化复制数据库
在主数据库环境中,执行如下Shell语句。
如果从库的hr用户不存在,建立一个hr的空用户。
expuserid=hr/hr@prodfile='/tmp/hr.dmp'object_consistent=yrows=y
impuserid=system/manager@h10gfile='/tmp/hr.dmp'ignore=ycommit=ylog='/tmp/hr.log'streams_instantiation=yfromuser=hrtouser=hr
1.10创建传播进程
#以strmadmin身份,登录主数据库。
connectstrmadmin/strmadmin
begin
dbms_streams_adm.add_schema_propagation_rules(
schema_name=>'hr',
streams_name=>'prod_to_h10g',
source_queue_name=>'strmadmin.prod_queue',
destination_queue_name=>'strmadmin.h10g_queue@h10g',
include_dml=>true,
include_ddl=>true,
include_tagged_lcr=>false,
source_database=>'prod',
inclusion_rule=>true);
end;
/
#修改propagation休眠时间为0,表示实时传播LCR。
begin
dbms_aqadm.alter_propagation_schedule(
queue_name=>'prod_queue',
destination=>'h10g',
latency=>0);
end;
/
1.11创建应用进程
#以strmadmin身份,登录从数据库。
connectstrmadmin/strmadmin
begin
dbms_streams_adm.add_schema_rules(
schema_name=>'hr',
streams_type=>'apply',
streams_name=>'apply_h10g',
queue_name=>'strmadmin.h10g_queue',
include_dml=>true,
include_ddl=>true,
include_tagged_lcr=>false,
source_database=>'prod',
inclusion_rule=>true);
end;
/
1.12启动STREAM
#以strmadmin身份,登录从数据库。
启动Apply进程
begin
dbms_apply_adm.start_apply(
apply_name=>'apply_h10g');
end;
/
#以strmadmin身份,登录主数据库。
启动Capture进程
begin
dbms_capture_adm.start_capture(
capture_name=>'capture_prod');
end;
/
1.13停止STREAM
#以strmadmin身份,登录主数据库。
停止Capture进程
begin
dbms_capture_adm.stop_capture(
capture_name=>'capture_prod');
end;
/
#以strmadmin身份,登录从数据库。
停止Apply进程
begin
dbms_apply_adm.stop_apply(
apply_name=>'apply_h10g');
end;
/
1.14清除所有配置信息
要清楚Stream配置信息,需要先执行3.13,停止Stream进程。
#以strmadmin身份,登录主数据库。
connectstrmadmin/strmadmin
execDBMS_STREAMS_ADM.remove_streams_configuration();
#以strmadmin身份,登录从数据库。
connectstrmadmin/strmadmin
execDBMS_STREAMS_ADM.remove_streams_configuration();
 升级会员
升级会员 