第八讲 定点运算器的组成和结构.docx
《第八讲 定点运算器的组成和结构.docx》由会员分享,可在线阅读,更多相关《第八讲 定点运算器的组成和结构.docx(13页珍藏版)》请在冰豆网上搜索。
第八讲定点运算器的组成和结构
第八讲、定点运算器的组成和结构
1.算术逻辑单元(简称ALU)
• 针对每一种算术运算,都必须有一个相对应的基本硬件配置,其核心部件是加法器和寄存器。
当需完成逻辑运算时,势必需要配置相应的逻辑电路,而ALU电路是既能完成算术运算又能完成逻辑运算的部件。
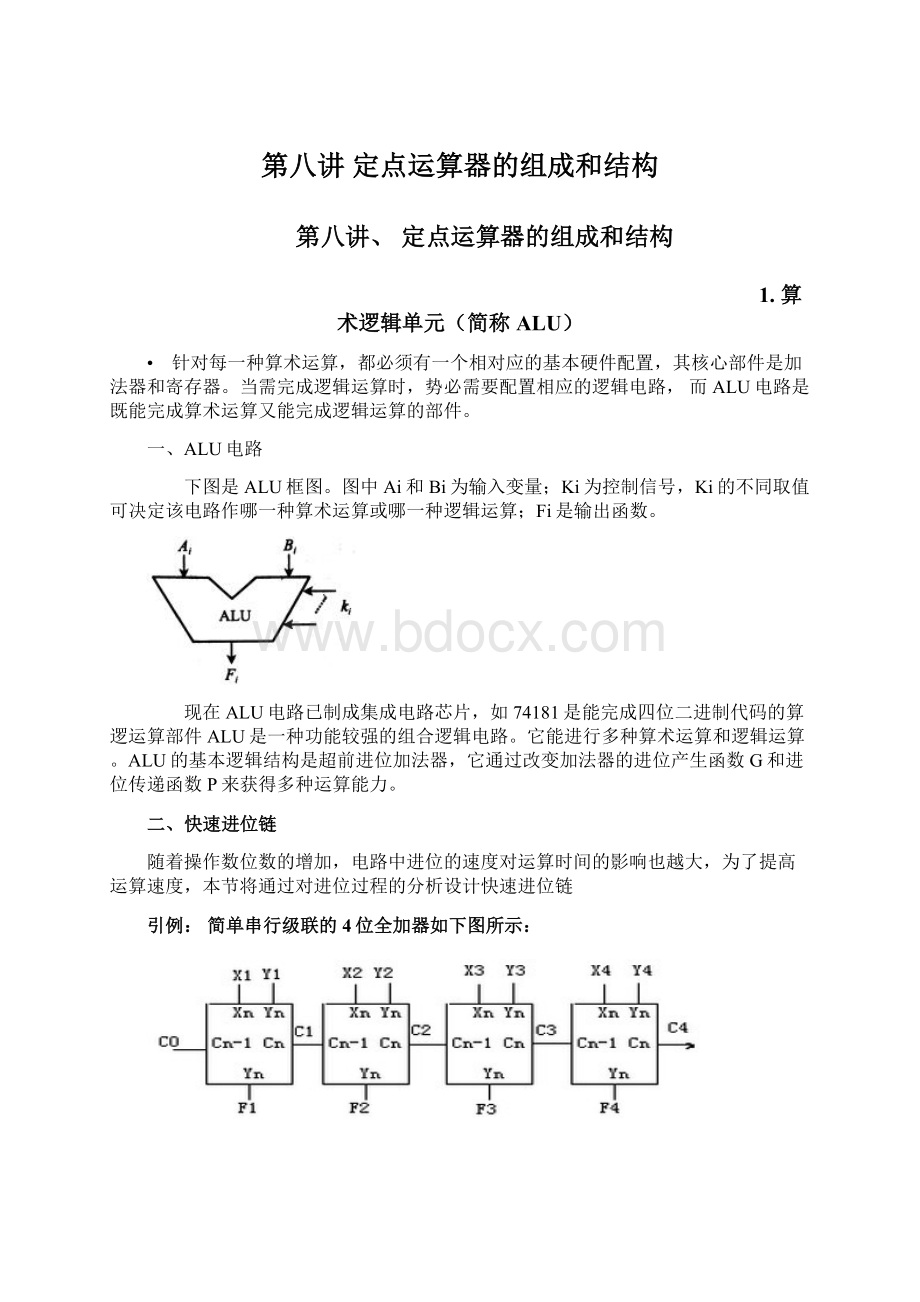
一、ALU电路
下图是ALU框图。
图中Ai和Bi为输入变量;Ki为控制信号,Ki的不同取值可决定该电路作哪一种算术运算或哪一种逻辑运算;Fi是输出函数。
现在ALU电路已制成集成电路芯片,如74181是能完成四位二进制代码的算逻运算部件ALU是一种功能较强的组合逻辑电路。
它能进行多种算术运算和逻辑运算。
ALU的基本逻辑结构是超前进位加法器,它通过改变加法器的进位产生函数G和进位传递函数P来获得多种运算能力。
二、快速进位链
随着操作数位数的增加,电路中进位的速度对运算时间的影响也越大,为了提高运算速度,本节将通过对进位过程的分析设计快速进位链
引例:
简单串行级联的4位全加器如下图所示:
将4个全加器相连可得4位加法器(图2.7),但其加法时间长。
这是因为其位间进位是串行传送的。
本位全加和Fi必须等低位进位Ci-1来到后才能进行,加法时间与位数有关。
只有改变进位逐位传送的路径,才能提高加法器工作速度。
解决办法之一是采用“超前进位产生电路”来同时形成各位进位,从而实行快速加法。
我们称这种加法器为超前进位加法器。
根据各位进位的形成条件,可分别写出Ci的逻辑表达式:
C1=X1Y1+(X1+Y1)C0=G1+P1C0
其中:
Gi=Xi·Yi称为进位产生函数
Pi=Xi+Yi称为进位传递函数
Gi的意义是:
当XiYi均为“1”时定会产生向高位的进位
Pi的意义是:
当Xi和Yi中有一个为“1”时,若同时低位有进位输入,则本位也将向高位传送进位。
写成通用式为:
C1=G1+P1C0
