SAS学习系列26Logistic回归.docx
《SAS学习系列26Logistic回归.docx》由会员分享,可在线阅读,更多相关《SAS学习系列26Logistic回归.docx(37页珍藏版)》请在冰豆网上搜索。
SAS学习系列26Logistic回归
26.Logistic回归
(一)Logistic回归
一、原理
二元或多元线性回归的因变量都是连续型变量,若因变量是分类变量(例如:
患病与不患病;不重要、重要、非常重要),就需要用Logistic回归。
Logistic回归分析可以从统计意义上估计出在其它自变量固定不变的情况下,每个自变量对因变量取某个值的概率的数值影响大小。
Logistic回归模型有“条件”与“非条件”之分,前者适用于配对病例对照资料的分析,后者适用于队列研究或非配对的病例-对照
研究成组资料的分析。
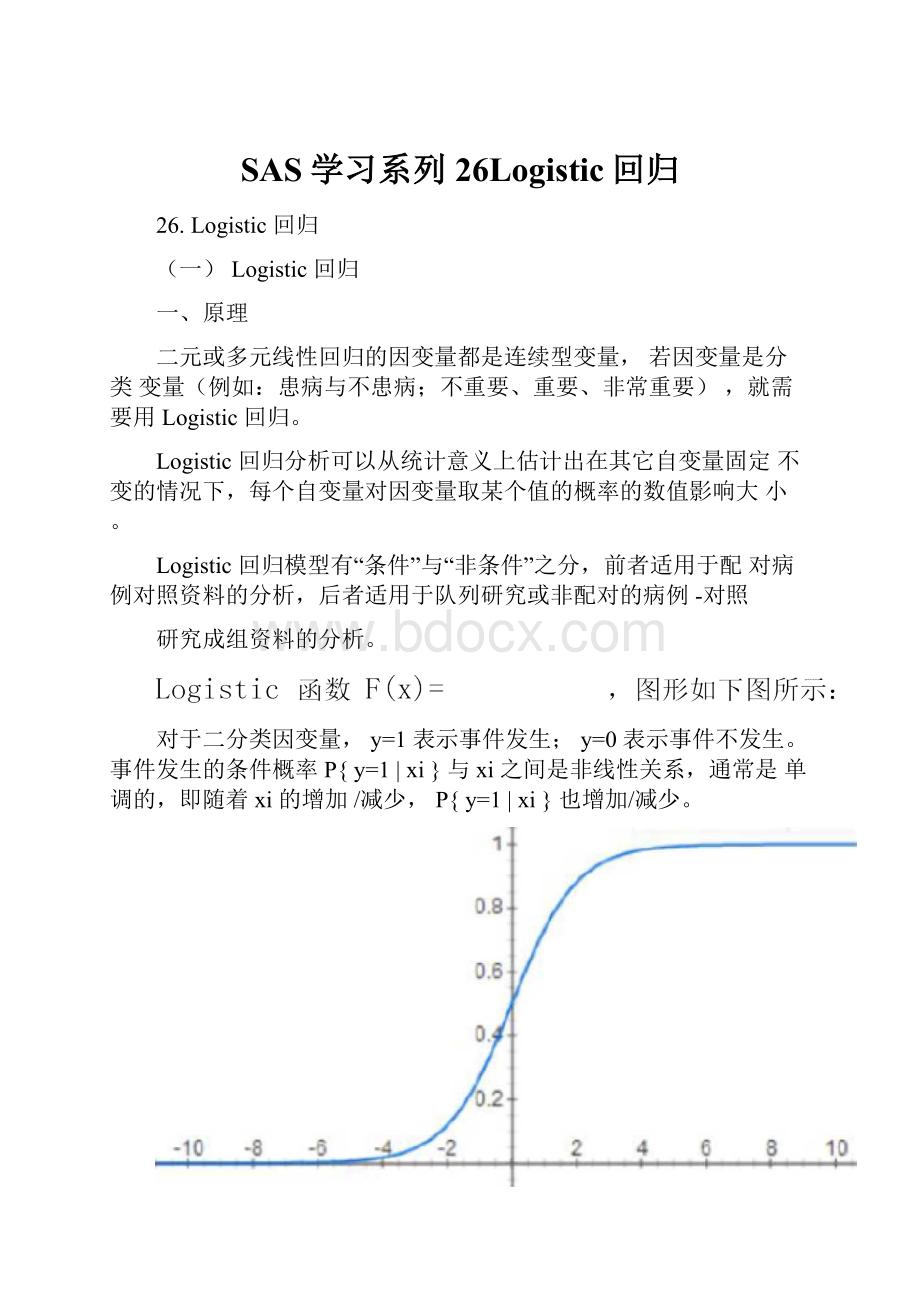
对于二分类因变量,y=1表示事件发生;y=0表示事件不发生。
事件发生的条件概率P{y=1|xi}与xi之间是非线性关系,通常是单调的,即随着xi的增加/减少,P{y=1|xi}也增加/减少。
该函数值域在(0,1)之间,x趋于-∞时,F(x)趋于0;x趋于+∞时,F(x)趋于1.正好适合描述概率P{y=1|xi}.例如,某因素x导致患病与否:
x在某一水平段内变化时,对患病概率的影响较大;而在x较低或较高时对患病概率影响都不大。
记事件发生的条件概率P{y=1|xi}=pi,则
pi=
记事件不发生的条件概率为
1-pi=
则在条件xi下,事件发生概率与事件不发生概率之比为
称为事件的发生比,简记为odds.对odds取自然对数得到
上式左边(对数发生比)记为Logit(y),称为y的Logit变换。
可见
变换之后的Logit(y)就可以用线性回归,计算出回归系数α和β值。
元线性回归:
二、回归参数的解释
1.三个名词
发生比(odds)==
例如,事件发生概率为0.6,不发生概率为
0.4,
则发生比为1.5(发
生比>1,表示事件更可能发生)。
发生比率(OR)===
=
即主对角线乘积/副对角线乘积,也称为交叉积比率,优势比。
例如,
说明:
大于1(小于1)的发生比率,表明事件发生的可能性会提高(降低),或自变量对事件概率有正(负)的作用;发生比率为1表示变量对事件概率无作用。
相对风险(RR)==用来进行两组概率之间的比较。
当p1=p2时,相对风险为1,表明两组在事件发生方面没有差别。
