计量经济学案例Word格式.docx
《计量经济学案例Word格式.docx》由会员分享,可在线阅读,更多相关《计量经济学案例Word格式.docx(22页珍藏版)》请在冰豆网上搜索。
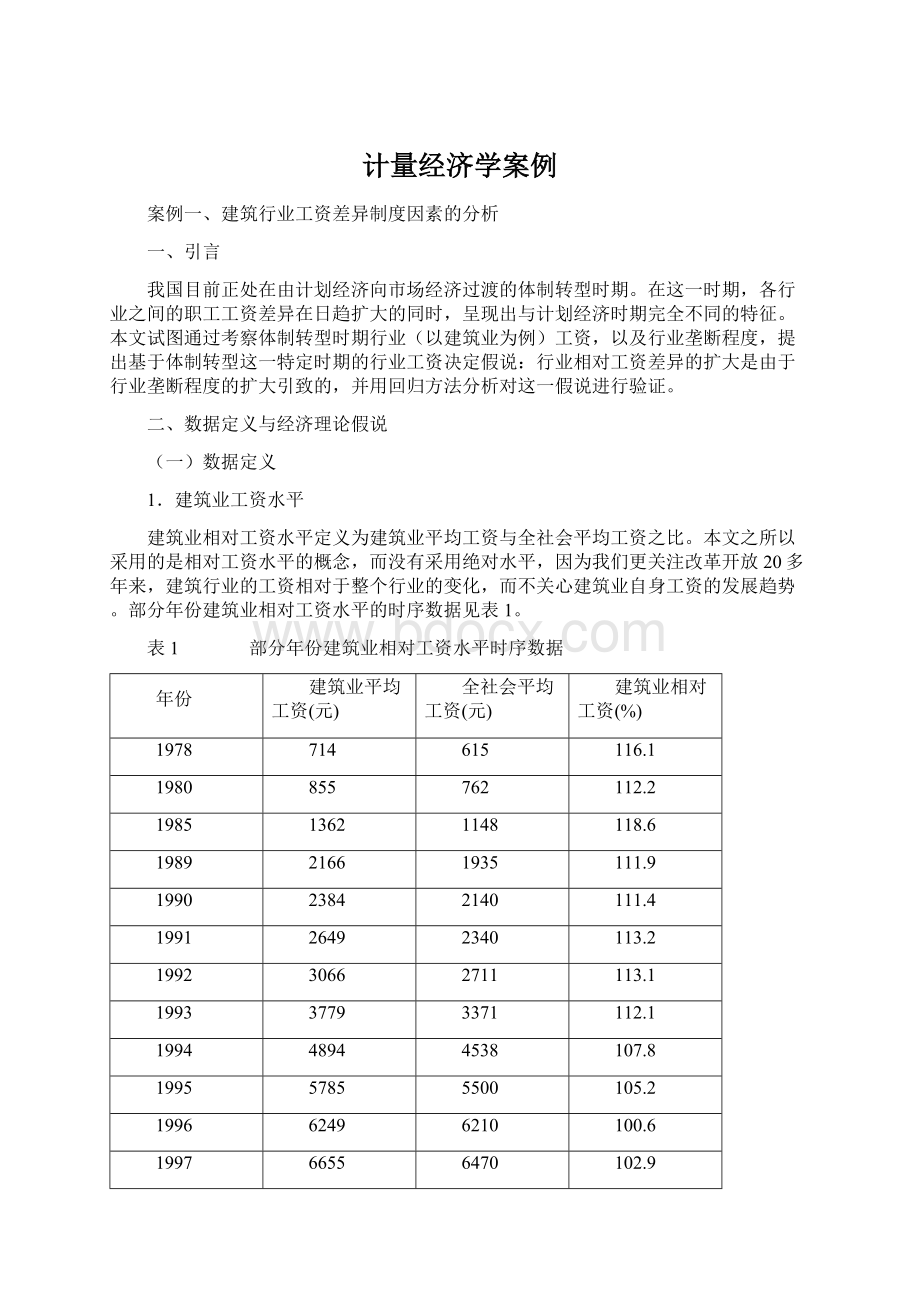
107.8
1995
5785
5500
105.2
1996
6249
6210
100.6
1997
6655
6470
102.9
1998
7456
7479
99.7
1999
7982
8346
95.6
2000
8735
9371
93.2
2001
9484
10870
87.2
2002
10279
12422
82.7
资料来源:
《中国统计年鉴》(2004)第158页。
2.垄断程度
在西方国家,人们通常用一个行业中最大的几家厂商的销售收入的份额表示一个行业的垄断程度。
然而这种方法在我国目前的情况下并不完全适用,因为目前影响(甚至决定)我国行业职工工资水平的并不是一般意义上的垄断,,而是体制转型时期一种特有的垄断,它并不是针对企业的规模而言的,而是针对所有制结构或国有经济成分对行业的控制程度而言的,,即所谓“所有制垄断”或“行政垄断”。
在传统的计划经济体制下,我国经济属于典型的二元经济模式。
如果撇开农村经济这一“元”而不论,城市经济这一“元”的大多数行业基本上都是由国有经济控制的,各行业间在这一点上没有显著性的差别。
然而,随着计划经济体制向市场经济体制的过渡,这种国有经济一统天下的格局逐步被打破,呈现出所有制日趋多元化的的趋势。
但是,不同行业所有制多元化的进程并不一致,由此产生了不同行业间所有制结构的差异。
建筑业相对于电力、金融、房地产等行业,其非国有经济成分进入的门槛相对较低,竞争较为激烈,因此所有制多元化进展较快。
因此,在体制转型时期,我国建筑行业的垄断程度的绝对水平可以在建筑行业的国有化程度上得到大致的体现。
为了获取资料的方便,本文将建筑业国有化程度用建筑业国有单位职工人数占建筑业全部就业人数的比重来表示。
由于不管什么行业,所有制结构多元化、国有经济比重下降是一个总的趋势,而且决定相对工资高低的不是个行业垄断程度的绝对数,而是行业垄断程度与其他行业垄断程度或社会平均水平相比较的相对水平,所以引入相对垄断程度的概念:
相对垄断程度=行业所有制垄断度的绝对数/全社会所有制垄断度的平均数
改革开放以来部分年份建筑业相对垄断度的时序数据见表2。
表2
部分年份建筑业相对垄断度的时序数据
建筑业国有
位职工人数
建筑业
就业人数
国有化程度
全社会国有单位职工人数
全社会职工人数
全社会国有化程度
建筑业国有化相对程度
万人
%
(1)
(2)
(3)=
(1)/
(2)
(4)
(5)
(6)=(4)/(5)
(7)=(3)/(6)
447
854
52.3
7451
40152
18.6
282.1
475
993
47.8
8019
