spss数据正态分布检验方法及意义.docx
《spss数据正态分布检验方法及意义.docx》由会员分享,可在线阅读,更多相关《spss数据正态分布检验方法及意义.docx(31页珍藏版)》请在冰豆网上搜索。
spss数据正态分布检验方法及意义
spss数据正态分布检验方法及意义判读
要观察某一属性的一组数据是否符合正态分布,可以有两种方法(目前我知道这两种,并且这两种方法只是直观观察,不是定量的正态分布检验):
1:
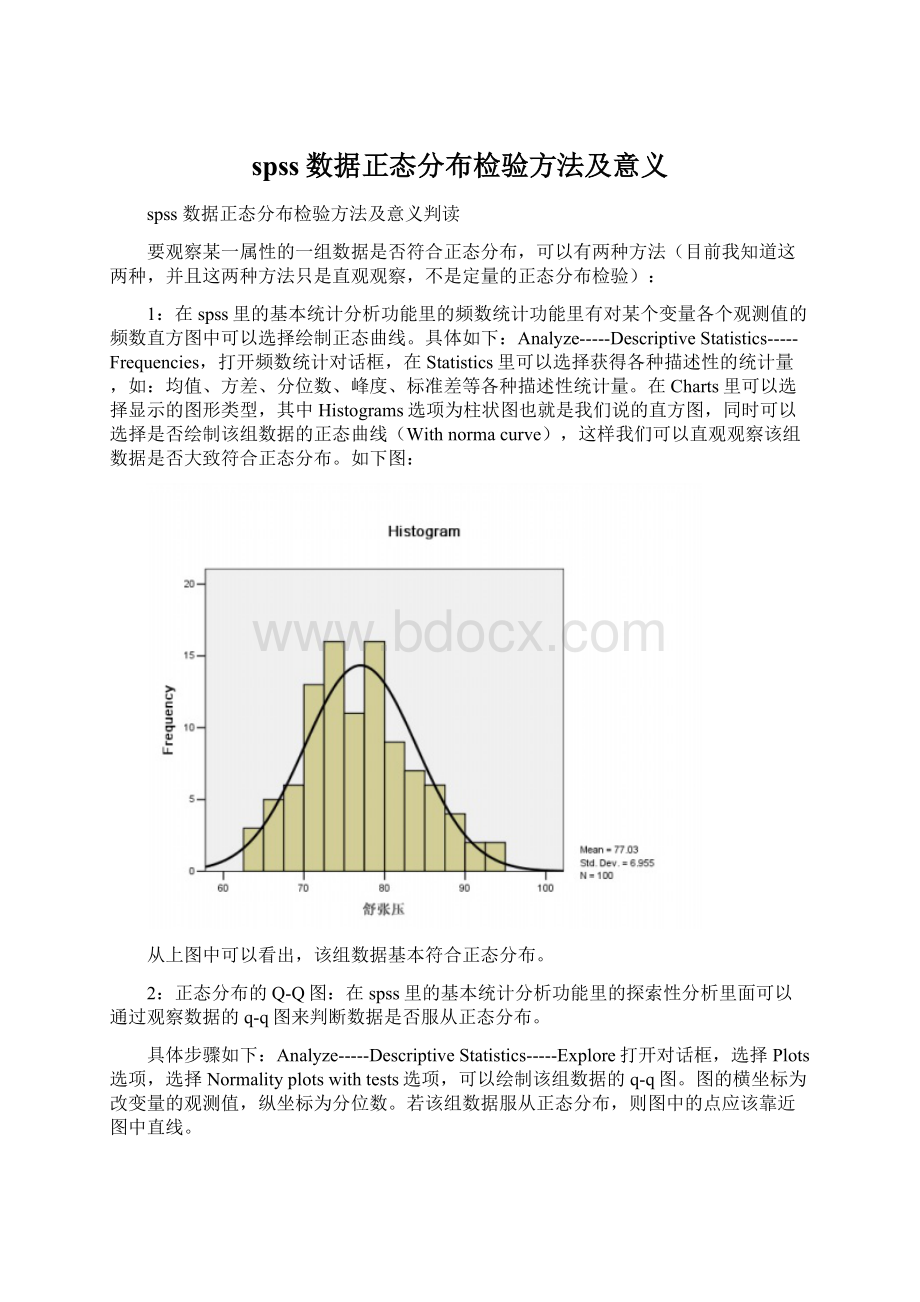
在spss里的基本统计分析功能里的频数统计功能里有对某个变量各个观测值的频数直方图中可以选择绘制正态曲线。
具体如下:
Analyze-----DescriptiveStatistics-----Frequencies,打开频数统计对话框,在Statistics里可以选择获得各种描述性的统计量,如:
均值、方差、分位数、峰度、标准差等各种描述性统计量。
在Charts里可以选择显示的图形类型,其中Histograms选项为柱状图也就是我们说的直方图,同时可以选择是否绘制该组数据的正态曲线(Withnormacurve),这样我们可以直观观察该组数据是否大致符合正态分布。
如下图:
从上图中可以看出,该组数据基本符合正态分布。
2:
正态分布的Q-Q图:
在spss里的基本统计分析功能里的探索性分析里面可以通过观察数据的q-q图来判断数据是否服从正态分布。
具体步骤如下:
Analyze-----DescriptiveStatistics-----Explore打开对话框,选择Plots选项,选择Normalityplotswithtests选项,可以绘制该组数据的q-q图。
图的横坐标为改变量的观测值,纵坐标为分位数。
若该组数据服从正态分布,则图中的点应该靠近图中直线。
纵坐标为分位数,是根据分布函数公式F(x)=i/n+1得出的.i为把一组数从小到大排序后第i个数据的位置,n为样本容量。
若该数组服从正态分布则其q-q图应该与理论的q-q图(也就是图中的直线)基本符合。
对于理论的标准正态分布,其q-q图为y=x直线。
非标准正态分布的斜率为样本标准差,截距为样本均值。
如下图:
如何在spss中进行正态分布检验1(转)(2009-07-2211:
11:
57)
标签:
杂谈
一、图示法
1、P-P图
以样本的累计频率作为横坐标,以安装正态分布计算的相应累计概率作为纵坐标,把样本值表现为直角坐标系中的散点。
如果资料服从整体分布,则样本点应围绕第一象限的对角线分布。
2、Q-Q图
以样本的分位数作为横坐标,以按照正态分布计算的相应分位点作为纵坐标,把样本表现为指教坐标系的散点。
如果资料服从正态分布,则样本点应该呈一条围绕第一象限对角线的直线。
以上两种方法以Q-Q图为佳,效率较高。
3、直方图
判断方法:
是否以钟形分布,同时可以选择输出正态性曲线。
4、箱式图
判断方法:
观测离群值和中位数。
5、茎叶图
类似与直方图,但实质不同。
二、计算法
1、偏度系数(Skewness)和峰度系数(Kurtosis)
计算公式:
g1表示偏度,g2表示峰度,通过计算g1和g2及其标准误σg1及σg2然后作U检验。
两种检验同时得出U0.05的结论时,才可以认为该组资料服从正态分布。
由公式可见,部分文献中所说的“偏度和峰度都接近0……可以认为……近似服从正态分布”并不严谨。
2、非参数检验方法
非参数检验方法包括Kolmogorov-Smirnov检验(D检验)和Shapiro-Wilk(W检验)。
SAS中规定:
当样本含量n≤2000时,结果以Shapiro–Wilk(W检验)为准,当样本含量n>2000时,结果以Kolmogorov–Smirnov(D检验)为准。
SPSS中则这样规定:
