统计学试验打印.docx
《统计学试验打印.docx》由会员分享,可在线阅读,更多相关《统计学试验打印.docx(81页珍藏版)》请在冰豆网上搜索。
统计学试验打印
实验一SPSS统计软件简介
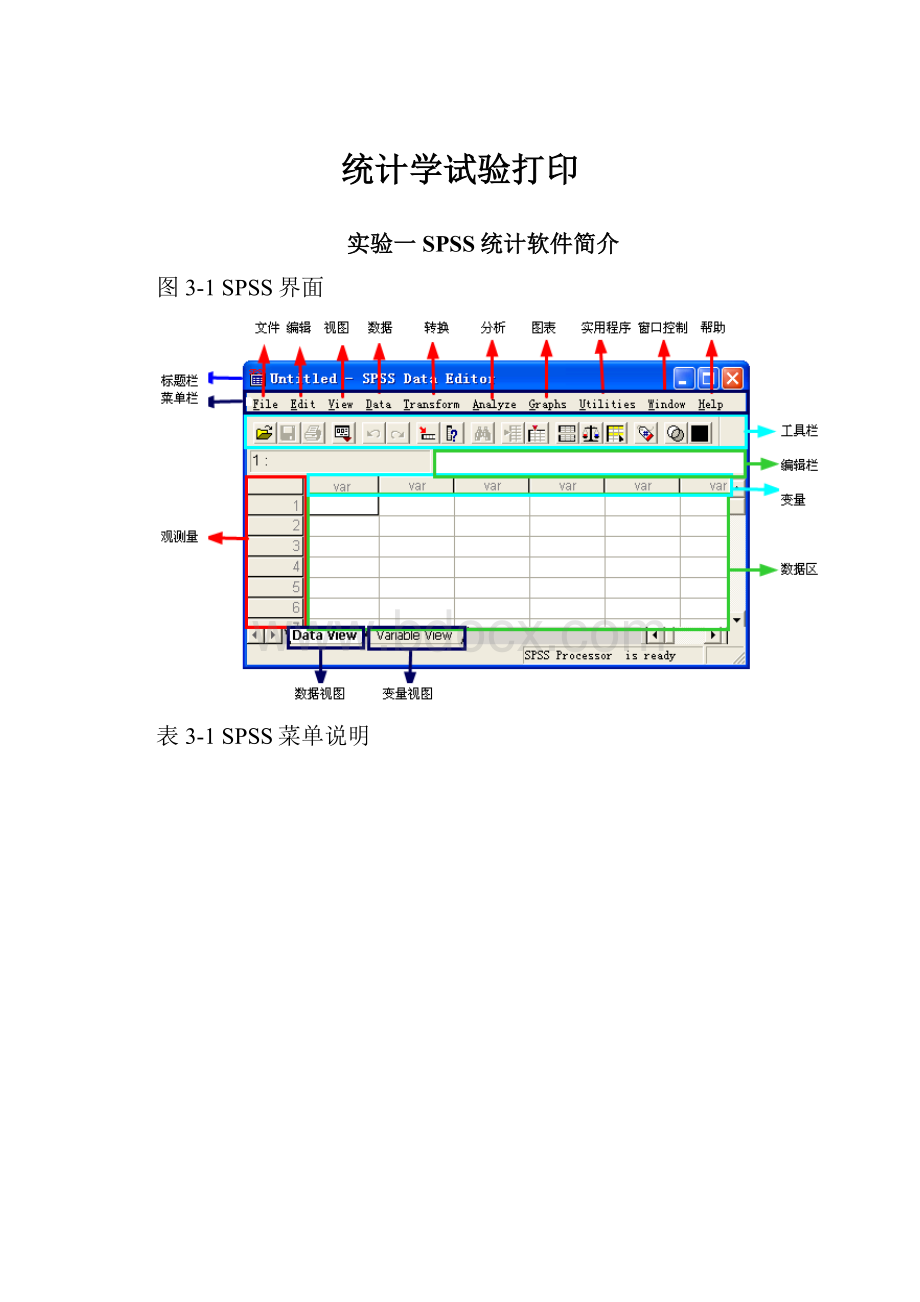
图3-1SPSS界面
表3-1SPSS菜单说明
图3-2File
图3-3Data
图3-4Analyze
图3-5DescriptiveStatistics
图3-6CompareMeans
图3-7NonparametricTest
图3-8Graphs
实验二数值变量资料的统计描述
二、实验要求:
1、掌握定量资料频数分布的两大特征
2、掌握定量资料两大趋势的各种指标的计算方法和应用条件
3、掌握用SPSS计算两大趋势的各种指标
三、实验内容:
1、频数分布的两大特征:
集中趋势和离散趋势
2、应用SPSS绘制频数分布表
3、利用SPSS计算两大趋势各种指标
四、实验资料
例4-1某校诊断学基础教研室为研究健康成年女性体温正常值,随机抽取102名健康(非排卵期)女大学生测试其体温,下列是测试午饭后休息一小时口腔温度(℃)的结果,试编制频数分布表。
表4-1(7-1)102名健康女大学生口腔温度测试结果(℃)
37.0
36.9
37.2
37.1
37.0
36.8
36.8
37.4
37.0
36.8
37.2
37.0
37.0
36.9
36.8
37.1
37.1
36.8
37.4
37.4
37.3
37.4
37.2
37.1
37.1
36.8
36.8
37.0
37.0
36.9
37.3
37.2
36.9
37.0
36.8
37.1
37.0
37.1
37.1
37.2
37.5
37.0
37.3
37.0
37.1
37.0
37.0
37.3
37.1
37.1
37.2
37.2
36.9
37.0
37.1
37.0
36.9
37.0
37.0
36.9
36.5
36.8
37.0
36.6
37.0
37.2
36.7
37.2
36.9
37.3
36.8
36.7
37.1
37.1
37.0
36.9
37.2
36.9
37.0
36.7
36.9
36.8
36.7
36.9
37.1
36.9
37.0
36.9
37.3
37.0
37.0
37.0
37.3
37.1
37.2
36.6
36.6
36.9
36.9
36.9
36.7
36.8
4-1.1准备数据:
激活变量窗口,定义体温的变量名为T,然后输入体温的原始数据,结果见图4-1。
注:
a变量命名(Name)应该遵循以下原则:
a.1SPSS变量的变量名由不多于8个字符组成;