2.连续型自变量回归参数的解释
截距α:
基准发生比的对数,即当Logistic回归模型中没有任何自变量时(除常量外,所有自变量都取0值)所产生的发生比。
由于理解发生比,比理解对数发生比更容易,故将Logistic回归模型改写为:
odds==
若βk>0(βk<0),则>1(<1),即xk每增加一个单位值时发生比会相应增加(减少);若βk=0,则=1,那么xk不论怎样变化发生比都不会变化。
反映了自变量xk增加一个单位时发生比所变化的倍数,即
(xk+1)时的发生比与原发生比【(xk)时】之比。
自变量xk每变化一个单位,发生比率的变化率为
注:
由于βk是自变量xk的偏系数估计,故称为调整发生比率(AOR)的估计。
实际中,往往更关心的不是自变量变化1个单位,而是变化一段水平b-a个单位,例如年龄每增加5岁,此时调整发生比率为
AOR=
3.二分类自变量回归参数的解释二分类变量,例如性别,取值可以用0或1编码,也称为标志变量或虚拟变量。
若xk为取值0或1的二分类变量,则有
ln(pi)xk11x1Lk1
1pixk111k
pi
ln(i)xk01x1Lk0
1pik
两式作差得
可见βk就是在控制其它变量条件下,xk=1与xk=0的对数发生比的差;
也即是发生比率的对数,即调整发生比率的估计可表示为
(odds)xk1vsxk0
注意,发生比率是
,而不是两者概率比
4.多分类变量的处理与回归参数的解释
当分类自变量多于两个类别时,需要建立一组虚拟变量来代表类型的归属性质。
若一个分类变量包括m个类别,则可以产生m个相应的虚拟变量,但建模需要的虚拟变量的数目为m-1.省略的那个类别作为参照类。
例如,年龄是有序变量,按年龄段分为四个类别:
x<40,40≤x<50,50≤x<60,x≥60.
设置3个虚拟变量Age1表示40≤x<50(属于该年龄段则Age1=1,否则Age1=0);Age2表示50≤x<60(属于该年龄段则Age2=1,否则Age2=0);Age3表示x≥60(属于该年龄段则Age3=1,否则Age3=0);另一个不指定虚拟变量的x<40作为参照类(Age1,Age2,Age3都为0;哪一类作为参照类是随意的,取决于偏好或解释的方便)。
则模型为
p
ln()1Age12Age23Age3
1p112233同二分类变量时一样,β1代表40≤x<50与参照类(Age0:
x<40)在因变量上的差别,故
β1=ln(odds)Age1vsAge0
且40≤x<50对x<40的发生比率为.
