上机练习5 Logistic回归与因子分析.docx
《上机练习5 Logistic回归与因子分析.docx》由会员分享,可在线阅读,更多相关《上机练习5 Logistic回归与因子分析.docx(9页珍藏版)》请在冰豆网上搜索。
上机练习5Logistic回归与因子分析
上机练习5Logistic回归分析与因子分析
本上机练习的主要目的:
熟悉如何利用SPSS软件来进行Logistic回归分析与因子分析。
本练习所使用数据文件为“T3_2.sav”和“Apart2.sav”。
1.Logistic回归分析
Q:
如何利用Logistic回归模型来考察大学生的不同特征对他们是否在外租房具有显著的影响?
(数据文件为“Apart2.sav”)
该数据文件来自于2000年对北京市高校大学生在外租房的调查,具体请查看数据字典文件“Apart2_dct.doc”。
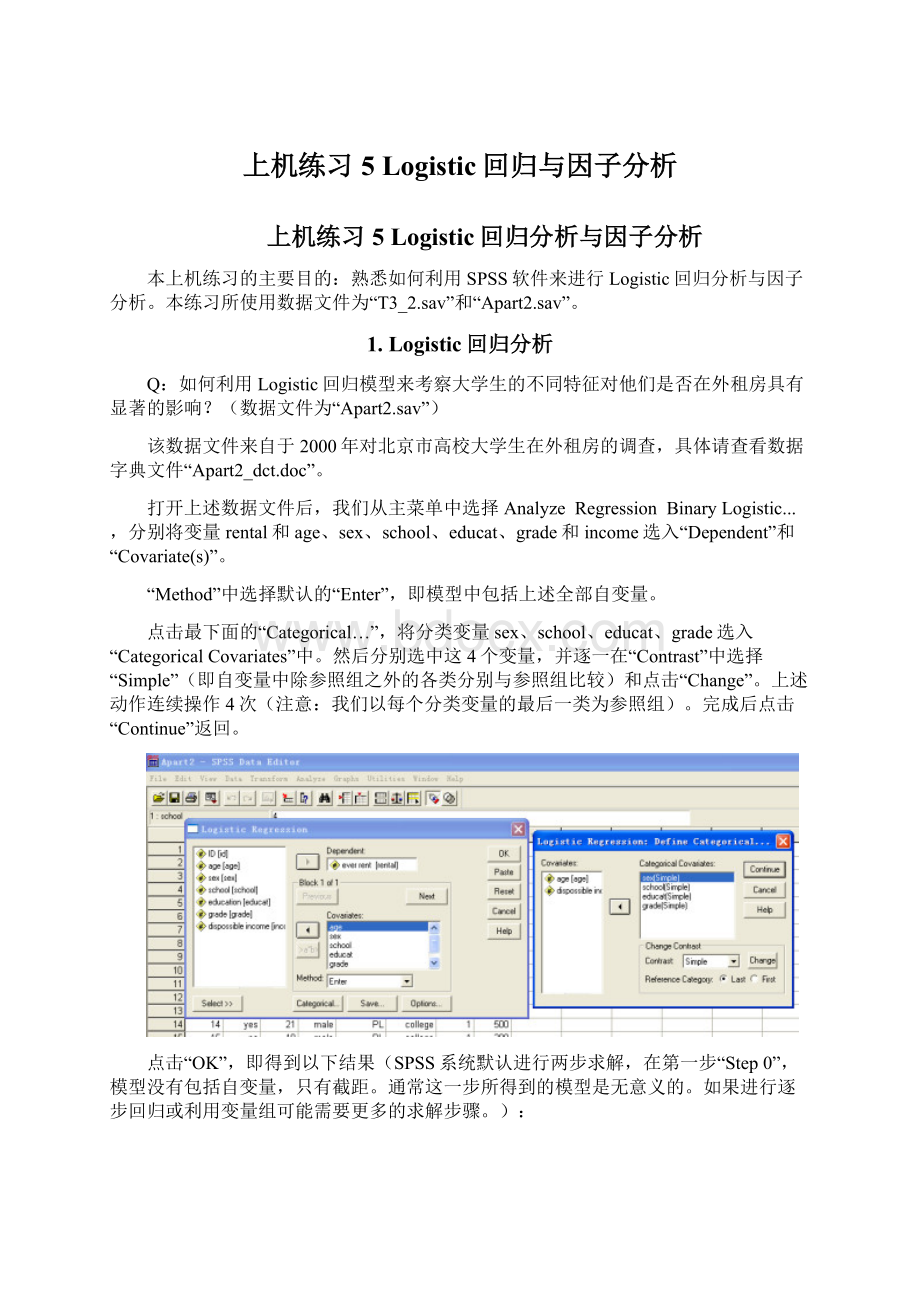
打开上述数据文件后,我们从主菜单中选择AnalyzeRegressionBinaryLogistic...,分别将变量rental和age、sex、school、educat、grade和income选入“Dependent”和“Covariate(s)”。
“Method”中选择默认的“Enter”,即模型中包括上述全部自变量。
点击最下面的“Categorical…”,将分类变量sex、school、educat、grade选入“CategoricalCovariates”中。
然后分别选中这4个变量,并逐一在“Contrast”中选择“Simple”(即自变量中除参照组之外的各类分别与参照组比较)和点击“Change”。
上述动作连续操作4次(注意:
我们以每个分类变量的最后一类为参照组)。
完成后点击“Continue”返回。
点击“OK”,即得到以下结果(SPSS系统默认进行两步求解,在第一步“Step0”,模型没有包括自变量,只有截距。
通常这一步所得到的模型是无意义的。
如果进行逐步回归或利用变量组可能需要更多的求解步骤。
):
上述-2Loglikelihood、Cox&SnellRSquare和NagelkerkeRSquare的结果都没有太大的意义,我们只需了解即可,不要轻易利用这些统计量像线性回归模型中的R2一样来解释模型的拟合程度。
Step1中分类表的预测正确率为76.9%,略高于Step0中分类表的75.4%,表明模型的拟合程度还可以。
上述结果表明,大学生的年龄、性别和其所在学校对他们是否在外租房具有显著的影响,而大学生的学历层次、年级和可支配收入对他们是否在外租房的影响并不显著。
不过,需要提醒大家的是,我们只是在SPSS的“Categorical…”中将那些定类自变量加以定义,而并没有事先用一些相应的虚拟变量来表示。
更好的方式或者说更符合学术习惯的做法是:
先将那些定类变量用某些虚拟变量来表示,然后再进行Logistic回归分析。
我们将上述定类自变量分别用相应的虚拟变量来表示(这可以用“Transform”“Recode”来实现)。
于是,我们会得到以下结果,大家可以与上表加以比较:
不过,到目前为止,我们只是知道大学生的不同特征对其是否外出租房影响的显著性,我们并不知道对其外出租房概率的影响程度,比如,年龄增加1岁会导致外出租房的概率增加多少。
这个问题涉及到如何获得Logistic回归模型的边际影响:
✓如果自变量为连续变量,如年龄Age,我们可利用大学生外出租房概率对其的偏导数来获得:
其中:
其它自变量如果为定量变量,则取平均值代入;如果为虚拟(定类)变量,则取该变量为1的比例代入。
上述均值我们可以通过描述性统计得到:
于是,我们可以计算得到大学生的年龄对其外出租房概率的边际影响为0.0381,即在其他方面特征相同的情形下,大学生的年龄每增加1岁会导致外出租房的概率增加3.81%。
