SPSS回归分析Word文档下载推荐.docx
《SPSS回归分析Word文档下载推荐.docx》由会员分享,可在线阅读,更多相关《SPSS回归分析Word文档下载推荐.docx(23页珍藏版)》请在冰豆网上搜索。
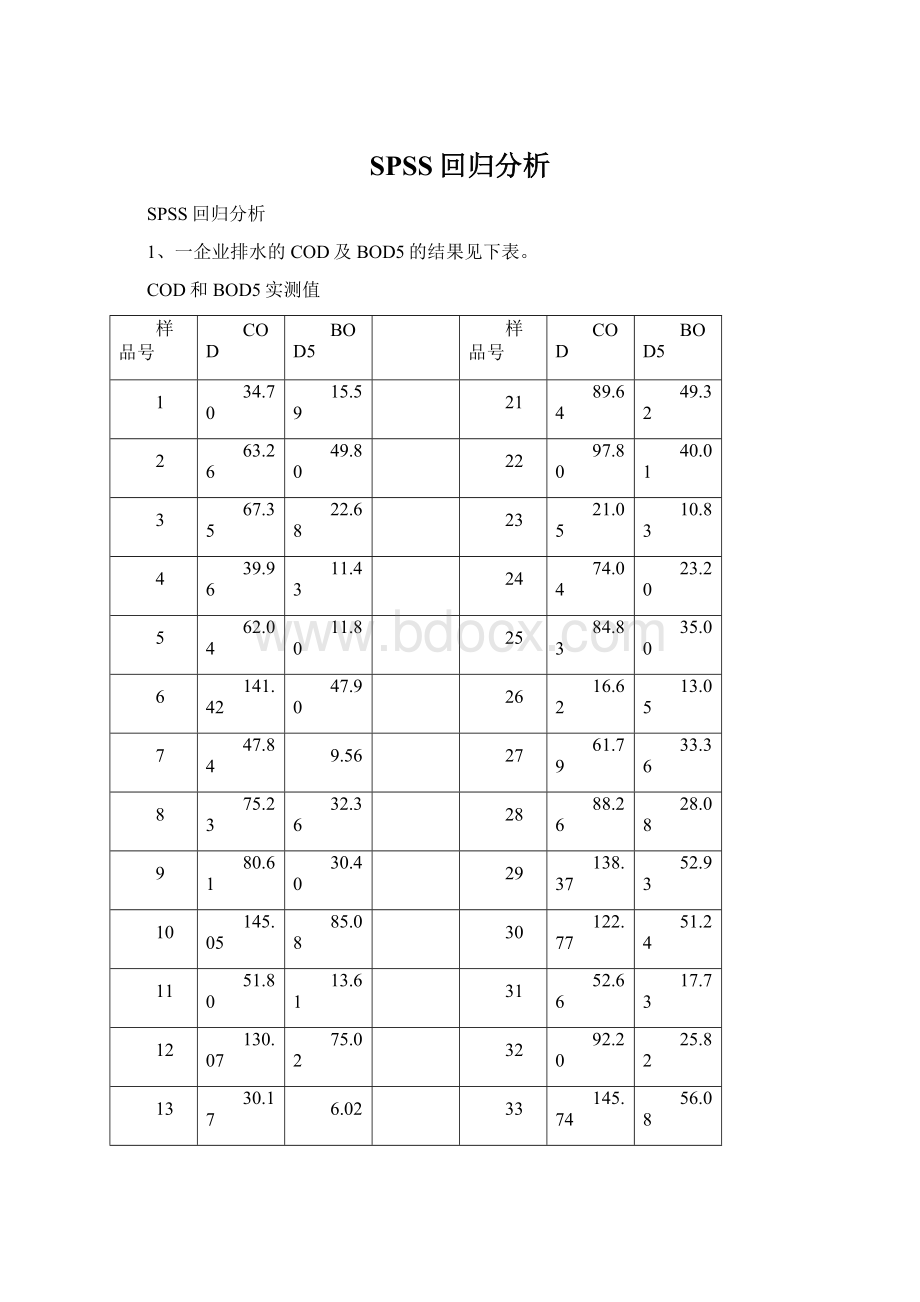
9.56
27
61.79
33.36
8
75.23
32.36
28
88.26
28.08
9
80.61
30.40
29
138.37
52.93
10
145.05
85.08
30
122.77
51.24
11
51.80
13.61
31
52.66
17.73
12
130.07
75.02
32
92.20
25.82
13
30.17
6.02
33
145.74
56.08
14
116.20
73.76
34
117.66
45.04
15
59.00
22.08
35
69.01
26.28
16
52.86
31.68
36
79.01
24.82
17
35.54
6.90
37
81.79
38.40
18
146.51
65.64
38
98.26
44.04
19
94.75
43.32
39
125.64
58.43
20
85.53
38.26
40
142.99
73.68
1)画散点图;
2)判断COD与BOD5之间是否大致呈线性关系;
3)用最小二乘估计求回归方程;
4)计算COD与BOD5的决定系数;
5)对回归方程作残差图,并作分析;
6)计算当COD=99时,BOD5的值;
7)给出置信水平为95%的预测区间。
解:
1)画散点图
1打开SPSS输入数据,点击图形→旧对话框→散点/点状(S),如下图;
②进入散点图/点图,选择简单分布,点击定义,如下图;
③进入简单散点图对话框,选择COD进入X轴、BOD5进入Y轴,点击确定;
④结果输出如下图。
2)判断线性关系
操作:
分析、回归、线性
用SPSS验证:
①打开SPSS输入数据,点击分析→回归→线性,打开线性回归对话框,如下图;
②进入线性回归对话框,选择BOD5进入因变量,COD进入自变量,点击确定,如下图;
③结果如下图。
1-1输入/移去的变量a
模型
输入的变量
移去的变量
方法
CODb
.