注:
(1)名义变量直接就是分类变量;连续变量也可以改为分类
变量,例如考试成绩按分数段分为高、中、低三档。
(2)另外,也可采用效应变量编码,三种取值:
-1,0(参照类),1.
(3)用SAS中CLASS语句指定分类变量,可以自动进行效应编码,作为一组变量纳入模型,并对每一类别单独做显著性检验。
5.用概率解释自变量的作用
(1)对事件发生概率的偏作用,可用Logit函数求该自变量的偏导数来刻画:
P{y1|xk}
kkp(p1)
xk
其中p为事件发生概率。
对于二元Logistic回归,p=0.5时,斜率
最陡,此时x=-α/β,称为中位有效水平。
(2)利用得到的Logistic回归方程,可以预测概率:
变化:
P{y1|x,xkVxk}P{y1|x,xk}
三、标准化系数
通常在线性回归模型中的连续型自变量是以不同尺度度量的,这就使得某自变量中一个单位的变化并不等价于另一自变量上一个单位的变化。
因此,要使用标准化系数(使得因变量的作用具有可比性)。
标准化系数表示自变量的一个标准差的变化所导致的因变量上以其标准差为单位度量的变化。
有两种标准化的方法:
(1)先回归再标准化;
(2)先标准化x,y再回归;注:
对于分类变量,例如性别、民族等,变量的标准化是没有意义的。
但其尺度标准要一致,比如0,1,2,3都变成1,2,3,4.
四、偏相关
偏相关,用来刻画在控制其他变量下,某自变量对Logistic回归
的贡献(依赖于其它变量)。
偏相关系数计算公式如下:
其中,d.f.为自由度,分母为-2倍的截距模型(只有截距)的对数似然值。
五、回归参数的估计
Logistic回归参数的估计通常采用最大似然法,其基本思想是先建立似然函数与对数似然函数,再通过使对数似然函数最大求解相应的参数值,所得到的估计值称为参数的最大似然估计值。
假设有N个案例构成的总体,Y1,⋯,YN.从中随机抽取n个案例作为样本,观测值标注为y1,⋯,yn.设pi=P(yi=1|xi)为给定xi的条件下得到结果yi=1的条件概率,而在同样条件下得到结果为yi=0的条件概率为P(yi=0|xi)=1-pi.于是,得到一个观测值的概率为
P(yi)piyi(1pi)1yi
其中,yi=1或yi=0.当yi=1时,P(yi)=pi=P(yi=1|xi).
由于各项观测相互独立,故它们的联合分布可表示为各边际分布的乘积:
n
L()piyi(1pi)1yi
i1称为n个观测的似然函数。
对于Logistic回归,piexi/(1exi).根据最大似然原理,估计参数α和β使得似然函数L(θ)最大,令
n
ln[L()][yi(xi)ln(1exi)]
i1称为对数似然函数,也即让ln[L(θ)]最大。
令
采用牛顿迭代法解出α和β的估计值
六、假设检验
1.似然比检验
H0:
β1=β2=⋯=βp=0
统计量
L2R2(lnL0lnL1)2lnL0(2lnL1)服从自由度为变量个数该变量(从L0到L1)的卡方分布。
若P值<0.05,则拒绝原假设。
2.比分检验
以未包含某个或几个变量的模型为基础,保留模型中参数的估计值,并假设新增加的参数为零,计算似然函数的一价偏导数(也称“有效比分”)及信息距阵,两者相乘便得比分检验的统计量S.样本量较大时,S近似服从自由度为待检验因素个数的2分布。
3.Wald检验
即广义的T检验,统计量为
WZ2[?
k/SE?
k]2
其中SE?
为?
k的标准误。
H0:
βk=0为真时,Z为标准正态分布,Wk
服从自由度为1的渐近2分布
βk的95%置信区间估计为:
?
kZSE?
?
k1.96SE?