C2=G2+P2C1=G2+P2(G1+P1C0)=G2+P2G1+P2P1C0
C3=G3+P3G2+P3P2G1+P3P2P1C0
C4=G4+P4G3+P4P3G2+P4P3P2G1+P4P3P2P1C0
当全加器的输入均取反码时,它的输出也均取反码。
(应用反演律采用与非、或非、与或非表示)将上式改写成如下:
根据上式可画得“超前进位产生电路”及四位超前进位加法器的逻辑图如下图2.8。
基本思想----------由全加器扩展开来:
Fi=Ai⊕Bi⊕Ci
Ci+1=AiBi+BiCi+CiAi
加入控制参数s0~s3,对输入
进行控制.此时全加器的输
入变为Xi,Yi
一位全加器(FA)的逻辑表达式为
1.逻辑表达式
下图为控制参数s0~s3与输入量的关系:
S0S1YiS2S3Xi
00~Ai001
01~AiBi01~Ai+~Bi
10~Ai~Bi10~Ai+Bi
11011~Ai
由上表,可得Xi,Yi的逻辑表达式(化简后为)
Xi=S3AiBi+S2AiBi
Yi=Ai+S0Bi+S1Bi
故:
XiYi=Yi
代入进位表达式,简化为:
Cn+i+1=Yi+XiCn+i
综上所述:
ALU的某一位逻辑表达式可写为:
Xi=S3AiBi+S2AiBi
Yi=Ai+S0Bi+S1Bi
Fi=Yi⊕Xi⊕Cn+I
Cn+i+1=Yi+XiCn+I
4位之间采用先行进位,则由上式,每一位的进位公式可递推如下:
第0位向第一位的进位:
Cn+1=Y0+X0Cn
第1位向第2位的进位:
Cn+2=Y1+X1Cn+1=Y1+Y0X1+X0X1Cn
第2位向第3位的进位:
Cn+3=Y2+X2Cn+2
=Y2+Y1X1+Y0X1X2+X0X1X2Cn
第3位向第4位的进位:
Cn+4=Y3+Y2X3+Y1X2X3+Y0X1X2X3+X0X1X2X3Cn
设:
G=Y3+Y2X3+Y1X2X3+Y0X1X2X3
P=X0X1X2X3
故:
Cn+4=G+PCn
这样,对一片ALU来说,可有三个进位输也,其中,G称为进位发生输出,P称为进位传送输出.在电路中多加这两个进位输出的目的是为了便于实现多片ALU之间的先行进位.(第0位的进位输入Cn可以直接传到最高位上去,从而实高速运算).