(大家可以将相应的数据复制到excel中,然后利用sumproduct函数就可以得到)
✓如果自变量为虚拟变量,比如性别Male,我们可直接利用该变量从0变化到1所造成的概率变化来表示:
其中:
其它自变量如果为定量变量,则取平均值代入;如果为虚拟(定类)变量,则取该变量为1的比例代入。
于是,我们可以得到大学生的性别对其外出租房概率的边际影响为0.1058,即在其他方面特征相同的情形下,男生比女生外出租房的概率大10.58。
大家可以试着计算一下,看是否与我计算的结果相同?
2.因子分析
生育率的影响因素分析。
生育率受社会、经济、文化、计划生育政策等很多因素影响,但这些因素对生育率的影响并不是完全独立的,而是交织在一起的。
如果直接利用选定的变量对生育率进行多元回归分析,可能会存在多重共线性问题,造成部分信息的丢失。
因此,我们需要先对自变量进行因子分析,找出基本的数据结构,然后再用新生成的因子对生育率进行多元回归分析。
我们所选择的变量包括:
多孩率(x1)、节育率(x2)、初中以上文化程度的人口比例(x3)、人均国民收入(x4)和城镇人口比例(x5)。
所使用数据文件为“T3_2.sav”,所对应的数据字典为“T3_2_dct.doc”。
打开数据集“T3_2.sav”后,我们从主菜单中选择AnalyzeDataReductionFactor...,将上述5个变量全部选入“Variables”。
点击下面的“Descriptives”,在弹出的对话框中选择“Initialsolution(最初解)”、“Coefficients(观测变量的相关系数矩阵)”、“Significancelevels(每个相关系数的显著性水平)”、“Reproduced(由因子模型估计出的相关系数及残差)”和“KMOandBartlett’stestofsphericity(KMO测度和Bartlett球体检验)”。
点击“Continue”返回。
点击“Extraction”,在弹出的对话框中选择“Unrotatedfactorsolution(未经旋转的因子解)”和“Screeplot(碎石图)”,其它选择默认。
注意:
默认的提取因子方法为Principalcomponents(主成分分析)。
点击“Continue”返回。
点击“Rotation”,在弹出的Method对话框中选择“Varimax(方差最大法)”,在Display对话框中选择“Rotatedsolution(旋转后的因子解)”和“Loadingplot(s)(因子负载图)”,其它选择默认。
点击“Continue”返回。
点击“Scores”,在“Displayfactorscorecoefficientmatrix(显示因子分数的系数矩阵)”前打上勾。
点击“Continue”返回。
点击“Options”,在“Sortedbysize(因子负载按绝对值的大小排列)”前打上勾。
点击“Continue”返回,点击“OK”。
我们得到以下结果:
上述结果表明,多孩率和节育率之间存在着较强的相关关系,而其它三个变量之间存在着较强的相关关系,可以对该数据进行因子分析。
上述结果表明,应该选取两个因子。
以下是我们所得到的初始因子负载矩阵、旋转后的因子负载矩阵和因子负载图:
很显然,我们得到了两个因子,分别代表社会经济发展水平和计划生育因子。
利用这两个因子,我们可以进一步考察对生育率的影响。
课堂练习。
1.对影响受访者去洋快餐店消费的重要因素进行因子分析(可考虑将因子个数限定为4个),并利用所得到的因子分以及其它可能的变量作为自变量对“受访者在最近三个月之内的洋快餐消费次数”进行多元回归分析。
2.以“最近三个月内是否经常去洋快餐店消费”为因变量建立适当的Logistic回归模型:
✓需要先对消费次数进行适当的归并,合并成高(5次及以上)与低频率(4次及以下)两种类型,作为因变量。
✓
 升级会员
升级会员 