最近公共祖先LCA打印螺旋矩阵Word下载.docx
《最近公共祖先LCA打印螺旋矩阵Word下载.docx》由会员分享,可在线阅读,更多相关《最近公共祖先LCA打印螺旋矩阵Word下载.docx(30页珍藏版)》请在冰豆网上搜索。
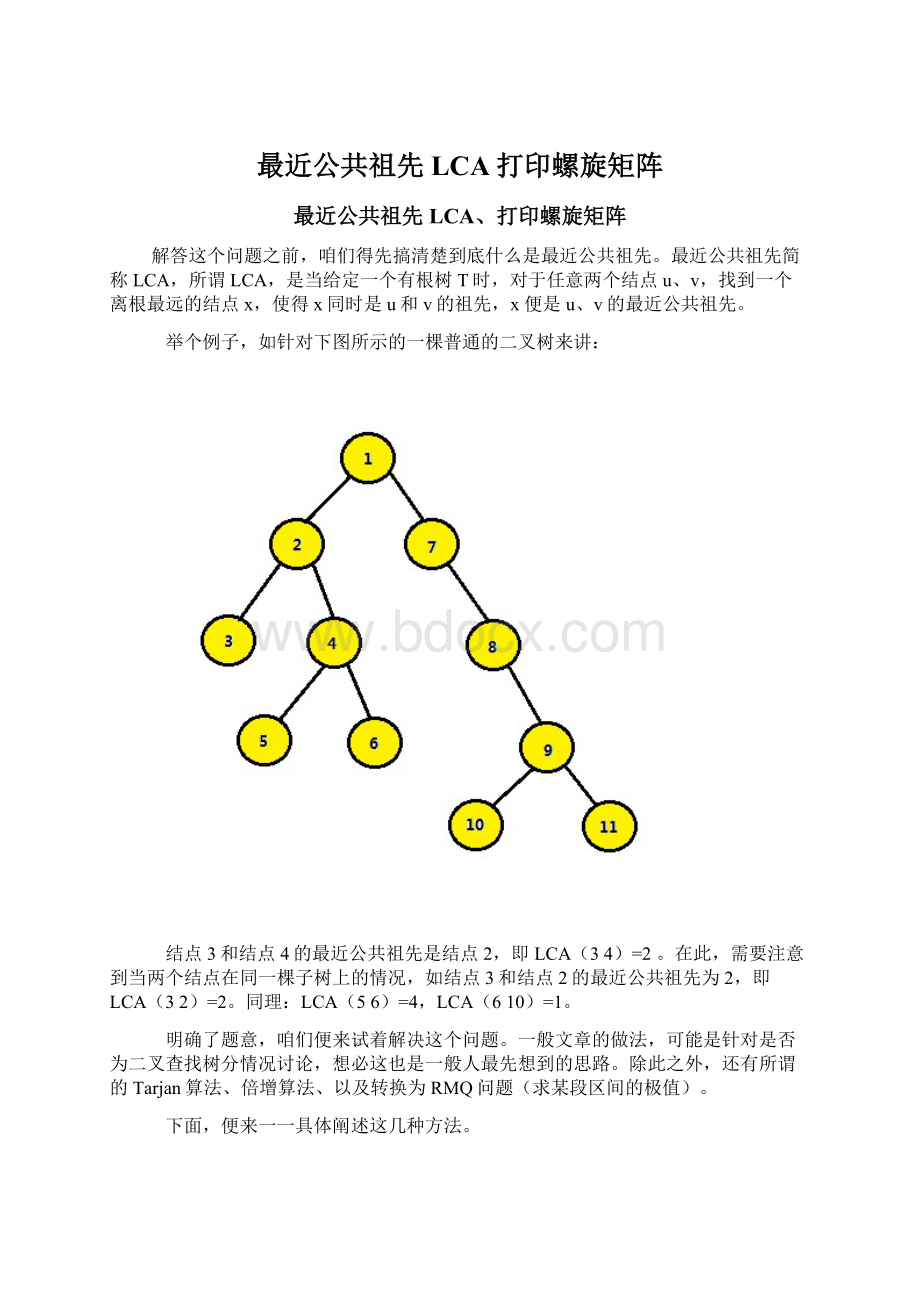
4.
left
=
u.value;
5.
right
v.value;
6.
parent
null;
7.
8.
