中北大学 数值分析14实验报告Word文件下载.docx
《中北大学 数值分析14实验报告Word文件下载.docx》由会员分享,可在线阅读,更多相关《中北大学 数值分析14实验报告Word文件下载.docx(18页珍藏版)》请在冰豆网上搜索。
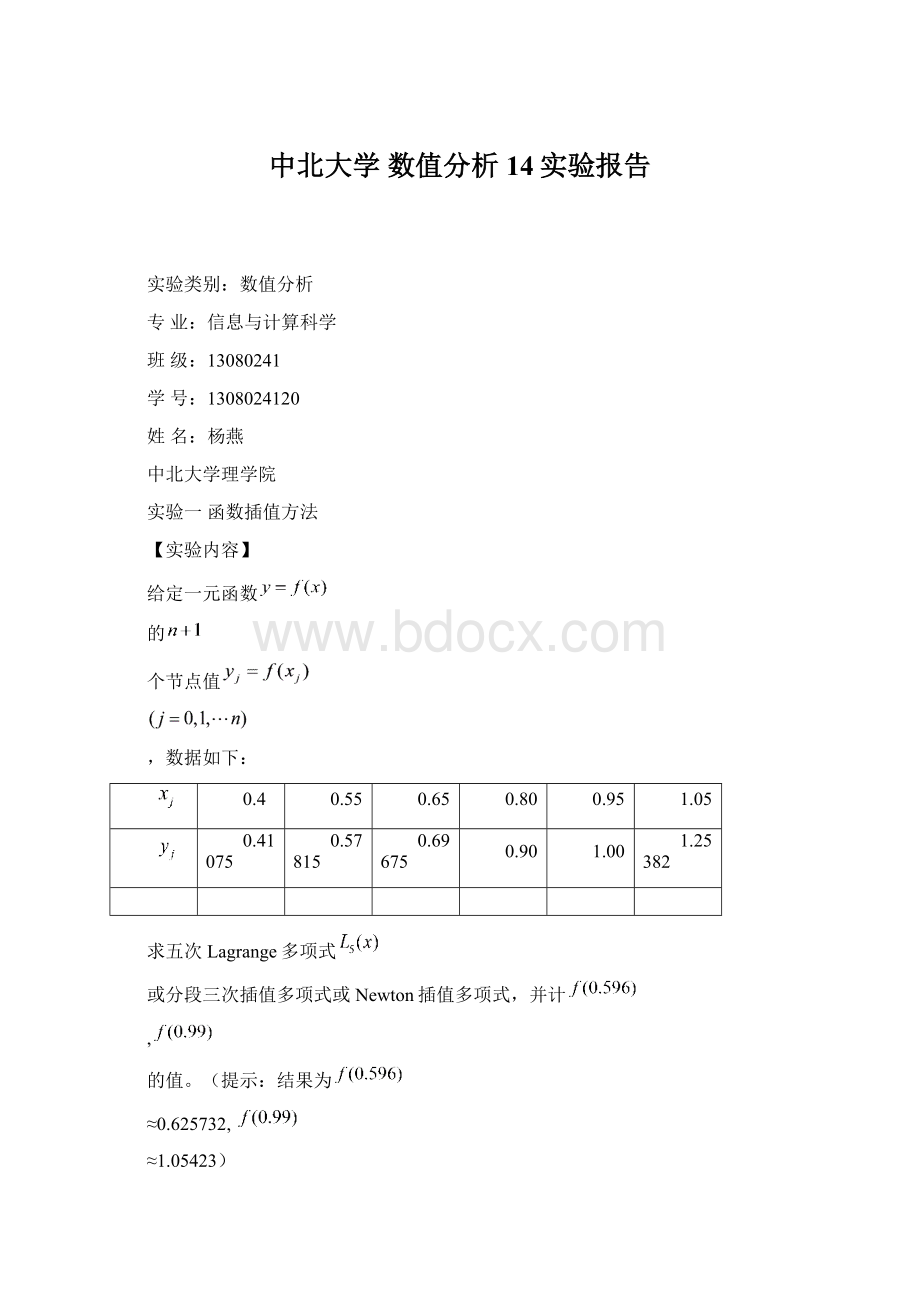
≈0.625732,
≈1.05423)
【实验方法与步骤】
利用Lagrange插值公式
,用C语言编写出插值多项式程序如下:
#include<
stdio.h>
#defineN5
floatx[]={0.4,0.55,0.65,0.80,0.95,1.05};
floaty[]={0.41075,0.57815,0.69675,0.90,1.00,1.25382};
floatp(floatxx)
{
inti,k;
floatpp=0,m1,m2;
for(i=0;
i<
=N;
i++)
{
m1=1;
m2=1;
for(k=0;
k<
k++)
if(k!
=i)
{
m1*=xx-x[k];
m2*=x[i]-x[k];
}
pp+=y[i]*m1/m2;
}
returnpp;
}
main()
printf("
f(0.596)=%lf\n"
p(0.596));
f(0.99)=%lf\n"
p(0.99));
【实验结果】
【思考】
1、给出的程序求
行不行,精度高不高?
