SPSS中相关术语解释.pdf
《SPSS中相关术语解释.pdf》由会员分享,可在线阅读,更多相关《SPSS中相关术语解释.pdf(8页珍藏版)》请在冰豆网上搜索。
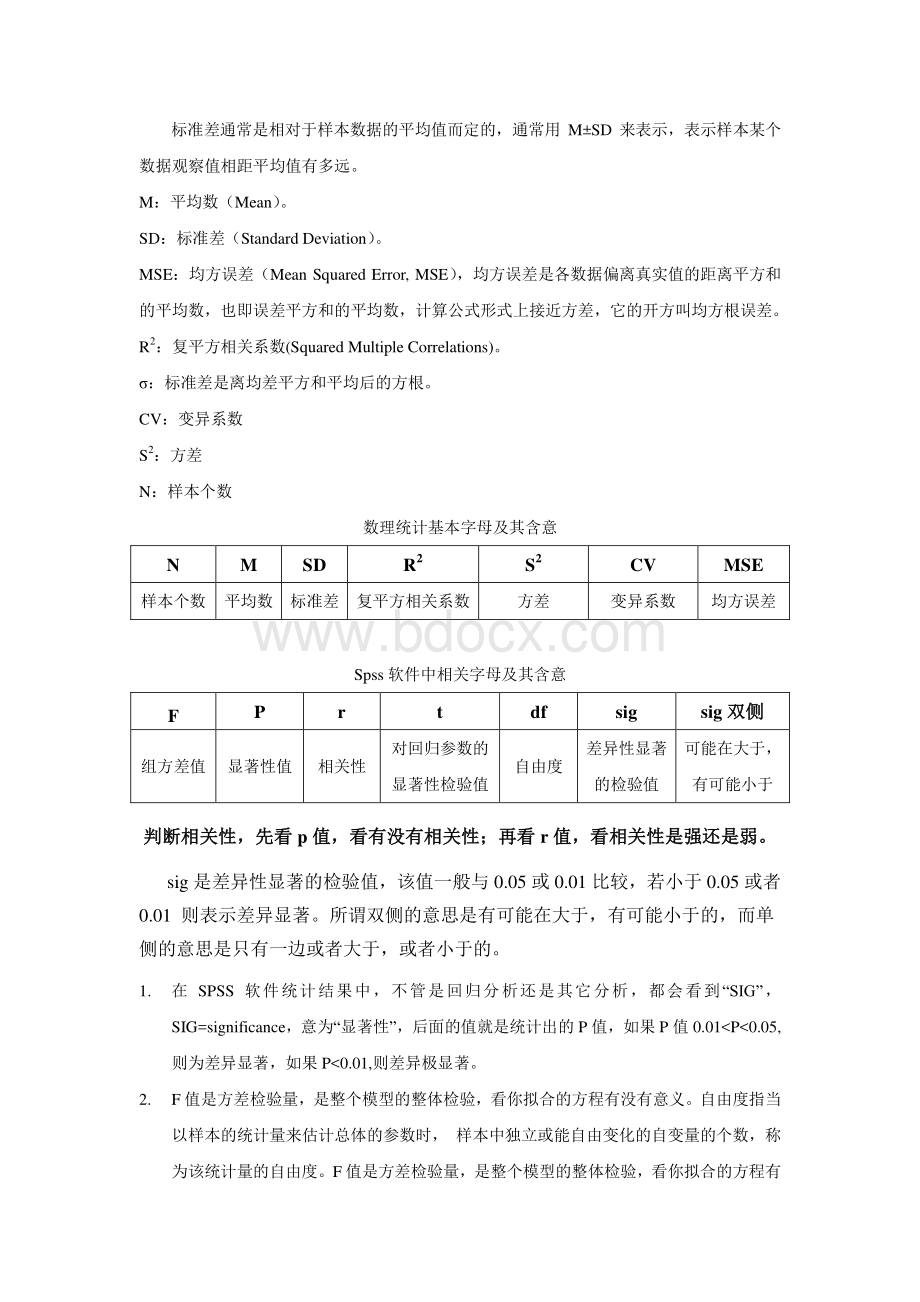
标准差通常是相对于样本数据的平均值而定的,通常用MSD来表示,表示样本某个数据观察值相距平均值有多远。
M:
平均数(Mean)。
SD:
标准差(StandardDeviation)。
MSE:
均方误差(MeanSquaredError,MSE),均方误差是各数据偏离真实值的距离平方和的平均数,也即误差平方和的平均数,计算公式形式上接近方差,它的开方叫均方根误差。
R2:
复平方相关系数(SquaredMultipleCorrelations)。
:
标准差是离均差平方和平均后的方根。
CV:
变异系数S2:
方差N:
样本个数数理统计基本字母及其含意NMSDR2S2CVMSE样本个数平均数标准差复平方相关系数方差变异系数均方误差Spss软件中相关字母及其含意FPrtdfsigsig双侧双侧组方差值显著性值相关性对回归参数的显著性检验值自由度差异性显著的检验值可能在大于,有可能小于判断相关性,先看判断相关性,先看p值,看有没有相关性;再看值,看有没有相关性;再看r值,看相关性是强还是弱。
值,看相关性是强还是弱。
sig是差异性显著的检验值,该值一般与0.05或0.01比较,若小于0.05或者0.01则表示差异显著。
所谓双侧的意思是有可能在大于,有可能小于的,而单侧的意思是只有一边或者大于,或者小于的。
1.在SPSS软件统计结果中,不管是回归分析还是其它分析,都会看到“SIG”,SIG=significance,意为“显著性”,后面的值就是统计出的P值,如果P值0.01P0.05,则为差异显著,如果P0.01,则差异极显著。
2.F值是方差检验量,是整个模型的整体检验,看你拟合的方程有没有意义。
自由度指当以样本的统计量来估计总体的参数时,样本中独立或能自由变化的自变量的个数,称为该统计量的自由度。
F值是方差检验量,是整个模型的整体检验,看你拟合的方程有没有意义。
3.在SPSS软件统计结果中,不管是回归分析还是其它分析,都会看到“SIG”,SIG=significance,意为“显著性”,后面的值就是统计出的P值,如果P值0.01P0.05,则为差异显著,如果PFa(k-1,n-k),则拒绝原假设,即认为列入模型的各个解释变量联合起来对被解释变量有显著影响,反之,则无显著影响。
6.P显著性值,也就是sig值或称p值。
CI:
置信区间置信区间(置信区间(Confidenceinterval):
):
置信区间是指由样本统计量所构造的总体参数的估计区间。
在统计学中,一个概率样本的置信区间(Confidenceinterval)是对这个样本的某个总体参数的区间估计。
置信区间展现的是这个参数的真实值有一定概率落在测量结果的周围的程度。