//二叉查找树内,如果左结点大于右结点,不对,交换
9.
if
(left
>
right)
10.
temp
left;
11.
right;
12.
temp;
13.
}
14.
15.
while
(true)
16.
//如果t小于u、v,往t的右子树中查找
17.
(t.value
<
left)
18.
t;
19.
t
t.right;
20.
21.
//如果t大于u、v,往t的左子树中查找
22.
else
23.
24.
t.left;
25.
==
||
t.value
26.
return
parent.value;
27.
28.
t.value;
29.
30.
31.}
1.2、不是二叉查找树
但如果这棵树不是二叉查找树呢?
一网友何海涛在他博客中用了一种蛮力方法。
由于每个结点都有一个指针指向它的父结点,于是我们可以从任何一个结点出发,得到一个到达树根结点的单向链表。
因此这个问题转换为两个单向链表的第一个公共结点。
我不想再在这里重复赘述,有兴趣的可以看原文。
接下来的解法,将不再区别对待是否为二叉查找树,而是一致当做是一棵普通的二叉树。
总体来说,由于可以把LCA问题看成是询问式的,即给出一系列询问,程序对每一个询问尽快做出反应。
故处理这类问题一般有两种解决方法:
∙一种是在线算法,相当于循序渐进处理;
∙另外一种则是离线算法,如Tarjan算法,相当于一次性批量处理。
解法二、Tarjan算法
如上文末节所述,不论咱们所面对的二叉树是二叉查找树,或不是二叉查找树,都可以把求任意两个结点的最近公共祖先,当做是查询的问题,如果是只求一次,则是单次查询;
如果要求多个任意两个结点的最近公共祖先,则相当于是批量查询。
涉及到批量查询的时候,咱们可以借鉴离线处理的方式,这就引出了解决此LCA问题的Tarjan离线算法。
2.1、什么是Tarjan算法
Tarjan算法(以发现者RobertTarjan命名)是一个在图中寻找强连通分量的算法。
算法的基本思想为:
任选一结点开始进行深度优先搜索dfs(若深度优先搜索结束后仍有未访问的结点,则再从中任选一点再次进行)。
搜索过程中已访问的结点不再访问。
搜索树的若干子树构成了图的强连通分量。
应用到咱们要解决的LCA问题上,则是:
对于新搜索到的一个结点u,先创建由u构成的集合,再对u的每颗子树进行搜索,每搜索完一棵子树,这时候子树中所有的结点的最近公共祖先就是u了。
它的原理是利用并查集优越的时空复杂度,可以实现O(n+q)的算法,q是查询次数。
引用此文的一个例子,如下图(不同颜色的结点相当于不同的集合):
假设遍历完10的孩子,要处理关于10的请求了,取根节点到当前正在遍历的节点的路径为关键路径,即1-3-8-10,集合的祖先便是关键路径上距离集合最近的点。
比如:
∙1,2,5,6为一个集合,祖先为1,集合中点和10的LCA为1
∙3,7为一个集合,祖先为3,集合中点和10的LCA为3
∙8,9,11为一个集合,祖先为8,集合中点和10的LCA为8
∙10,12为一个集合,祖先为10,集合中点和10的LCA为10
得出的结论便是:
LCA(u,v)便是根至u的路径上到节点v最近的点。
2.2、Tarjan算法如何而来
但关键是Tarjan算法是怎么想出来的呢?
