数据结构练习答案资料.docx
《数据结构练习答案资料.docx》由会员分享,可在线阅读,更多相关《数据结构练习答案资料.docx(16页珍藏版)》请在冰豆网上搜索。
数据结构练习答案资料
数据结构练习
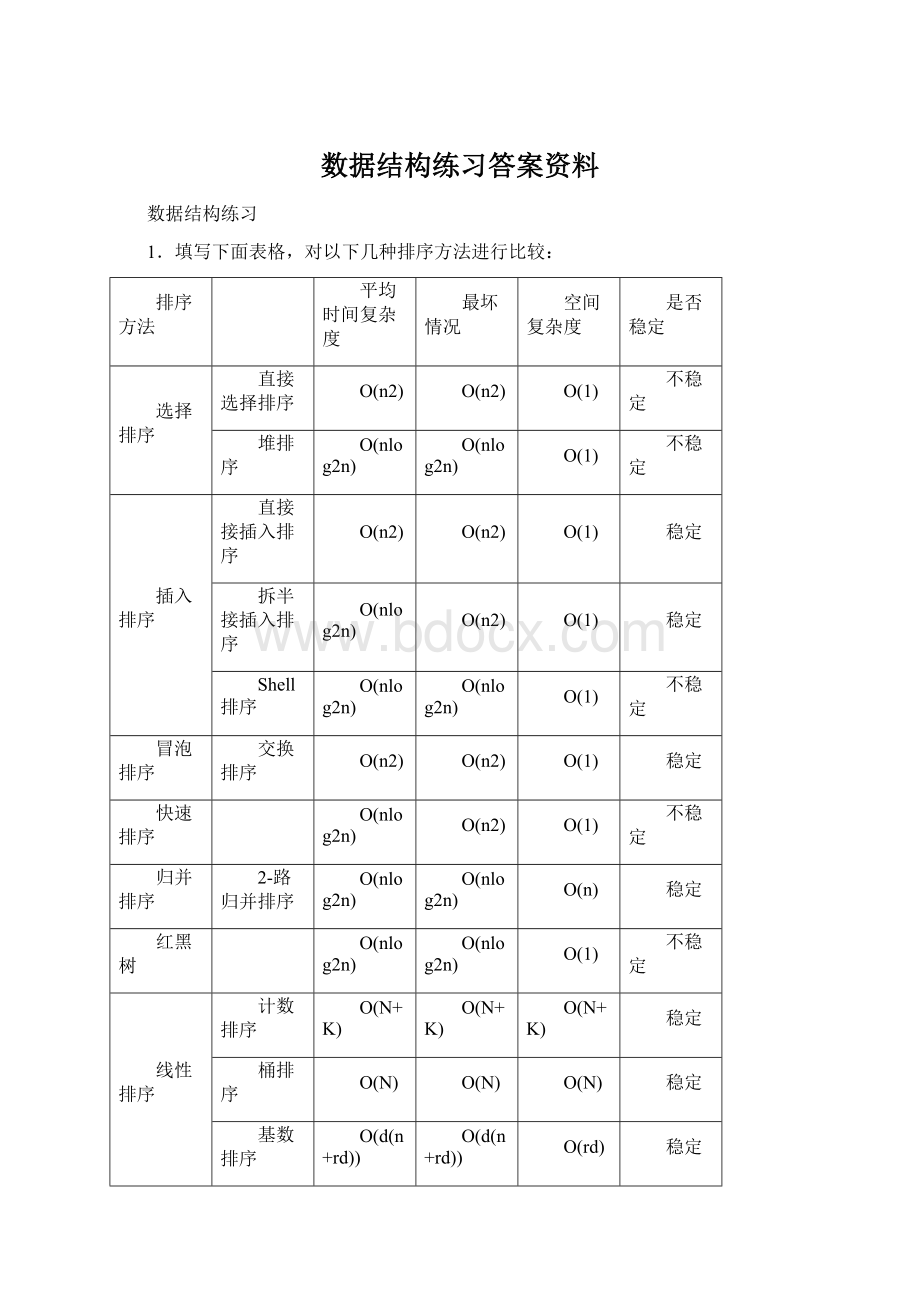
1.填写下面表格,对以下几种排序方法进行比较:
排序方法
平均时间复杂度
最坏情况
空间复杂度
是否稳定
选择排序
直接选择排序
O(n2)
O(n2)
O
(1)
不稳定
堆排序
O(nlog2n)
O(nlog2n)
O
(1)
不稳定
插入排序
直接接插入排序
O(n2)
O(n2)
O
(1)
稳定
拆半接插入排序
O(nlog2n)
O(n2)
O
(1)
稳定
Shell排序
O(nlog2n)
O(nlog2n)
O
(1)
不稳定
冒泡排序
交换排序
O(n2)
O(n2)
O
(1)
稳定
快速排序
O(nlog2n)
O(n2)
O
(1)
不稳定
归并排序
2-路归并排序
O(nlog2n)
O(nlog2n)
O(n)
稳定
红黑树
O(nlog2n)
O(nlog2n)
O
(1)
不稳定
线性排序
计数排序
O(N+K)
O(N+K)
O(N+K)
稳定
桶排序
O(N)
O(N)
O(N)
稳定
基数排序
O(d(n+rd))
O(d(n+rd))
O(rd)
稳定
解释:
时间复杂度O(d(n+rd)):
其中分配为O(n);收集为O(rd)(r为基、d为“分配-收集”的趟数)
习题
一.填空题
1.进栈序列是1、2、3、4,进栈过程中可以出栈,则可能的出栈序列有个,不可能的出栈序列是。
2.具有N个元素的顺序存储的循环队列中,假定front和rear分别指向队头元素的前一位置和队尾元素的位置,则判断队空的和队满的条件分别是f=r和f=rmodm+1。
求此队列中元素个数的计算公式为:
((r+m)-f-1)modm+1。
入队运算:
r:
=rmodm+1。
出队运算:
f:
=fmodm+1。
3.单链表是非顺序线性的链式存储结构,链栈和链队分别是和的链式存储结构。
4.线性表的顺序存储中,元素之间的逻辑关系是通过元素存储地址次序决定的,在线性表的链接存储中,元素之间的逻辑关系是通过元素存储指针地址访问决定的。
5.深度为5的二叉树至多有结点数为31。
6.数据结构即数据的逻辑结构包括顺性存储结构、链式存储结构、非线性结构三种类型,树型结构和图型结构称为非线性结构。
?
?
?
四种基本存储方法:
(1)顺序存储方法
(2)链接存储方法(3)索引存储方法(4)散列存储方法
二.选择题
1.有一个10阶对称矩阵,采用压缩存储方式,以行序为主序存储,A[0][0]的地址为1,则A[7][4]的地址为(C)
A13B.18C.33D.40