置信区间给出的是被测量参数的测量值的可信程度,即前面所要求的“一定概率”。
这个概率被称为置信水平。
举例来说,如果在一次大选中某人的支持率为55%,而置信水平0.95以上的置信区间是(50%,60%),那么他的真实支持率有百分之九十五的机率落在百分之五十和百分之六十之间,因此他的真实支持率不足一半的可能性小于百分之5。
如例子中一样,置信水平一般用百分比表示,因此置信水平0.95上的置信空间也可以表达为:
95%置信区间。
置信区间的两端被称为置信极限。
对一个给定情形的估计来说,置信水对一个给定情形的估计来说,置信水平越高,所对应的置信区间就会越大。
平越高,所对应的置信区间就会越大。
1、在置信水平相同的情况下,样本量越多,置信区间越窄。
、在置信水平相同的情况下,样本量越多,置信区间越窄。
2、置信区间变窄的速度不像样本量增加的速度那么快,也就是说并不、置信区间变窄的速度不像样本量增加的速度那么快,也就是说并不是样本量增加一倍,置信区间也变窄一半是样本量增加一倍,置信区间也变窄一半(实践证明,样本量要增加4倍,置信区间才能变窄一半),所以当样本量达到一个量时(通常是1,200,如上例三个国家各抽了1,200个消费者),就不再增加样本了。
置信区间置信区间=点估计点估计(关键值(关键值点估计的标准差)点估计的标准差)通过置信区间的计算公式来验证置信区间与样本量的关系。
通过置信区间的计算公式来验证置信区间与样本量的关系。
例如:
对于总体均值的置信区间估计:
公式为:
例如:
对于总体均值的置信区间估计:
公式为:
样本均值样本均值关键值关键值样本均值的标准误差;即样本均值的标准误差;即从上述公式中可以看出:
在其他因素不变的情况下,样本量越多(大),置信区间越窄(小)。
在其他因素不变的情况下,样本量越多(大),置信区间越窄(小)。
2.置信水平对置信区间的影响:
在样本量相同的情况下,置信水平越高,置信区间越宽。
在样本量相同的情况下,置信水平越高,置信区间越宽。
卡方分布(卡方分布(chi-squaredistribution):
若n个相互独立的随机变量、n,均服从标准正态分布(也称独立同分布于标准正态分布),则这n个服从标准正态分布的随机变量的平方和构成一新的随机变量,其分布规律称为卡方分布(chi-squaredistribution)。
若n个相互独立的随机变量、n,均服从标准正态分布(也称独立同分布于标准正态分布),则这n个服从标准正态分布的随机变量的平方和1nniiQ构成一新的随机变量,其卡方分布2。
卡方分布规律称为2分布(chi-squaredistribution),其中参数n称为自由度,正如正态分布中均值或方差不同就是另一个正态分布一样,自由度不同就是另一个2分布。
记为2()Qn或记为2nQ2模型的适配度评价模型的适配度评价应用AMOS的最大似然法对研究假设模型进行了拟合,得到模型的拟合指数,见表3.7。