再给定下图,你是否能看出来:
分别从结点1的左右子树当中,任取一个结点,设为u、v,这两个任意结点u、v的最近公共祖先都为1。
于此,我们可以得知:
若两个结点u、v分别分布于某节点t的左右子树,那么此节点t即为u和v的最近公共祖先。
更进一步,考虑到一个节点自己就是LCA的情况,得知:
∙若某结点t是两结点u、v的祖先之一,且这两结点并不分布于该结点t的一棵子树中,而是分别在结点t的左子树、右子树中,那么该结点t即为两结点u、v的最近公共祖先。
这个定理就是Tarjan算法的基础。
一如上文1.1节我们得到的结论:
“如果当前结点t满足u<
v,说明u和v分居在t的两侧,故当前结点t即为最近公共祖先”。
而对于本节开头我们所说的“如果要求多个任意两个结点的最近公共祖先,则相当于是批量查询”,即在很多组的询问的情况下,或许可以先确定一个LCA。
例如是根节点1,然后再去检查所有询问,看是否满足刚才的定理,不满足就忽视,满足就赋值,全部弄完,再去假设2号节点是LCA,再去访问一遍。
可此方法需要判断一个结点是在左子树、还是右子树,或是都不在,都只能遍历一棵树,而多次遍历的代价实在是太大了,所以我们需要找到更好的方法。
这就引出了下面要阐述的Tarjan算法,即每个结点只遍历一次,怎么做到的呢,请看下文讲解。
2.3、Tarjan算法流程
Tarjan算法流程为:
Proceduredfs(u);
begin
设置u号节点的祖先为u
若u的左子树不为空,dfs(u-左子树);
若u的右子树不为空,dfs(u-右子树);
访问每一条与u相关的询问u、v
-若v已经被访问过,则输出v当前的祖先t(t即u,v的LCA)
标记u为已经访问,将所有u的孩子包括u本身的祖先改为u的父亲
end
如果树根t正在被遍历,那么当前访问点u必定还在t的未被遍历完成的子树中。
如果v已经被访问过,那么v在其祖先t已被遍历完成的子树中。
u,v分别位于t的不同子树,那么u,v的LCA必定是t。
2.4、Tarjan算法的应用举例
引用此文中的一个例子。
i)访问1的左子树
STEP
1:
从根结点1开始,开始访问结点1、2、3
节点
1
2
3
4
5
6
7
8
祖先
2:
2的左子树结点3访问完毕
3:
开始访问2的右子树中的结点4、5、6
4:
4的左子树中的结点5访问完毕
5:
开始访问4的右子树的结点6
6:
结点4的左、右子树均访问完毕,故4、5、6中任意两个结点的LCA均为4
7:
2的左子树、右子树均访问完毕,故2、3、4、5、6任意两个结点的LCA均为2
如上所述:
进行到此step7,当访问完结点2的左子树(3),和右子树(4、5、6)后,结点2、3、4、5、6这5个结点中,任意两个结点的最近公共祖先均为2。
ii)访问1的右子树
8:
1的左子树访问完毕,开始访问1的右子树
9:
开始访问1的右子树中的结点7、8
10
11
12:
1的右子树中的结点7、8访问完毕
当进行到此step12,访问完1的左子树(2、3、4、5、6),和右子树(7、8)后,结点2、3、4、5、6、7、8这7个结点中任意两个结点的最近公共祖先均为1。
13:
1的左子树、右子树均访问完毕
通过上述例子,我们能看到,使用此Tarjan算法能解决咱们的LCA问题。
解法三、转换为RMQ问题
解决此最近公共祖先问题的还有一个算法,即转换为RMQ问题,用SparseTable(简称ST)算法解决。
Topcoder上有一篇详细阐述RMQ问题的“
RangeMinimumQueryandLowestCommonAncestor
”,网上也有翻译版。
在此,我来简单引用&
总结下。
至于为何要总结的原因很简单:
因为在这里不总结的话,你不会看晦涩难懂的原文,而在这里总结了,你兴许会看。
3.1、什么是RMQ问题
RMQ,全称为RangeMinimumQuery,顾名思义,则是区间最值查询,它被用来在数组中查找两个指定索引中最小值的位置。
即RMQ相当于给定数组A[0,N-1],找出给定的两个索引如i、j间的最小值的位置。
假设一个算法预处理时间为f(n),查询时间为g(n),那么这个算法复杂度的标记为<
f(n),g(n)>
。
我们将用RMQA(i,j)
来表示数组A中索引i和j之间最小值的位置。
u和v的离树T根结点最远的公共祖先用LCAT(u,v)表示。
如下图所示,RMQA(2,7)则表示求数组A中从A[2]~A[7]这段区间中的最小值:
很显然,从上图中,我们可以看出最小值是A[3]=1,所以也就不难得出最小值的索引值RMQA(2,7)=3。
3.2、如何解决RMQ问题
3.2.1、TrivialalgorithmsforRMQ
下面,我们对对每一对索引(i,j),将数组中索引i和j之间最小值的位置
RMQA(i,j)
存储在M[0,N-1][0,N-1]表中。
有不同种计算方法,你会看到,随着计算方法的不同,它的时空复杂度也不同:
∙普通的计算将得到一个<
O(N^3),O
(1)>
复杂度的算法。
尽管如此,通过使用一个简单的动态规划方法,我们可以将复杂度降低到<
O(N^2),O
(1)>
如何做到的呢?