42361
18.9
252.7
545
2035
26.8
8990
49873
18.0
148.6
541
2407
22.5
10109
55329
18.3
123.0
538
2424
22.2
10346
64749
16.0
138.9
557
2482
22.4
10664
65491
16.3
137.8
577
2660
21.7
10889
66152
16.5
131.8
663
3050
10920
66808
133.0
629
3188
19.7
10890
67455
16.1
122.2
605
3322
18.2
10955
68065
113.2
595
3408
17.5
10949
68950
15.9
109.9
3449
16.7
10766
69820
15.4
108.5
444
3327
13.3
8809
70637
12.5
107.0
399
3412
11.7
8336
71394
100.2
372
3552
10.5
7878
72085
10.9
95.8
336
3669
9.2
7409
73025
10.1
90.3
302
3893
7.8
6924
73740
9.4
82.6
《中国统计年鉴》(2004)第127页和第128页。
(二)体制转型期行业工资决定假说
从表1的数据看出,经过20多年,作为具有高劳动强度、艰苦、危险等特征的传统高工资行业之一—建筑业逐渐被挤出高工资行业的行列,在市场经济下建筑业具有进入门槛低、竞争激烈的特征,其工资相对水平逐年下降,2003年建筑业工资只相当于全国平均工资的82%。
而一些原来工资并不太高,但垄断程度至今仍保持较高水平的行业,如金融保险业、房地产业等则陆续进入最高工资行列。
基于上述事实,我们提出如下关于体制转型这一特定时期行业决定的假说:
从总体上看,我国行业相对工资差异的扩大是由于行业垄断程度差异的扩大引致的;
建筑业相对工资水平已经逐渐地不再取决于该行业的拉动强度及艰苦危险程度,而是主要取决于行业的垄断程度。
即建筑业相对工资水平的变化,可以由该行业垄断程度的相对变化所解释。
三、模型设定、估计与检验
将我国建筑业1978年至2002年的主要17个年份的工资相对水平与其垄断相对程度,建立一元计量模型,理论模型如下:
其中
表示建筑业工资相对水平,
表示建筑业相对国有化程度。
根据体制转型期行业工资决定假说,总体参数
应该大于0,相对国有化程度越高,行业垄断程度越高,工资相对水平就越高。
利用计量经济分析软件Eviews进行估计,结果如下:
DependentVariable:
建筑业工资相对水平
Method:
LeastSquares
Sample:
117
Includedobservations:
17
Variable
Coefficient
Std.Error
t-Statistic
Prob.