2.线性表采用链表存储时其存储地址D。
A.必须是连续的B.部分地址必须是连续的
C.一定是不连续的D.连续不连续都可以
3.下列叙述中错误的是C。
A.串是一种特殊的线性表,其特殊性体现在数据元素是一个字符
B.栈和队列是两种特殊的线性表,栈的特点是后进先出,队列的特点是先进先出。
C.线性表的线性存储结构优于链式存储结构
D.二维数组是其数据元素为线性表的线性表
4.一棵二叉树的顺序存储结构如题图4-1所示,若中序遍历该二叉树,则遍历次序为A.
A.DBEGACFHB.ABDEGCFH
C.DGEBHFCAD.ABCDEFGH
1234567891011121314
A
B
C
D
E
F
G
H
题图4-1
5.设一棵二叉树的顺序存储结构如题图4-2所示,则该二叉树是C.
A.完全二叉树B.满二叉树C.深度为4的二叉树
D.深度为3的二叉树
1234567891011
1
2
3
4
5
6
7
题图4-2
6.设T是Huffman树,它具有6个树叶,且各树叶的权分别为1,2,3,4,5,6。
那么该树的非叶子结点的权之和为A。
A.51B.21C.30D.49
7.设有一无向图的邻接矩阵如下所示,则该图所有顶点的度之和为C。
abcde
a01110
b10101
c11000
d10000
e01000
A.8B.9C.10D.11
8.已知二叉树的后序遍历序列是fedbgca,中序遍历序列是dfebagc,则该二叉树的先序遍历序列是D。
A.defbagcB.abcdgefC.dbaefcgD.abdefcg
9.由三个结点构成的二叉树,共有C种不同的形态。
A.3B.4C.5D.6
10.在一个具有n个顶点的无向图中,要连通全部顶点至少需要D条边
A.nB.n+1C.n/2D.n-1
11.对线性表进行折半(二分)查找时,要求线性表必须B。
A.以顺序方式存储B.以顺序方式存储且数据元素有序
C.以链表方式存储D.以链表方式存储且数据元素有序
12.顺序查找一个具有n个元素的线性表,其时间复杂度为A,二分查找一个具有n个元素的线性表,其时间复杂度为B。
A.O(n)B.O(log2n)C.O(n2)D.O(nlog2n)
13.从未排序序列中依次取出元素与已排序序列中的元素进行比较,将其放入已排序序列中的正确位置上,此方法称为直接插入排序;从未排序序列中挑选元素,并将其放入已排序序列中的一端,此方法称为直接选择排序;依次将每两个相临的有序表合并成一个有序表的排序方法称为归并排序;当两个元素比较出现反序时就相互交换位置的排序方法称为交换排序;
A.归并排序B.选择排序
C.交换排序D.插入排序
三.
图4-3
简述下面的几个概念:
单链表,栈、队列,排序二叉树。
四.简述空串和空格串的区别。
五.一棵度为2的树与二叉树有何区别?