2、五次Lagrange多项式与Newton插值多项式是同一个多项式吗?
五次Lagrange多项式与Newton插值多项式是同一个多项式。
3、为什么高次插值不能令人满意?
一般来说,节点个数越多,插值函数和被插值函数就有越多的地方相等。
但是随着插值节点个数的增加,两个插值节点之间插值函数并不一定能够很好地逼近被插值函数。
再次,从舍入误差看,高次插值由于计算量大,可能会产生更严重的误差积累,所以,稳定性得不到保证。
此时就会出现龙格现象。
实验二函数逼近与曲线拟合
1、编写出Legendre、Chebyshev多项式的程序;
2、从随机的数据中找出其规律性,给出其近似表达式,在生产实践和科学实验中大量存在,通常利用数据的最小二乘法求得拟合曲线。
例如在某冶炼过程中,根据统计数据的含碳量与时间关系,试求含碳量
与时间
的拟合曲线。
(
分)
5
10
15
20
25
30
35
40
45
50
55
1.7
2.16
2.86
3.44
3.87
4.15
4.37
4.51
4.58
4.02
4.64
1
1、用C编写语言出Legendre多项式的程序如下:
doublep(intn,doublex)
{
if(n==0)
return1;
else
if(n==1)
returnx;
return((2*n-1)*x*p(n-1,x)-(n-1)*p(n-2,x))/n;
}
intmain()
intn;
doublex;
doubley;
printf("
inputn,x:
\n"
);
scanf("
%d%lf"
&
n,&
x);
y=p(n,x);
%lf\n"
y);
return0;
2、给出表格数据的近似解析表达式为;
,选取基函数
,
,则得到
于是得方程组
,用C语言编写曲线拟合的程序如下:
#include<
#defineMax_N25
main()
inti,n;
doublex[Max_N],y[Max_N];
doublea11,a12,a21,a22,d1,d2;
doublea,b;
\nInputnvalue:
"
do
{
scanf("
%d"
n);
if(n>
Max_N)
printf("
\npleasere_inputnvalue:
}
while(n>
Max_N||n<
=0);
inputx[i],i=0,...%d:
n-1);
n;
i++)
%lf"
x[i]);
inputy[i],i=0,...%d:
y[i]);
a21+=x[i];
a22+=x[i]*x[i];
d1+=y[i];
d2+=x[i]*y[i];
a12=a21;
a11=n;
a=(d1*a22-d2*a12)/(a11*a22-a12*a21);
b=(d1*a21-d2*a11)/(a21*a12-a22*a11);
slove:
P(x)=%f+%fx\n"
a,b);
getchar();
3、为作比较,用MATLAB进行曲线拟合,编写的程序如下:
x=[0510152025303540455055];
y=[01.272.162.863.443.874.154.374.514.584.024.64];
p=polyfit(x,y,1);
disp([num2str(p
(1)),'
*x+'
num2str(p
(2))]);
xx=linspace(0,60,60);
yy=polyval(p,xx);
plot(x,y,'
rx'
xx,yy)
1、C语言编写的Legendre多项式的程序结果如下:
2、C语言拟合的曲线结果如下:
3、MATLAB拟合的曲线结果和误差分析结果如下:
拟合的方程为:
1、最佳一致逼近与最佳平方逼近的区别是什么?
最佳一致逼近中的范数取的是无穷大范数,公式为:
。
最佳平方逼近中的范数取的是二范数,公式为:
2、曲线拟合与最佳平方逼近的区别是什么?
曲线拟合中的
是
上的一个列表函数,公式为:
最佳平方逼近中的
是一个未知函数,公式为:
3、能用什么方法确定最小二乘法的拟合函数?