C
2.939984
11.78218
0.249528
0.8063
建筑业相对国有化程度
1.311088
0.150872
8.690069
0.0000
R-squared
0.834286
Meandependentvar
104.9118
AdjustedR-squared
0.823238
S.D.dependentvar
10.40786
S.E.ofregression
4.375783
Akaikeinfocriterion
5.900179
Sumsquaredresid
287.2121
Schwarzcriterion
5.998204
Loglikelihood
-48.15152
F-statistic
75.51731
Durbin-Watsonstat
0.930656
Prob(F-statistic)
0.000000
以上估计结果发现,可决系数为0.834286,修正的可决系数为0.823238,说明模型拟合优度较高。
建筑业相对国有化程度对建筑业工资相对水平的回归系数为1.311088,t值达到8.690069,通过了变量的统计检验;
并且该回归系数大于0,与理论模型总体参数的预期符号相一致,因此通过了经济意义检验。
但截距项系数2.939984,t值只有0.249528,未通过统计检验,说明建筑业相对国有化程度对建筑业工资相对水平的总体回归直线是通过原点的。
因此理论线性模型应设定为通过原点的回归直线模型,具体形式如下:
再利用计量经济分析软件Eviews进行估计,结果如下:
1.348582
0.013186
102.2770
0.833598
4.245618
5.786674
288.4043
5.835687
-48.18673
Durbin-Watsonstat
0.951702
以上估计结果发现,修正的可决系数为0.833598,高于带截距项模型的修正可决系数,说明去掉截距项的模型拟合优度有了进一步改善。
建筑业相对国有化程度对建筑业工资相对水平的回归系数为1.348582,t值高达102.2770,通过了变量的统计检验。
但该模型的DW值很低,只有0.951702,说明模型的随机误差项之间存在正自相关,因此还需要处理模型的自相关问题。
我们在模型中引入AR
(1)来处理自相关。
估计结果如下:
Sample(adjusted):
217
16afteradjustingendpoints
Convergenceachievedafter4iterations
1.360134
0.020846
65.24616
AR
(1)
0.426743
0.208505
2.046683
0.0599
0.889110
104.2125
0.881190
10.32853
3.560126
5.493937
177.4429
5.590511
-41.95150
1.931114
InvertedARRoots
.43
经过处理,DW值已达到1.931114,很接近2这个理想水平,因此正自相关问题已得到较圆满的解决。
同时模型修正的可决系数0.881190,又得以进一步提高。
四、结果分析
1.本文验证了我们提出的关于体制转型时期行业决定的假说,我国建筑业相对工资差异的扩大主要是由于该行业垄断程度差异的扩大引致的。
2.建筑业相对国有化程度每下降1个百分点,建筑业工资相对水平将会平均下降1.360134个百分点。
案例二、咖啡需求函数——双对数线性模型与弹性系数
由微观经济学中需求理论可知,一种商品的需求量与该商品的价格是息息相关的,一般情况下,商品的价格上涨,会引致该商品需求量下降。
通过观察1970年至1980年11年间美国咖啡消费量与咖啡实际零售价格,建立美国咖啡消费函数模型,考察美国咖啡消费行为规律。
1970年至1980年咖啡消费与平均实际零售价格的时序数据详见下表。
表
咖啡消费(Y)与平均实际零售价格(X)的时序数据
Y(每人每日杯数)
X(美元/磅)
1970
2.57
0.77
1971
2.50
0.74
1972
2.35
0.72
1973
2.30
0.73
1974
2.25
0.76
1975
2.20
0.75
1976
2.11
1.08
1977
1.94
1.81
1.97
1.39
1979
2.06
1.20
2.02
1.17
利用Eviews软件可以绘制咖啡消费Y与平均实际零售价格X的水平尺度散点图,见图1:
从上图可发现咖啡消费y与平均实际零售价格X之间并不是呈线性关系,而是双曲线的非线性关系。
因此理论模型若设定为线性模型形式是不适当的。
处理方法可以有多种,可以采用双曲线模型形式,还可以采用双对数形式,都能够提高模型的拟合度。
而又由于双对数线性形式模型的参数具有很直观的经济含义——即是弹性的概念,于是这里我们试图采用双对数形式。
利用Eviews软件绘制咖啡消费Y与平均实际零售价格X的双对数尺度散点图,见图2:
与图1相比,图2的线性关系更明显,双对数需求函数模型会给出比线性需求函数模型更好的拟合,因此有理由建立一个双对数线性需求函数理论模型
。
估计后的结果如下:
LY
19701980
11
Prob.