a.2首字符是字母,其后可为字母或数字或除“?
”、“一”、“!
”和“*”以外的字符。
但应该注意,不能以下划线“_”和圆点“.”作为变量名的最后一个字符。
a.3变量名不能与SPSS保留字相同。
SPSS的保留字有:
ALL、AND、BY、EQ、GE、GT、LE、LT、NE、NOT、OR、TO、WITH。
a.4系统不区分变量名中的大小写字符。
例如:
ABC和abc被认为是同一个变量。
b定义变量类型:
定义变量类型对话框左半部列有8种可供选择的变量类型,自上至下标明的变量类型为:
Numeric标准数值型、Comma带逗点的数值型、Dot逗点作小数点的数值型、ScientificNotation科学记数法、Date日期型、Dollar带有美元符号的数值型、CustomCurrency自定义型、String字符型。
c变量标签(VariableLabels)
变量标签是对变量名的附加的进一步说明。
变量名只能由不超过8个字符组成。
如果8个字符不足以表示变量的含义,或变量比较多时,需要用变量标签对变量名的含义加以解释。
在统计分析过程的输出中会在与变量名相对应的位置显示该变量的标签,有助于分析输出结果得出结论。
如果SPSS是运行在中文环境下,不熟悉英文的用户也可以给变量名附加中文标签。
d数据录入方法:
定义了变量就可以开始输入数据了。
输入数据的操作方法是多种多样的,可以定义了一个变量就先输入这一个变量的值(纵向进行),也可以定义完所有变量后,按观测量来输入(横向进行),即输入完一个观测量的各变量值,再输入第二个观测量的各个变量的值。
数据编辑器的二维表格中顶部标有定义的变量名,左侧标有观测量序号。
一个变量名和一个观测量序号就指定了唯一的一个单元格。
图4-1.variableview
图4-2.Variabletype
图4-3.DataView
4-1.2操作提示:
1.单击Analyze--DescriptiveStatistics--Frequencies,见图4-4;
2.选择频数分组变量,见图4-5;
3.Statistics…--选择相应的基本统计量--Continue,见图4-6;
4.Charts…--Histogrames--WithNormalCurve--Continue,图4-7。
5.单击OK,完成统计分析。
图4-4.Frequencies…
图4-5Frequencies
图4-6Frequencies_Statistics
图4-7Frequencies_Charts
图4-8Statistics_output
图4-9频数分布表
图4-10频数分布图
4-1.3结果分析:
1如图4-8Statistics为计算的统计量表,包括四分位数(Quartiles)、均数(Mean)、中位数(Median)、众数(Mode)、标准差(Std.deviation)、方差(Variance)、全距(Range)、最小值(Minimum)、最大值(Maximum)、标准误(S.E.mean);
例4-2(7-2)现有10名女大学生的口腔温度(℃)分别为:
37.7,36.8,36.8,37.0,37.1,37.2,37.1,37.0,36.9,37.3,求其平均温度。
图4-11Frepuencies
图4-12Frepuencies_StatisticsandOutput
例4-335名麻疹易感儿童接种麻疹疫苗一个月后,血凝抑制抗体滴度见表4-2,求其平均滴度。
表4-235名麻疹易感儿童接种麻疹疫苗一个月后血凝抑制抗体滴度
抗体滴度
1:
4
1:
8
1:
16
1:
32
1:
64
1:
128
1:
256
1:
512
合计
人数(f)
1
4
5
4
6
9
4
2
35
图4-13例7-4Compute
图4-13ComputeVariable
图4-14Descriptives…
图4-15例DescriptivesOptionsandOutput
例4-4某传染病患者10例,他们的潜伏期分别为:
4,4,5,5,6,7,7,9,12,20天,求中位数。
图4-16Frequencies…
图4-17FrequenciesStatisticsandOutput
例4-5现有139例食物中毒病人,其潜伏期分布如表4-3(7-4),求其中位数。
表4-3(7-4)139例食物中毒病人潜伏期分布情况
潜伏期
0~
6~
12~
18~
24~
30~
36~
42~
合计
组中值
3
9
15
21
27
33
39
45
---
频数
15
49
35
30
5
4
0
1
139
图4-18定义变量
图4-19WeightCases…
图4-20Frequencies…
图4-21Frequencies
图4-22Statistics
图4-23Output
实验三数值变量资料的统计分析
二、实验内容
1、资料的分析及数据的录入;
2、样本均数与已知总体均数的t检验
3、配对资料的t检验;
4、两样本均数的t检验;
三、实验要求
通过上机演示,熟悉利用SPSS统计软件进行两均数假设检验的方法;通过对给出资料的上机实际操作掌握数据库的建立方法,掌握配对资料t检验和两个样本均数t检验的方法;熟悉样本均数与总体均数t检验的方法。
四、实验资料
(一)样本均数与总体均数的比较
例5-1正常人的脉搏平均为72次/分,现某护士测得10例某病患者的脉搏(次/分)分别为:
54、67、68、78、70、66、67、70、65、69。
试问此病患者的脉搏与正常人有否显著性差异?