拟合的方法除了最小二乘法外,还有拉格朗日插值法、牛顿插值法、区间二分法、雅克比迭代法和牛顿科特斯数值积分法等,都可以确定拟合函数。
实验三数值积分与数值微分
选用复合梯形公式,复合Simpson公式,Romberg算法、高斯算法计算
(1)
(2)
(3)
1、用C语言编写Romberg算法数值积分的程序如下:
math.h>
#defineepsilon0.0001/*求基函数*/
floatf(floatx)
return(sqrt(4-sin(x)*sin(x)));
}/*梯形公式*/
floatRomberg(floata,floatb)
intk=1;
floatS,x,T1,T2,S1,S2,C1,C2,R1,R2,h=b-a;
T1=h/2*(f(a)+f(b));
while
(1)
S=0;
x=a+h/2;
do
{
S+=f(x);
x+=h;
}
while(x<
b);
T2=(T1+h*S)/2.0;
if(fabs(T2-T1)<
epsilon)
return(T2);
S2=T2+(T2-T1)/3.0;
if(k==1)
T1=T2;
S1=S2;
h/=2;
k+=1;
continue;
if(fabs(S2-S1)<
epsilon)
return(S2);
C2=S2+(S2-S1)/15.0;
if(k==2)
C1=C2;
T1=T2;
if(fabs(C2-C1)<
return(C2);
R2=C2+(C2-C1)/63.0;
if(k==3)
R1=R2;
C1=C2;
if(fabs(R2-R1)<
return(R2);
R1=R2;
inti;
floata,b,S;
\nInputbeginandend:
%f%f"
a,&
S=Romberg(a,b);
Solveis:
%f"
S);
%"
2、再用复合Simpson公式计算同一个积分,并比较其结果,且用C语言编写的程序如下:
floatSimpson(floata,floatb)
intk=1,n=20;
floats,x1,x2,h=(b-a)/n,c=a+h/2;
s=h/6*(f(a)+f(b)+4*f(c));
for(k=1;
=n-1;
k++)
x1=a+k*h;
x2=x1+h/2;
s=s+(2*h/3)*f(x2)+(h/3)*f(x1);
return(s);
floata,b,s;
请输入a,b:
s=Simpson(a,b);
解为:
s);
3、分别取不同步长
,试比较计算结果(如
等);
4、给定精度要求
,试用变步长算法,确定最佳步长。
1、所给三个定积分的结果如下:
2、对第一个定积分
用Romberg算法和复合Simpson公式计算的结果分别如下:
3、步长为
时,所给三个定积分的结果如下:
4、步长为
1、复合求积公式的优点是什么?
复合求积公式通过把区间分成若干个子区间,再在每个子区间上用低阶求积公式来提高求积的精度。
2、Romberg算法与与牛顿-柯特斯求积算法的联系是什么?
Romberg算法与与牛顿-柯特斯求积算法的节点都是等距选取均匀分布的,且
的牛顿-柯特斯公式因为误差太大而不能使用。
3、高斯算法的求积节点如何确定?
以这些节点为零的多项式
与任何次数不超过
的多项式
带权
正交,即:
4、牛顿-柯特斯求积与高斯算法的节点分布有什么不同?
牛顿-柯特斯求积的节点是等距选取均匀分布的,而高斯算法的节点是满足以这些节点为零的多项式
正交,即是不均匀分布的。
实验四线性方程组的直接解法
(用追赶法)
1、对上述方程组用追赶法求解,用C语言编程如下:
string.h>
#defineN5
floata[N]={0,0,-1,-2,-2};
floatb[N]={0,2,3,4,5};
floatc[N]={0,-1,-2,-2,0};
floatd[N]={0,3,1,0,-5};
floatx[N]={0,0,0,0};
floatr[N]={0,0,0,0};
floaty[N]={0,0,0,0};
floatq;
intk;
r[1]=c[1]/b[1];
y[1]=d[1]/b[1];
for(k=2;
=N-1;
q=b[k]-r[k-1]*a[k];
r[k]=c[k]/q;
y[k]=(d[k]-y[k-1]*a[k])/q;
y[N-1]=(d[N-1]-y[N-2]*a[N-1])/(b[N-1]-r[N-2]*a[N-1]);
x[N-1]=y[N-1];
for(k=N-2;
k>
=1;
k--)
x[k]=y[k]-r[k]*x[k+1];
N;
printf("
x[%d]=%lf\n"
k,x[k]);
2、将结果与精确值进行比较;
3、分析数值解误差的原因。
1、追赶法求解结果:
2、追赶法求解结果与精确值进行比较:
因为此方程组的精确解为
;
与追赶法求解结果一样。
3、分析数值解误差的原因:
此方程组用追赶法求解时没有出现误差,但如果出现误差,我觉得就是在计算过程中的舍入误差逐步累积导致的。
1、列主元消去法为什么选主元?
由高斯消去法知道,小主元可能产生麻烦,应避免采用绝对值小的主元素
,最好每一步选取隶属矩阵中绝对值最大的元素作为主元素,以使高斯消去法具有较好的数值稳定性。
2、全主元消去法与列主元消去法各自的优缺点是什么?
全主元素消去法就是找所有元素的最大值放在顺序主子阵左上角,它的优点是计算值的误差较小,缺点是计算量太大;
列主元素消去法就是找一列中元素的最大值放在顺序主子阵左上角,它的优点是计算量较全主元素消去法来说要小很多,缺点是计算值的误差比用全主元素消去法计算出来的值得误差要大。
3、什么样的线性方程组可用追赶法求解?
线性方程组的系数矩阵为对角占优三对角线矩阵。
4、什么是矩阵的条件数,在算法的误差分析中起什么作用?
为非奇异矩阵,称
为矩阵
的条件数。
的条件数越大,方程组的病态越严重,也就越难用一般的计算方法求得比较准确的解。
5、矩阵的三角分解是什么?
将高斯消去法改写为紧凑形式,可以直接从矩阵
的元素得到计算
元素的递推公式,而不需要任何中间步骤,即将
的问题等价于求解两个三角形方程组:
,求
 升级会员
升级会员 