六.试分别画出具有3个结点的树和具有3个结点的二叉树的所有不同形态。
七.已知一二叉树如题图4-3所示,
1.用二叉链表和顺序存储方式分别存储此二叉树。
画出相应的存储结构图。
2.写出此二叉树的中序、先序、后序遍历序列。
八.
题图4-4
已知一无向图如题图4-4所示,请给出该图的
1.每个顶点的度。
2.邻接矩阵
3.邻接表
4.按上述的邻接表写出广度和深度遍历序列。
九.已知一组数据元素为(46,75,18,54,15,27,42,39,88,67)
1.利用直接插入排序方法,写出每次插入后的结果。
2.利用快速排序方法,写出每趟排序后的结果。
3.利用2-路归并排序方法,写出每趟归并后的结果。
4.利用冒泡排序方法,写出每趟排序后的结果。
一十.假定一个表为(32,75,63,48,94,25,36,18,70),散列空间为[0..10],
1.若采用除留余数法构造表,哈希函数为H(K)=KMOD11,用线性探测法解决冲突,试画出哈希表,并求在等概率情况下的平均查找长度。
2.若采用除留余数法构造表,哈希函数为H(K)=KMOD11,用链地址法解决冲突,试画出哈希表,并求在等概率情况下的平均查找长度。
一十一.有8个带权结点,权值为(3,7,8,2,6,10,14,9),试以它们为叶子结点构造一棵哈夫曼树(要求每个结点左子树的权值小于等于右子树的权值),并计算出带权路径长度。
一十二.一对称阵An*n,若只存储此对称阵的上半三角元,写出以行为主序存储和以列为主序存储时计算每一元素Aij存储地址的公式。
一十三.算法设计
1.写出在循环单链表L中查找查找第i个元素的算法:
SEARCH(L,i)。
2.设有如下题图4-3的单链表,链表头指针为H,写一个将链表进行逆转的算法,逆转以后的链表为题图4-4所示。
题图4-3单链表示意图
题图4-4单链表示意图
3.假定用一个带头结点的循环单链表表示循环队列(循环链队),该队列只设一个队尾指针,不设头指针,试编写下面的算法:
A.向循环链队中插入一个元素x的算法(入队)。
B.从循环链队中删除一个结点(出队)。
4.数组A[N]存放循环队列中的元素,同时设两个变量分别存储队尾元素的位置和队列中实际元素个数。
A.写出此队列的队满条件。
B.写出此队列的出、入队算法。
5.设LA和LB为两个顺序存储的线性表,且元素按非递减排列,写出算法将其合并为LC,且LC中的元素也按非递减排列。
6.已知一个由n个整数组成的线性表,请定义该线性表的一种存储结构,并用C语言编写算法,实现将n个元素中所有大于等于20的整数放在所有小于等于20的整数之后,要求算法的时间复杂度为O(n),空间复杂度为O
(1)。
7.编写算法,计算二叉树中叶子结点的数目。
8.编写一个按层次顺序(同一层自左向右)遍历二叉树的算法。
三种基于“分配”“收集”的线性排序算法---计数排序、桶排序与基数排序
文中代码见原文链接:
[非基于比较的排序]
在计算机科学中,排序是一门基础的算法技术,许多算法都要以此作为基础,不同的排序算法有着不同的时间开销和空间开销。
排序算法有非常多种,如我们最常用的快速排序和堆排序等算法,这些算法需要对序列中的数据进行比较,因为被称为基于比较的排序。
基于比较的排序算法是不能突破O(NlogN)的。
简单证明如下:
N个数有N!
个可能的排列情况,也就是说基于比较的排序算法的判定树有N!
个叶子结点,比较次数至少为log(N!
)=O(NlogN)(斯特林公式)。
而非基于比较的排序,如计数排序,桶排序,和在此基础上的基数排序,则可以突破O(NlogN)时间下限。
但要注意的是,非基于比较的排序算法的使用都是有条件限制的,例如元素的大小限制,相反,基于比较的排序则没有这种限制(在一定范围内)。
但并非因为有条件限制就会使非基于比较的排序算法变得无用,对于特定场合有着特殊的性质数据,非基于比较的排序算法则能够非常巧妙地解决。
本文着重介绍三种线性的非基于比较的排序算法:
计数排序、桶排序与基数排序。
[计数排序]
首先从计数排序(CountingSort)开始介绍起,假设我们有一个待排序的整数序列A,其中元素的最小值不小于0,最大值不超过K。
建立一个长度为K的线性表C,用来记录不大于每个值的元素的个数。
算法思路如下:
∙扫描序列A,以A中的每个元素的值为索引,把出现的个数填入C中。
此时C[i]可以表示A中值为i的元素的个数。
∙对于C从头开始累加,使C[i]<-C[i]+C[i-1]。
这样,C[i]就表示A中值不大于i的元素的个数。
∙按照统计出的值,输出结果。
由线性表C我们可以很方便地求出排序后的数据,定义B为目标的序列,Order[i]为排名第i的元素在A中的位置,则可以用以下方法统计。
?
ViewCodeCPP
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
 升级会员
升级会员 