.
kk
注:
上述三种方法中,似然比检验最可靠,比分检验一般与它相一致,但两者均要求较大的计算量;而Wald检验未考虑各因素间的综合作用,在因素间有共线性时结果不如其它两者可靠。
为计算方便,通常向前选取变量用似然比或比分检验,而向后剔除变量常用Wald检验。
七、模型的评价——拟合优度检验检查模型估计与实际数据的符合情况。
检验统计量:
1.剩余差D;2.皮尔逊χ2若统计量的P值>0.05,则认为模型拟合较好
二)PROCLOGISTIC过程步
基本语法:
PROCLOGISTICdata=数据集<可选项>;
CLASS分类变量;
FREQ频数变量;
);>
MODEL因变量<(变量选项)>=自变量列表;
variable;>;>
<>变<量/可选项>;>
;>
注:
CLASS,EFFECT语句必须在MODEL语句之前;CONTRAST,EXACT,ROC语句必须在MODEL语句之后。
说明:
(1)输入数据集可选项
DESCENDING——指定因变量按降序排序(“y=1”放前面);
ORDER=——指定因变量的排序顺序;
PLOT——绘图选项;
(2)EFFECT语句用原变量数据创建某种效应设计矩阵做对比用,例如LAG效应
等。
(3)CLASS语句
对分类变量进行0-1化处理,变成虚拟变量;
(4)MODEL语句
是必不可少的,用来指定因变量和自变量。
可以用可选项指定
“y=1”,例如:
modelremiss(event='1')=cellsmearinfilliblasttemp;
可选项:
selection=stepwise/forward/backwardsle或sls——指定变量进入或剔除出模型的显著水平;Aggregate和scale=n|p|d计算偏差和pearson卡方拟和优度统计量,n表示对离差参数不进行校正;p规定离差参数的估计为pearson卡方统计量除以自由度;d规定离差参数的估计为偏差除以自由度;alpha=——设置置信限;cl/clparm=WALD——估计所有参数/WALD参数的置信区间;
plrl——对自变量估计比数比的置信区间;influence——做回归诊断;RSQUARE——输出拟合的调整的R2;EFFECTPLOT——输出模型拟合统计量;
(5)ESTIMATE语句——用来估计效应变量的线性组合的值;(6)EXACT语句用其它变量的充分统计量对变量的充分统计量做精确检验;(7)CONTRAST语句
用来检验均值的线性组合关系的原假设。
有三个基本参数,一是标签,二是分类变量名,三是效应均值线性组合的系数表(系数的次
序是匹配分类变量按字母数字次序的水平值)。
示例:
contrast'USvsNON-U.S.'brand11-2;
检验H0:
β1+β2-2β3=0
(8)ROC语句——绘制ROC曲线;
(9)SCORE语句——输出若干结果到数据集。
(10)TEST语句对系数关系式做检验,示例:
(ai为自变量名)
test1:
testintercept+
.5*a2=0;
test2:
testintercept+
.5*a2;
test3:
testa1=a2=a3;
test4:
testa1=a2,a2=a3;
例1不同治疗方法对某病疗效的影响研究:
用Logistic回归模型P{effect=1|treat}=拟合,即
Logit(p)=ln(
代码:
dataeffects;
inputtreateffectcount;
cards;
1116
1048
2140
2020
proclogisticdata=effectsDESCENDING;
前面
freqcount;
modeleffect=treat;/*或者用modeleffect(event='1')=treat;
就可以不用DESCENDING选项了*/
run;
运行结果及说明:
响应概况
有序effect总频数
值
1156
2068
建模的概率为effect=1。
模型收敛状态
模型收敛状态
满足收敛准则(GCONV=1E-8)
模型拟合统计量
准则
仅截距
截距和协变量
AIC
172.737
152.361
SC
175.558
158.001
-2L
170.737
148.361
检验全局零假设:
BETA=0
检验
卡方
自由度
Pr>卡方
似然比
22.3768
1
<.0001
评分
21.7087
1
<.0001
Wald
20.2762
1
<.0001
假设检验H0:
β1=⋯=βk=0.似然比检验的卡方值=-2lnL0–(-2lnLk)=170.737–148.361=22.3768.自由度为1-0=1(只有截距0个变量,到1个变量),P值<0.0001<α=0.05.故拒绝H0.
最大似然估计值分析
参数
自由度
估计值
标准Wald卡方Pr>卡方
误差
Intercept
1
-2.8904
0.6390
20.4594
<.0001
treat
1
1.7918
0.3979
20.2762
<.0001
回归方程为:
Logit(p)=-2.8904+1.7918*treat
优比估计值
效应点估计值95%Wald置信限
treat6.0002.75113.087
发生比率(OR)=6.000.