(1)如果指定的是非整数权重,则在加权样本大小位于3和50之间时,计算Shapiro-Wilk统计量。
对于无权重或整数权重,在加权样本大小位于3和5000之间时,计算该统计量。
由此可见,部分SPSS教材里面关于“Shapiro–Wilk适用于样本量3-50之间的数据”的说法是在是理解片面,误人子弟。
(2)单样本Kolmogorov-Smirnov检验可用于检验变量(例如income)是否为正态分布。
对于此两种检验,如果P值大于0.05,表明资料服从正态分布。
三、SPSS操作示例
SPSS中有很多操作可以进行正态检验,在此只介绍最主要和最全面最方便的操作:
1、工具栏--分析—描述性统计—探索性
2、选择要分析的变量,选入因变量框内,然后点选图表,设置输出茎叶图和直方图,选择输出正态性检验图表,注意显示(Display)要选择双项(Both)。
3、Output结果
(1)Descriptives:
描述中有峰度系数和偏度系数,根据上述判断标准,数据不符合正态分布。
Sk=0,Ku=0时,分布呈正态,Sk>0时,分布呈正偏态,Sk<0时,分布呈负偏态,时,Ku>0曲线比较陡峭,Ku<0时曲线比较平坦。
由此可判断本数据分布为正偏态(朝左偏),较陡峭。
(2)TestsofNormality:
D检验和W检验均显示数据不服从正态分布,当然在此,数据样本量为1000,应以W检验为准。
(3)直方图
直方图验证了上述检验结果。
(4)此外还有茎叶图、P-P图、Q-Q图、箱式图等输出结果,不再赘述。
结果同样验证数据不符合正态分布。
spss 判断两组数据的相关性(已使用)(2009-07-2213:
07:
34)
标签:
杂谈
两组体重数据:
先要为数据分组
2.0 3000.0
2.0 3700.0
2.0 2900.0
2.0 3200.0
2.0 2950.0
2.0 3100.0
2.0 700.0
2.0 3200.0
2.0 2500.0
2.0 3650.0
2.0 3450.0
2.0 4600.0
2.0 2700.0
2.0 2500.0
2.0 3150.0
2.0 3500.0
2.0 3800.0
2.0 2800.0
2.0 2400.0
2.0 3600.0
2.0 3200.0
2.0 1770.0
2.0 1450.0
2.0 1700.0
2.0 3250.0
2.0 2700.0
2.0 3000.0
2.0 2250.0
2.0 2150.0
2.0 2450.0
2.0 1600.0
2.0 3100.0
2.0 4050.0
2.0 4250.0
2.0 2900.0
2.0 3250.0
2.0 3750.0
2.0 3500.0
2.0 4100.0
2.0 3100.0
2.0 2400.0
2.0 3250.0
2.0 2600.0
2.0 3100.0
2.0 3400.0
1.0 2400.0
1.0 2100.0
1.0 3000.0
1.0 2600.0
1.0 4000.0
1.0 2200.0
1.0 1400.0
1.0 3000.0
1.0 3200.0
1.0 3600.0
1.0 2850.0
1.0 2850.0
1.0 3300.0
1.0 3500.0
1.0 3900.0
1.0 3250.0
1.0 3800.0
1.0 2800.0
1.0 3500.0
1.0 2650.0
1.0 2350.0
1.0 1400.0
1.0 2900.0
1.0 2550.0
1.0 2850.0
1.0 3300.0
1.0 2250.0
1.0 2500.0
使用命令:
spss的t检验:
菜单Analyze->CompareMeans->Independent-SamplesTTest
运行结果:
经方差齐性检验:
F=0.393 P=0.532,即两方差齐。
(因为p大于0.05)
所以选用t检验的第一行方差齐情况下的t检验的结果:
就是选用方差假设奇的结果
所以,t=0.644 , p=0.522,没有显著性差异。
(因为 p<0.05表示差异有显著性)。
均值相差:
113.30159
解释:
使用comparemeans里的independentsmaplesTtest,检验结果里的Levene\'sTestforEqualityofVariances就是对方差齐性的检验,如果P值大于0.05则认为是方差齐,统计量为F=S1^2/S^2~F(n1-1,n2-1),显著水平一般为0.05,0.01,原假设H0:
方差相等。
方差分析(AnaylsisofVariance,ANOVA)要求各组方差整齐,不过一般认为,如果各组人数相若,就算未能通过方差整齐检验,问题也不大。
One-WayANOVA对话方块中,点击Options…(选项…)按扭,
勾Homogeneity-of-variance即可。
它会产生
Levene、CochranC、Bartlett-BoxF等检验值及其显著性水平P值,
若P值<于0.05,便拒绝方差整齐的假设。
顺带一提,Cochran和Bartlett检定对非正态性相当敏感,
若出现「拒绝方差整齐」的检测结果,或因这原因而做成。
Statistics菜单->CompareMeans->Independent-samplesTTest..
再看看结果中p值的大小是否<.05,若然即达显著水平。
SPSS学习笔记
描述样本数据
一般的,一组数据拿出来,需要先有一个整体认识。
除了我们平时最常用的集中趋势外,还需要一些离散趋势的数据。
这方面EXCEL就能一次性的给全了数据,但对于SPSS,就需要用多个工具了,感觉上表格方面不如EXCEL好用。
个人感觉,通过描述需要了解整体数据的集中趋势和离散趋势,再借用各种图观察数据的分布形态。
对于SPSS提供的OLAPcubes(在线分析处理表),CaseSummary(观察值摘要分析表),Descriptives(描述统计)不太常用,反喜欢用Frequencies(频率分析),BasicTable(基本报表),Crosstabs(列联表)这三个,另外再配合其它图来观察。
这个可以根据个人喜好来选择。
一.使用频率分析(Frequencies)观察数值的分布。
频率分布图与分析数据结合起来,可以更清楚的看到数据分布的整体情况。
以自带文件Trendschapter13.sav为例,选择Analyze->DescriptiveStatistics->Frequencies,把hstarts选入Variables,取消在DisplayFrequencytable前的勾,在Chart里面histogram,在Statistics选项中如图1
图1
分别选好均数(Mean),中位数(Median),众数(Mode),总数(Sum),标准差(Std.deviation),方差(Variance),范围(range),最小值(Minimum),最大值(Maximum),偏度系数(Skewness),峰度系数(Kutosis),按Continue返回,再按OK,出现结果如图2
图2
表中,中位数与平均数接近,与众数相差不大,分布良好。
标准差大,即数据间的变化差异还还小。
峰度和偏度都接近0,则数据基本接近于正态分布。
下面图3的频率分布图就更直观的观察到这样的情况
图3
二.采用各种图直观观察数据分布情况,如采用柱型图观察归类的比例等。
同样以自带文件Trendschapter13.sav为例,我们可以观察一下各年的数据总和的对比:
1.选择Graph->Bar->Simple,在“Datainchartare”一项选择Summar
 升级会员
升级会员 