5-1.1准备数据:
激活变量窗口,定义变量名:
脉搏,数据输入后结果如图5-1所示。
5-1.2操作提示:
1单击Analyze菜单选CompareMeans中的One-sampleTTest...项(如图5-1示);
2弹出One-sampleTTest对话框(如图5-2示)。
从对话框左侧的变量列表中选择变量脉搏,点击钮使变量脉搏进入TestVariables框;在检验值(Testvalue)框内输入72;
3点击OK按钮即完成分析。
图5-1One-SampleTTest…
图5-2One-SampleTTest
图5-3One-SampleStatisticsandoutput
5-1.3结果分析
结果显示(如图5-3)变量脉搏的样本例数、均数、标准差、标准误分别为10、67.40、5.929、1.875。
检验结果为:
t=2.453(注意:
在报告结果时,不应有负号,应取绝对值),P=0.037,按α=0.05的检验水准,差异有统计意义,即根据本资料可以认为该病患者的脉搏数与一般人不同,该病患者的脉搏数较低。
另外从可信区间(95%Cl)(-8.84,-0.36)也可以得出相同结论。
(二)配对数值变量资料的比较
例5-2手术前后舒张压变化情况
表5-1手术前后舒张压变化情况
患者编号
舒张压((kPa)
手术前
手术后
1
16.0
12.0
2
12.0
13.3
3
14.6
10.6
4
13.3
12.0
5
12.0
12.0
6
12.0
10.6
7
14.6
10.6
8
14.6
14.6
9
12.0
12.7
10
12.3
13.3
图5-4Paired-SamplesTTes…
图5-5Paired-SamplesTTest
图5-6Paired-SamplesTTestOutput
5-2.3结果分析
图5-6结果显示手术前和手术后两个变量两两相减的差值均数、标准差、标准误、95%可信区间(95%CI)分别为1.17、2.14、0.68,95%可信区间(95%Cl)为-0.36,2.70。
配对检验结果为:
t=1.730,P=0.118,按α=0.05的检验水准,差异无统计意义,即还不能认为手术前后的舒张压不同。
(三)两样本均数的比较
例5-3患者
:
0.841.051.201.201.391.531.671.801.872.072.11
健康人
:
0.540.640.640.750.760.811.161.201.341.351.481.561.87
问该地急性克山病患者与健康人的血磷值(mmol/l)是否不同?
5-3.1准备数据:
激活变量管理窗口(VariableView),定义变量名:
把实际观察值定义为血磷值,再定义一个组别变量来区分患者与健康人(患者=1,健康人=2),方法如下:
可在组别变量中的Value框内点击,在ValueLabels框中的Value处指定变量值,在ValueLabel处输入变量值标签,点击Add钮表示加入这种标签定义,点击Change表示更改原有标签,用户重新定义,点击Remove钮表示取消原有标签。
如:
定义组别变量过程中,数值1表示患者;数值2表示健康人。
则先在Value框中输入“1”,把插入点光标移至ValueLabel框(或按Tab键)中输入“男”,按Add按钮,列表框中增加了一个值标签,显示1=“患者”。
然后,再在Value框中输入“2”,把插入点光标移至ValueLabel框(或按Tab键)中,输入“健康人”,按Add按钮,清单中显示2=“健康人”。
至此,值标签定义完毕。
激活数据管理窗口(Dataview),输入相应数据。
图5-7定义变量及变量值
图5-8Independent-SamplesTTest…
图5-9Independent-SamplesTTestandDefineGroups
图5-10Independent-SamplesTTestOutput
5-3.3结果分析:
结果显示(如图5-10)t检验的结果,第一行表示方差齐情况下的t检验的结果,第二行表示方差不齐情况下的t检验的结果。
依次显示值(t-value)、自由度(df)、双侧检验概率(2-TailSig)、差值的标准误(SEofDifference)及其95%可信区间(CIforDifference)。
因本例方差齐性检验的F值为0.032,P=0.860,属方差齐性,故采用第一行(即Equal)结果:
t=2.524,P=0.019,按α=0.05的检验水准,差异有统计学意义,可认为急性克山病患者与健康人的血磷值不同,患者的血磷值较高。
实验四分类变量的统计分析
一、实验目的
掌握四格表资料、配对资料、行×列表资料的卡方检验的方法。
三、实验要求
通过上机演示,熟悉利用SPSS统计软件进行分类变量的统计分析的方法;通过对给出资料的上机实际操作掌握数据库的建立方法,掌握卡方检验的方法。
例6-1用卡方检验法比较吸烟者与不吸烟者的慢性支气管炎患病率有无差别
表6-1吸烟者与不吸烟者的慢性支气管炎患病率比较
分组
患病人数
未患病人数
合计
患病率(%)
吸烟者
43(a)
162(b)
205(a+b)
21.0
不吸烟者
13(c)
121(d)
134(c+d)
9.7
合计
56(a+c)
283(b+d)
339(n)
16.5
6-1.1准备数据:
单击变量窗口,定义三个变量:
分组变量(吸烟者=1,不吸烟者=2)为r、结果(患病=1,未患病=2)为c和频数变量f,按顺序输入数据(如图6-1)。
图6-1定义变量及变量值
2单击Analyze菜单选DescriptiveStatistics中的Crosstabs...项,
其中Chi-square即为χ2检验。
由于在实际研究中,变量间的依赖强度和特征也是需要考虑的,χ2值不是列联强度的好的度量,故用户可根据实际需要选择其他相关的指标:
(1)定距变量的关联指标
Correlations:
可作列联表行、列两变量的Pearson相关系数或作伴随组秩次的Spearman相关系数。
(2)定类变量的关联指标
Contingencycoefficient:
列联系数,其值界于0~1之间,其中N为总例数;
PhiandCramer'sV:
ψ系数用于描述相关程度,在四格表χ2检验中界于-1~1之间,在RC表χ2检验中界于0~1之间;Cramer'sV界于0~1之间,其中k为行数和列数较小的实际数;
Lambda:
λ值,在自变量预测中用于反映比例缩减误差,其值为1时表明自变量预测应变量好,为0时表明自变量预测应变量差;
Uncertaintycoefficient:
不确定系数,以商为标准的比例缩减误差,其值接近1时表明后一变量的信息很大程度来自前一变量,其值接近0时表明后一变量的信息与前一变量无
3单击Cells...钮,弹出Crosstabs:
Cells对话框(图6-5),用于定义列联表单元格中需要计算和显示的指标。
Observed为实际观察数,Expected为理论数,Row为行百分数,Column为列百分数,Total为合计百分数,Unstandardized为实际数与理论数的差值,Standardized为实际数与理论数的差值除理论数,Adj.Standardized为由标准误确立的单元格残差。
选择后点击Continue钮返回Crosstabs对话框;
图6-2WeightCases
图6-3定义行列变量
图6-4Statistics
图6-5CellDisplay
图6-6Output_1
图6-7Output_2
6-1.3结果分析
在结果输出窗中,系统先输出四格表资料,包括实际观察数、理论数、行百分数、列百分数和合计百分数(如图6-6)。
接着输出有关统计数据(如图6-7),因n=339,最小理论数为22.14,故采用Pearsonχ2值=7.469,双侧P值为0.006,按α=0.05的检验水准,差异有统计学意义,可认为吸烟者与不吸烟者慢性气管炎患病率是不同的,吸烟者慢性气管炎患病率高于不吸烟者。
注:
(1)当n≥40,且任一格的理论数T≥5,采用Pearsonχ2检验;
(2)当n≥40,且任一格的理论数T5>T≥1,采用连续性校正χ2检验;
(3)当n<40,或任一格的理论数T≤1时,采用Fisher精确概率检验。
例6-2甲乙两种白喉杆菌培养基的培养效果有无差别
表6-2甲乙两种白喉杆菌培养基的培养结果
甲培养基
乙培养基
合计
+
-
+
11(a)
9(b)
20
-
1(c)
7(d)
8
合计
12
16
28
6-2.1准备数据:
单击变量窗口,定义三个变量:
甲培养基(+=1,-=2)为r、乙培养基(+=1,-=2)为c和频数变量f,按顺序输入数据(如图6-8)。
图6-8定义变量及变量值
6-2.2操作提示:
1单击Data菜单选WeightCases...命令项,弹出WeightCases对话框(如图6-9,6-10),选频数(f)点击钮使之进入FrequencyVariable框,定义频数(f)为权数,再点击OK钮即可;