拟合优度拟合优度拟合优度(拟合优度(GoodnessofFit)是指回归直线对观测值的拟合程度。
度量拟合优度的统计量是)是指回归直线对观测值的拟合程度。
度量拟合优度的统计量是可决系数(亦称确定系数)可决系数(亦称确定系数)R2。
R2的取值范围是的取值范围是0,1。
R2的值越接近的值越接近1,说明回归,说明回归直线对观测值的拟合程度越好;反之,直线对观测值的拟合程度越好;反之,R2的值越接近的值越接近0,说明回归直线对观测值的拟合程,说明回归直线对观测值的拟合程度越差。
度越差。
常用的指标一般是卡方,自由度常用的指标一般是卡方,自由度df,2df:
拟合优度的卡方检验拟合优度的卡方检验RMSEA:
(RootMeanSquareErrorofApproximation,近似误差均方根近似误差均方根))NNFI:
(non-normedfitindex)CFI:
(comparativefitindex,比较拟合指数比较拟合指数)GFI:
(goodness-of-fitindex,拟合优度指数拟合优度指数)AGFI:
(adjustedgoodness-of-fitindex,调整拟合优度指数调整拟合优度指数)SRMR:
(standardizedrootmeansquareresidual,标准化残差均方根标准化残差均方根)绝对拟合指标RMR:
均方根残差:
均方根残差(rootofthemeansquareresidual,RMR)验证性因素分析中评价模型与数据拟合程度时常用的拟合指标验证性因素分析中评价模型与数据拟合程度时常用的拟合指标
(1)(chi-square)检验。
这一指标容易受样本容量的影响,样本量大时,容易达到显著水平,几乎拒绝所有拟合较好的模型。
一般用/df作为替代性检验指数。
/df3表示模型整体拟合度较好,/df5表示模型整体可以接受,/df10表示整体模型非常差。
(2)RMSEA。
若RMSEA取值小于等于0.05,表示数据与定义模型拟合较好;RMSEA取值小于等于0.08时,表示模型与数据的拟合程度可以接受。
(3)其他拟合指数。
常用的有“拟合良好性指标”(goodnessoffitindex,简称GFI)、“调整拟合良好性指标”(adjustedgoodnessoffitindex,简称AGFI)、“常规拟合指标”(normaloffitindex,简称NFI)、“非常规拟合指标”(non-normaloffitindex,简称NNFI)、“比较拟合指标”(comparativefitindex,简称CFI)、“标准化残差均方根”(standardizedrootmeansquareresidual,简称SRMR)、“省俭性指标”(parsimonynormedfitindex,简称PNFI)。
在结构方程模型分析中,我们经常需要得到一个标准化的RMR,即StandardizedRMR,即模型的绝对拟合指标SRMR。
但Amos只会自动生成一个RMR,不会直接输出SRMR,怎么操作呢?