输入
a.因变量:
BOD5
b.已输入所有请求的变量。
1-2模型汇总
R
R方
调整R方
标准估计的误差
.885a
.784
.778
9.78593
a.预测变量:
(常量),COD。
1-3Anovaa
平方和
df
均方
F
Sig.
回归
13216.058
138.006
.000b
残差
3639.049
95.764
总计
16855.108
b.预测变量:
1-4系数a
非标准化系数
标准系数
t
B的95.0%置信区间
B
标准误差
试用版
下限
上限
(常量)
-5.360
3.846
-1.394
.172
-13.147
2.426
.492
.042
.885
11.748
.000
.408
.577
④结果分析:
表1-1中显示的是拟合过程中变量输入/移去模型的情况记录,由于只引入了一个自变量,所以只出现一个模型1,该模型中“COD”为进入的变量,没有移除的变量,具体的输入/移去方法为输入。
表1-2是模型拟合概述,列出了模型的R、R2、调整R2及估计标准误。
R2值越大所反映的两变量的共变量比率越高,模型与数据的拟合程度越好。
本题所用数据拟合结果显示:
R(所考察的自变量和因变量之间的相关系数)=0.885,R2(拟合线性回归的决定系数)=0.784,经调整后的R2=0.778,标准误的估计=9.78593。
表1-3方差分析表,列出了变异源、自由度、均方、F值及对F的显著性检验。
本题中回归方程显著性检验结果表明:
回归平方和为13216.058,残差平方和为3639.049,总平方和为16855.108,对应的F统计量的值为138.006,Sig=0.000<
0.05,可以认为所建立的回归方程有效,所以COD与BOD5之间成线性关系。
表1-4回归系数表,列出了常数及非标准化回归系数的值及标准化的回归系数,同时对其进行显著性检验。
本题中非标准化的回归系数B的估计值为0.492,标准误为0.042,标准化的回归系数为0.885,回归系数显著性检验t统计量的值为11.748,对应显著性水平Sig.=0.000<
0.05,可以偏回归系数与0有显著性差异,被解释的变量和解释的变量的线性关系是显著的,因此,本题回归分析得到的回归方程为:
y=-0.492x-5.360。
对方程的方差分析及对回归系数的显著性检验均发现,所建立的回归方程显著。
综上所述,COD与BOD5之间大致呈线性关系。
3)用最小二乘估计求回归方程
由表1-4得到,
(常量)=-5.36,
=0.492。
由公式
(
为COD,y为BOD5)得到
0.492
4)决定系数
①重复第2问的前2步,点击绘制,出现线性回归:
图对话框,选择“ZPRED(标准化预测值)”进入Y(Y)、“SRESID(学生化残差)”进入X2(X),点击继续,如下图;
②结果运行如下图。
1-5残差统计量a
极小值
极大值
均值
标准偏差
N
预测值
2.8247
66.7924
36.0058
18.40851
标准预测值
-1.802
1.672
1.000
预测值的标准误差
1.548
3.221
2.120
.548
调整的预测值
1.5827
67.4974
35.9723
18.46004
-16.38572
24.00624
.00000
9.65966
标准残差
-1.674
2.453
.987
Student化残差
-1.751
2.495
.002
1.015
已删除的残差
-17.91795
24.82268
.03341
10.22469
Student化已删除的残差
2.692
.012
1.047
Mahal。
距离
3.249
.975
1.020
Cook的距离
.214
.030
.047
居中杠杆值
.083
.025
.026
图1-6
③结果分析:
残差图主要用于残差分析,判断残差与因变量之间是否相互独立,还可以判断模型的拟合效果。
从图1-6可以看出各点随即分布在e=0为中心的横带中,证明了该模型时适合的。
同时有部分点出现了异常,这种离群点时值得进一步研究。
①在EXCEL中输入数据,插入函数,在选择类别中的常用函数中选择“FORECAST”如下图;
②在出现的函数参数的对话框中Known_y′s中选择B列,在Known_x′s中选择A列,X中输入99,结果如下图
所以当COD=99时,BOD5=43.39295347