2单击Analyze菜单选DescriptiveStatistics中的Crosstabs...项(如图6-11所示),弹出Crosstabs对话框(如图6-12所示)。
在Crosstabs对话框中,选甲培养基(r)点击钮使之进入Row(s)框,选乙培养基(c)点击钮使之进入Column(s)框。
点击Statistics...钮,弹出Crosstabs:
Statistics对话框(图6-13),选择Chi-square为χ2检验和McNeman(配对卡方检验统计量)两项。
3单击Cells...钮,弹出Crosstabs:
Cells对话框(图6-14),用于定义列联表单元格中需要计算和显示的指标。
选择实际观察数(Observed),理论数(Expected)后,点击Continue钮返回Crosstabs对话框;
4点击OK钮即可。
图6-9WeightCases…
图6-10WeightCases
图6-11Crosstabs…
图6-12Crosstabs
图6-13Statistics
图6-14CellDisplay
图6-15Output_1
图6-16Output_2
6-2.3结果分析
在结果输出窗中,系统先输出四格表资料,包括实际观察数、理论数、行百分数、列百分数和合计百分数(如图6-15)。
接着输出有关统计数据(如图6-16),因本例为配对设计,故采用McNeman检验,其双侧P值为0.021(因本例样本量较小,是采用二项分布直接计算的概率;如果样本量较大,则会给出McNeman检验的统计量和概率),按α=0.05的检验水准,差异有统计学意义,可认为甲、乙两种白喉杆菌培养基的培养效果不同,根据两培养基的阳性数可得出甲培养基阳性率较高。
例6-3某市三个地区出生婴儿的致畸率有无差别
表6-3某市三个地区出生婴儿的致畸率比较
地区
畸形数
无畸形数
合计
致畸率(%)
重污染区
114
3278
3392
33.61
一般市区
404
40143
40547
9.96
农村
67
8275
8342
8.03
合计
585
51696
52281
11.19
6-3.1准备数据:
单击变量窗口,定义三个变量:
地区(重污染区=1,一般市区=2,农村=3)为r、畸形情况(畸形=1,无畸形=2)为c和频数变量f,按顺序输入数据(如图6-17)。
图6-17定义变量及变量值
6-3.2操作提示:
1单击Data菜单选WeightCases...命令项,弹出WeightCases对话框(如图6-18),选频数(f)点击钮使之进入FrequencyVariable框,定义频数(f)为权数,再点击OK钮即可;
2单击Analyze菜单选DescriptiveStatistics中的Crosstabs...项(如图6-19所示),弹出Crosstabs对话框。
在Crosstabs对话框中,选地区(r)点击钮使之进入Row(s)框,选畸形情况(c)点击钮使之进入Column(s)框。
点击Statistics...钮,弹出Crosstabs:
Statistics对话框(图6-20),选择Chi-square检验。
3单击Cells...钮,弹出Crosstabs:
Cells对话框(图6-21),用于定义列联表单元格中需要计算和显示的指标。
选择实际观察数(Observed),理论数(Expected)后,点击Continue钮返回Crosstabs对话框;
4点击OK钮即可。
图6-18WeightCases…
图6-19Crosstabs…
图6-20Statistics
图6-21CellDisplay
图6-22Output
6-3.3结果分析
在结果输出窗中,系统先输出四格表资料,包括实际观察数、理论数、行百分数、列百分数和合计百分数(如图6-22)。
接着输出有关统计数据,因没有一个格子的理论数小于5,最小理论数为37.95,故采用Pearsonχ2值=167.11,双侧P值<0.001,按α=0.05的检验水准,差异有统计学意义,可认为三个地区出生婴儿的致畸率有差别。
若要比较彼此间的差别,需做多重比较。
例6-4急性与慢性白血病患者血型构成比是否相同
表6-4急性与慢性白血病患者血型构成
组别
血型
合计
A型
B型
O型
AB型
急性组
58
49
59
18
184
慢性组
43
27
33
8
 升级会员
升级会员 