预测概率和观测响应的关联
一致部分所占百分比
50.4
SomersD
0.420
不一致部分所占百分比
8.4
Gamma
0.714
结值百分比
41.2
Tau-a
0.210
对
3808
c
0.710
例2研究性别、疾病的严重程度对疾病疗效的影响,得数据如下:
拟合回归方程为Logit(p)=α+β1Sex+β2Degree.代码:
dataeffects2;
inputsexdegreeeffectcount@@;cards;
00121000601190109
101810010111411011
run;
proclogisticdata=effects2DESCENDING;
freqcount;
modeleffect=sexdegree/scale=noneaggregate;*模型的拟合优度检验;
outputout=predictpred=prob;*output语句设置输出结果,这里结果存在predict数据中,预测值为prob;
run;
procprintdata=predict;
run;
*考虑两个自变量的交互作用;
proclogisticdata=effects2DESCENDING;
freqcount;
modeleffect=sexdegreesex*degree;
run;
运行结果:
响应概况
有序effect总频数
值
1142
2036
建模的概率为effect=1。
模型收敛状态
满足收敛准则(GCONV=1E-8)
偏差和Pearson拟合优度统计量
准则值自由度值/自由度Pr>卡方
偏差0.214110.21410.6436
Pearson0.215510.21550.6425
剩余差D和Pearson拟合优度检验的P值分别为0.6436和
0.6425都远大于0.05,故拟合结果较好可以接受。
唯一轮廓数:
4
模型拟合统计量
准则
仅截距
截距和协变量
AIC
109.669
101.900
SC
112.026
108.970
-2L
107.669
95.900
检验全局零假设:
BETA=0
检验
卡方
自由度
Pr>卡方
似然比
11.7694
2
0.0028
评分
11.2410
2
0.0036
Wald
10.0644
2
0.0065
假设检验H0
故拒绝H0.
参数
:
β1=⋯=βk=0.似然比检验的P值=0.0028<α=0.05.
最大似然估计值分析
自由度估计值标准Wald卡方Pr>卡方
误差
最大似然估计值分析
参数
自由度
估计值
标准Wald卡方Pr>卡方
误差
Intercept
1
1.1568
0.4036
8.2167
0.0042
sex
1
-1.2770
0.4980
6.5750
0.0103
degree
1
-1.0545
0.4980
4.4844
0.0342
拟合回归方程为:
Logit(p)=1.1568-1.2770*Sex–
1.0545*Degree
优比估计值
效应
点估计值
95%Wald
置信限
sex
0.279
0.1050.740
degree
0.348
0.1310.924
优势比(OR):
男性(Sex=1)治愈与未治愈的比值为:
p1/(1-p1)=exp(1.1568-1.2770*1–1.0545*Degree)女性(Sex=0)治愈与未治愈的比值为:
p0/(1-p0)=exp(1.1568-1.2770*0–1.0545*Degree)两个比值的比即优势比为:
OR=[p1/(1-p1)]/[p0/(1-p0)]==e-1.2770=0.279
预测概率和观测响应的关联
预测概率和观测响应的关联
一致部分所占百分比
60.0
SomersD
0.419
不一致部分所占百分比
18.1
Gamma
0.536
结值百分比
21.9
Tau-a
0.211
对
1512
c
0.709
Obs
sex
degree
effect
count
_LEVEL_
prob
1
0
0
1
21
1
0.76075
2
0
0
0
6
1
0.76075
3
0
1
1
9
1
0.52555
4
0
1
0
9
1
0.52555
5
1
0
1
8
1
0.46999
6
1
0
0
10
1
0.46999
7
1
1
1
4
1
0.23601
8
1
1
0
11
1
0.23601
输出预测概率。
最大似然估计值分析
参数自由度估计值标准Wald卡方Pr>卡方
误差
最大似然估计值分析
参数
自由度
估计值
标准
Wald卡方
Pr>卡方
误差
Intercept
1
1.2528
0.4629
7.3239
0.0068
sex
1
-1.4759
0.6628
4.9587
0.0260
degree
1
-1.2528
0.6607
3.5954
0.0579
sex*degree
1
0.4643
1.0012
0.2151
0.6428
Sex*Degree的卡方检验P值=0.6428远大于其它参数的P值,故不用考虑该交互作用的影响。
例3多分类自变量的虚拟变量处理(CLASS语句将会自动完成自变量的“虚拟变量化”处理过程,因变量不需要用CLASS语句处理),以及对比检验(CONTRAST语句)。
代码:
datauti;
inputdiagnosis:
$13.treatment$response$count@@;
datalines;
 升级会员
升级会员 