下面通过介绍SN74181型四位ALU中规模集成电路了介绍ALU的原理。
•它能执行16种算术运算和16种逻辑运算,M是状态控制端,M=H,执行逻辑运算;M=L执行算术运算。
S0~S3是运算选择端,它决定电路执行哪种算术运算或逻辑运算。
以正逻辑为例,B3~B0和A3~A0是两个操作数,F3~F0为输出结果。
C-l表示最低位的外来进位,Cn+4是7418l向高位的进位;P、G可供先行进位使用。
M用于区别算术运算还是逻辑运算;S3~S0的不同取值可实现不同的运算。
例如,当M=1,S3~S0=0110时,74181作逻辑运算A⊕B;当M=0,S3~S0=0110时,74181作算术运算。
由上表可见,在正逻辑条件下,M=0,S3~S0=0110,且C-l=1时,完成A减B减1的操作。
若想完成A减B运算,可使C-l=0。
需注意,74181算术运算是用补码实现的,其中减数的反码是由内部电路形成的,而末位加“1”,则通过C-l=0来体现。
尤其要注意的是,ALU为组合逻辑电路,因此实际应用ALU时,其输入端口A和B必须与锁存器相连,而且在运算的过程中锁存器的内容是不变的。
其输出也必须送至寄存器中保存。
其引脚图如下:
74181ALU设置了P和G两个本组先行进位输出端,如果将四片74181的P,G端送到74181先行进位部件CLA,又可实现第二级的先行进,即组与组间的先行进位.
假设4片74181的先行进位输出依次为P0,G0,P1,G1,P2,G2,P3,G3,那么先行进位部件74182CLA所提供的进位逻辑关系如下:
Cn+1=G0+P0Cn
Cn+2=G1+P1Cn+1=G1+G0P1+P0P1Cn
Cn+3=G2+P2Cn+2=G2+G1P2+G0P1P2+P0P1P2Cn
Cn+4=G3+P3Cn+3=G3+G2P3+G1P1P2+G0P1P2P3+P0P1P2P3Cn
其中:
P*=P0P1P2P3
G*=G3+G2P3+G1P1P2+G0P1P2P3
由上述表达式,用TTL器件实现的成组先行进位部件74182的逻辑电路图如下:
下面介绍如何用若干74181ALU位片,与74182先行进位部件CLA一起构与一个全字长(16位)的ALU:
用两个16位全先行进位部件(74182)和八个74181可级连组成的32位ALU电路
用四个16位全先行进位部件(74182)和十六个74181可级连组成的64位ALU电路
由于集成器件的集成度的提高,允许更多位的ALU集成在一个芯片内。
例如AMD公司的AM29332为32位ALU,而在Intel公司的Pentium处理器中,32位ALU仅是芯片内的一部分电路。
尽管器件不同,但基本电路原理还是相似的。
2、定点运算器的基本结构
内部总线------CPU内部各部件间的连线
外部总线------即系统总线,CPU与存储器,I/O系统之间的连线.
运算器:
包括ALU,阵列乘法器,寄存器,多路开关,三态缓冲器,数据总线等逻辑部件.