其实很简单的:
首先建立好模型,设置好各个变量和参数,运行分析,检查模型是否可以识别和正常运行出结果,如果不正常则需要检查处理。
其次,对可以正常运行的模型进行操作:
在Plugins中点击最后一个选项“StandardizedRMR”,之后软件会自动弹出一个计算窗口,此时,点击“Calculateestimates”运行分析,计算窗口中会自动计算出SRMR的结果。
2df:
拟合优度的卡方检验拟合优度的卡方检验(2goodness-of-fittest):
2是最常报告的拟合优度指标,与自由度一起使用可以说明模型正确性的概率,2df是直接检验样本协方差矩阵和估计方差矩阵之间的相似程度的统计量,其理论期望值为1。
2df愈接近1,表示模型拟合愈好。
在实际研究中,2df2/df接近2,认为模型拟合较好,样本较大时,5左右也可接受。
GFI:
拟合优度指:
拟合优度指数数(goodness-of-fitindex,GFI)和调整拟合优度指数(adjustedgoodness-of-fitindex,AGFI):
这两个指数值在01之间,愈接近0表示拟合愈差,愈接近1表示拟合愈好。
目前,多数学者认为,GFI0.90,AGFI0.8,提示模型拟合较好(也有学者认为GFI的标准为至少0.80,或0.85)。
CFI:
比较拟合指数:
比较拟合指数(comparativefitindex,CFI):
该指数在对假设模型和独立模型比较时取得,其值在01之间,愈接近0表示拟合愈差,愈接近1表示拟合愈好。
一般认为,CFI0.9,认为模型拟合较好。
TLI:
Tucker-Lewis指数指数(Tucker-Lewisindex,TLI):
该指数是比较拟合指数的一种,取值在01之间,愈接近0表示拟合愈差,愈接近1表示拟合愈好。
如果TLI0.9,则认为模型拟合较好。
RMSEA:
近似误差均方根:
近似误差均方根(root-mean-squareerrorofapproximation,RMSEA):
RMSEA是评价模型不拟合的指数,如果接近0表示拟合良好,相反,离0愈远表示拟合愈差。
一般认为,如果RMSEA=0,表示模型完全拟合;RMSEA0.05,表示模型接近拟合;0.05RMSEA0.08,表示模型拟合合理;0.08RMSEA0.10,表示模型拟合一般;RMSEA0.10,表示模型拟合较差。
RMR:
均方根残差:
均方根残差(rootofthemeansquareresidual,RMR):
该指数通过测量预测相关和实际观察相关的平均残差,衡量模型的拟合程度。
如果RMR0.1,则认为模型拟合较好。
一般认为,如果RMSEA在0.08以下(越小越好),GFI、NNFI和CFI在0.9以上(越大越好),所拟合的模型是一个“好”模型。
AGFI(a
 升级会员
升级会员 