方法如下代码所示:
1.//copyright@
3.void
process1(int
M[MAXN][MAXN],
A[MAXN],
N)
4.{
i,
j;
for
(i
=0;
i
N;
i++)
M[i][i]
i;
0;
(j
+
1;
j
j++)
//若前者小于后者,则把后者的索引值付给M[i][j]
(A[M[i][j
-
1]]
A[j])
M[i][j]
M[i][j
1];
//否则前者的索引值付给M[i][j]
17.}
∙一个比较有趣的点子是把向量分割成sqrt(N)大小的段。
我们将在M[0,sqrt(N)-1]为每一个段保存最小值的位置。
如此,M可以很容易的在O(N)时间内预处理。
∙一个更好的方法预处理RMQ是对2k的长度的子数组进行动态规划。
我们将使用数组M[0,N-1][0,logN]进行保存,其中M[i][j]是以i开始,长度为2j的子数组的最小值的索引。
这就引出了咱们接下来要介绍的SparseTable(ST)algorithm。
3.2.2、SparseTable(ST)algorithm
在上图中,我们可以看出:
∙在A[1]这个长度为2^0的区间内,最小值即为A[1]=4,故最小值的索引M[1][0]为1;
∙在A[1]、A[2]这个长度为2^1的区间内,最小值为A[2]=3,故最小值的索引为M[1][1]=2;
∙在A[1]、A[2]、A[3]、A[4]这个长度为2^2的区间内,最小值为A[3]=1,故最小值的索引M[1][2]=3。
为了计算M[i][j]我们必须找到前半段区间和后半段区间的最小值。
很明显小的片段有着2j-1长度,因此递归如下
根据上述公式,可以写出这个预处理的递归代码,如下:
1.void
process2(int
M[MAXN][LOGMAXN],
2.{
3.
//initialize
M
the
intervals
with
length
1
M[i][0]
//compute
values
from
smaller
to
bigger
(1
j)
A[M[i
1))][j
1]])
M[i
16.}
经过这个O(NlogN)时间复杂度的预处理之后,让我们看看怎样使用它们去计算
RMQA(i,j)。
思路是选择两个能够完全覆盖区间[i..j]的块并且找到它们之间的最小值。
设k=[log(j-i+1)]。
为了计算
RMQA(i,j),我们可以使用下面的公式:
故,综合来看,咱们预处理的时间复杂度从O(N3)降低到了O(NlogN),查询的时间复杂度为O
(1),所以最终的整体复杂度为:
O(NlogN),O
(1)>
3.2.3、线段树Segmenttrees
解决RMQ问题也可以用所谓的线段树。
线段树是一个类似堆的数据结构,可以在基于区间数组上用对数时间进行更新和查询操作。
我们用下面递归方式来定义线段树的[i,j]区间:
∙第一个结点将保存区间[i,j]区间的信息
∙如果i<
j左右的孩子结点将保存区间[i,(i+j)/2]和[(i+j)/2+1,j]的信息
注意具有N个区间元素的线段树的高度为[logN]+1。
下面是区间[0,9]的线段树:
线段树和堆具有相同的结构,因此我们定义x是一个非叶结点,那么左孩子结点为2*x,而右孩子结点为2*x+1。
想要使用线段树解决RMQ问题,我们则要要使用数组M[1,2*2[logN]+1],这里M[i]保存结点i区间最小值的位置。
初始时M的所有元素为-1。
树应当用下面的函数进行初始化(b和e是当前区间的范围):
initialize(int
node,
b,
e,
M[MAXIND],
(b
e)
M[node]
b;
in
and
subtrees
initialize(2
*
/
2,
M,
A,
N);
node
1,
2
//search
minimum
value
first
//second
half
of
interval
(A[M[2
node]]
A[M[2
M[2
node];
18.}
上面的函数映射出了这棵树建造的方式。
当计算一些区间的最小值位置时,我们应当首先查看子结点的值。
调用函数的时候使用node=1,b=0和e
=N-1。
现在我们可以开始进行查询了。
如果我们想要查找区间[i,j]中的最小值的位置时,我们可以使用下一个简单的函数:
1.int
query(int
p1,
p2;
//if
current
doesn'
intersect
//the
query
-1
e
b)
-1;
is
included
&
M[node];
position
//left
part
p1
query(2
j);
 升级会员
升级会员 