计算机的运算器大体有以下三种结构:
单总线结构
比较:
双总线结构
三总线结构
3、算术逻辑单元(补充)
快速进位链
1.并行加法器
并行加法器由若干个全加器组成,如下图所示。
n+1个全加器级联,就组成了一个n+1位的并行加法器。
由于每位全加器的进位输出是高一位全加器的进位输入,因此当全加器有进位时,这种一级一级传递进位的过程,将会大大影响运算速度。
由全加器的逻辑表达式可知:
和
进位
可见,Ci进位有两部分组成:
本地进位AiBi,可记作di,与低位无关;传递进位,与低位有关;可称为传递条件,记作ti则:
由Ci的组成可以将逐级传递进位的结构,转换为以进位链的方式实现快速进位。
目前进位链通常采用串行和并行两种。
2.串行进位链
串行进位链是指并行加法器中的进位信号采用串行传递。
以四位并行加法器为例,每一位的进位表达式可示为:
由上式可见,采用与非逻辑电路可方便地实现进位传递,如下图所示。
若设与非门的级延迟时间为ty,那么当di、ti形成后,共需8ty使可产生最高位的进位。
实际上每增加一位全加器,进位时间就会增加2ty。
n位全加器的最长进位时间为2nty。
3.并行进位链
并行进位链是指并行加法器中的进位信号是同时产生的,又称先行进位、跳跃进位等。
理想的并行进位链是n位全加器的n位进位同时产生,但实际实现有困难;通常并行进位链有单重分组和双重分组两种实现方案。
(1)单重分组跳跃进位。
单重分组跳跃进位就是将M位全加器分成若干小组,小组内的进位同时产生,小组与小组之间采用串行进位,这种进位又有组内并行、组间串行之称。
以四位并行加法器为例,对其进位表示式稍作变换,便可获得并行进位表达式:
可得与其对应的逻辑图。
如下图所示。
设与或非门的级延迟时间为1.5ty,如与非门的级延迟时间仍为1ty,则di、ti形成后,只需2.5ty就可产生全部进位。
如果将16位的全加器按四位一组分组,便可得单重分组跳跃进位链框图,如下图所示。
不难理解在di、ti形成后,经2.5ty可产生C3、C2、C3、C3四个进位信息,经10ty就可产生全部进位,而n=16的串行进位链的全部进位时间为32ty,可见单重分组方案进位时间仅为串行进位链的三分之一。
但随着n的增大,其优势便很快减弱,如当n=64时,按4位分组,共为16组,组间有16位串行进位,在di、ti形成后,还需经40ty才能产生全部进位,显然进位时间太长。
如果能使组间进位也同时产生,必然会更大地提高进位速度,这就是组内、组间均为并行进位的方案。
(2)双重分组跳跃进位。
双重分组跳跃进位就是将n位全加器分成几个大组,每个大组又包含几个小组,而每个大组内所包含的各个小组的最高位进位是同时形成的,大组与大组间采用串行进位。
因各小组最高位进位是同时形成的,小组内的其他进位也是同时形成的(注意两小组内的其他进位与小组的最高位进位并不是同时产生的),故又有组(小组)内并行、组(小组)间并行之称。
下图是一个32位并行加法器双重分组跳跃进位链的框图。
图中共分两大组,每个大组内包含4个小组,第一大组内的4个小组的最高位进位C31、C27、C23、C19是同时产生的;第二大组内4个小组的最高位进位C15、C11、C7、C3也是同时产生的,而第二大组向第一大组的进位C15采用串行进位方式。
以第二大组为例,分析各进位的逻辑关系。
例写出第八小组的最高位进位表达式:
式中仅与本小组内的di、ti有关,不依赖外来进C-l,故称D8为第八小组的本地进位:
是将低位进位C-1传到高位小组的条件,故称T8为第八小组的传送条件。
同理可写出第五、六、七小组的最高位进位表达式:
第七小组
第六小组
第五小组
进一步展开又得:
可得大组跳跃进位链,如下图所示。
由图可见,当Di、Ti(i=5~8)及外来进位C-1形成后,再经过2.5t
 升级会员
升级会员 