0.777418
0.015242
51.00455
LX
-0.253046
0.049374
-5.125086
0.0006
0.744800
0.787284
0.716445
0.094174
0.050148
-2.984727
0.022633
-2.912383
18.41600
26.26651
0.680136
0.000624
从估计结果可以看到价格弹性系数为-0.25,意味着咖啡每磅实际价格每增加1%,咖啡需求量平均减少0.25%。
由于-0.25的价格弹性值在绝对值上小于1,可以说对咖啡的需求是缺乏价格弹性的。
为了与线性需求函数模型进行对比,我们对线性需求函数模型也进行了估计,结果如下:
Y
2.691124
0.121622
22.12686
X
-0.479529
0.114022
-4.205592
0.0023
0.662757
2.206364
0.625286
0.210251
0.128703
-1.099656
0.149080
-1.027311
8.048108
17.68700
0.726590
0.002288
从估计结果看拟合优度明显不如双对数形式模型好,可决系数只有0.662757,着进一步证实了采用双对数形式的咖啡需求函数的正确性。
斜率系数表明咖啡价格每增加1美元/磅,咖啡消费每日每人平均减少0.4795杯。
咖啡需求的平均价格弹性为
这个弹性系数的结果
可与得自双对数模型的弹性系数的结果
相对照。
前一个弹性随着具体样本均值而变化,而后一个弹性不管价格取在哪里都是一样的。
案例三、美国制造业的利润与销售额行为
——虚拟变量在季节分析中的应用
回归模型中,虚拟变量作为定性解释变量的引入,使线性回归模型成为一种极其灵活的工具,可以处理经验研究中遇到的许多有趣的问题。
考察考虑了季节效应影响的美国制造业的利润和销售额的规律,数据如下表:
表
1965-1970年美国制造业利润和销售额情况
(单位:
百万美元)
年和季
利润
销售额
D2
D3
D4
1965-Ⅰ
10503
114862
-Ⅱ
12092
123968
1
10834
121454
-Ⅳ
12201
131917
1966-Ⅰ
12245
129911
14001
140976
12213
137828
12820
145465
1967-Ⅰ
11349
136989
12615
145126
11014
141536
12730
151776
1968-Ⅰ
12539
148862
14849
158913
13203
155727
14947
168409
1969-Ⅰ
14151
162781
15949
176057
14024
172419
14315
183327
1970-Ⅰ
12381
170415
13991
181313
12174
176712
10985
180370
理论模型:
其中
假定“季节”变量有四个类别:
一年的春、夏、秋、冬,因而要用三个虚拟变量。
这样如果在各个季度中显示有季节模式的话,则所估的极差截距项
将在其统计显著性上反映出来。
有可能仅有某些极差截距项统计上显著的,那么,就只有某些相应的季度反映有季节变化。
但该模型是一个一般的模型,可以处理好所有的情形。
Eviews软件估计结果如下:
结果表明只有销售额系数和第二季度的极差截距在5%水平上是统计上显著的。
因此可下结论说,每年二季度由某种季节性因素在运作。
销售额系数0.0383告诉我们,在考虑季节效应之后,如果销售额增加1美元,则平均利润可望增加约4美分。
第一季度的平均利润水平虽是6688美元,而在第二季度中提高了约1323美元,即达到了约8011美元。
由于第二季度似与其余季度有所不同,就不妨仅用一个虚拟变量,以区别二季度和其余季度,重新估计如下:
讨论1:
第二个模型实际上是第一个模型的一种约束形式,其约束是第一、三、四季度的截距项等。
从第一个模型的结果看,我们预期着这些约束是真实的,这需要证实这些约束确是真实的。
因此在做第二个模型之前,需要进行多个回归系数是否相等的显著性检验,从而才能确认仅在第二季度出现某种季度变化。
讨论2:
在两个模型中,我们假定季度之间的差异仅在于截距项,而销售额变量的斜率系数则各季度均相同。
但这个假定需要通过虚拟变量乘法引入的技术加以检验,以确认利润函数在各季度之间没有发生结构性变化,即斜率未发生较大改变。
案例四、消费支出与收入和财富的关系
——多重共线性问题
假定消费与收入和财富有线性关系,并建立如下形式的理论模型:
消费支出、收入和财富的截面数据
单位:
美元
消费支出Y
收入X1
财富X2
70
80
810
65
100
1009
90
120
1273
95
140
 升级会员
升级会员 