7)给出置信水平为95%的预测区间
①在输出文档中,选中散点图,右击选择编辑内容、在单独窗口中,出现图标编辑器,如下图;
②在图标编辑器对话框中,选择元素→总计拟合线→属性,在属性中的拟合线中的拟合方法中选择线性,置信区间中选择个体,如下图;
③运行结果如下图。
∵2=2801,tα/2=2.021
∴L1=43.39295347-2.021×
√2801=43.39295347-106.96
L2=43.39295347+2.021×
√2801=43.39295347+106.96
∴43.39295347-106.96﹤y0﹤43.39295347+106.96
2、在一项水分渗透试验中,得观测时间和水的重量的数据如下表。
观测时间和水的重量数据
观测时间
/s
64
水的重量y/g
4.22
4.02
3.85
3.59
3.44
3.02
2.59
1)画出散点图;
2)求曲线回归方程y=a
b;
3)对lny与ln
之间的回归关系进行显著性检验α=0.05
解:
1)1)画散点图
2进入散点图/点图,选择简单分布,点击定义,如下图;
3进入简单散点图对话框,选择水的重量进入X轴、观测时间进入Y轴,点击确定;
④结果输出如下图。
b
根据题目,可以判断出这题的回归方程需要用曲线估计来算出。
分析、回归、曲线估计
①打开SPSS输入数据,点击分析→回归→曲线估计,打开线性回归对话框,如下图;
②进入线性回归对话框,选择水的重量进入因变量,观测时间进入变量,在模型中选择指数分布,点击确定,如下图;
③结果运行如下图。
2-1模型汇总
估计值的标准误
.968
.938
.925
自变量为观测时间。
2-2ANOVA
.166
75.316
.011
.177
2-3系数
未标准化系数
标准化系数
标准误
Beta
观测时间
-.007
.001
-.968
-8.678
(常数)
3.980
.093
42.901
因变量为ln(水的重量)。
表2-1是模型拟合概述,列出了模型的R、R2、调整R2及估计标准误R=0.968,R2=0.938,调整后的R2=0.925,估计值得标准误=0.047。
R2=0.968,说明自变量与因变量的相关性很强。
R2=0.938,说明变量
可以解释因变量y的93.8%的差异性。
表2-2显示因变量的方差来源、方差平方和、自由度、均方、F检验统计量和显著性水平。
从表中可以看出,方差来源有回归、残差和总和,F检验的统计量的观测值为75.316,Sig(显著性概率)为0.000,即检验假设“H0:
回归系数B=0”成立的概率为0.000,从而应拒绝零假设,说明因变量和自变量的曲线关系是非常显著,可建立指数模型。
表2-3中显示回归模型的常数项、回归系数B值及其标准误差、标准化的回归系数Beta、统计量t值以及显著性水平(Sig)。
从表中可以看出,回归模型的常数项为3.980,自变量“观测时间”的回归系数为-0.007。
因此,可以得到回归方程为:
y=3.980
-0.007(
观测时间,y为水的重量)
令y′=lny,
′=ln
a′=lna,b′=b
于是线性化后线性回归方程为y=a′+b′
将原始数据施行上述变换后得
0.69
1.39
2.08
2.77
3.47
4.16
y
1.44
1.35
1.28
1.24
1.11
0.95
1打开SPSS输入数据,点击分析→回归→线性,打开线性回归对话框,如下图;
②选择y进入因变量,x进入自变量,在统计量对话框中选择估计和置信区间以及模型拟合度,点击确定,如下图;
2-4输入/移去的变量a
xb
y
2-5模型汇总
.963a
.928
.913
.05043
(常量),x。
2-6Anovaa
.164
64.314
.013
.003
.176
2-7系数a
1.481
.034
43.099
1.392
1.569
x
-.110
.014
-.963
-8.020
-.146
-.075
表2-4中显示回归模型编号、进入模型的变量、移出模型的变量和变量的筛选方法。
可以看出,进入模型的自变量为“
”(ln
).
表2-5为所模拟模型的情况汇总,显示在模型1中:
相关系数R=0.963,拟合优度R2=0.928,调整后的拟合优度=0.913,标准估计的误差=0.05043.
表2-6是所用模型的检验结果,一个便准的方差分析表。
回归模型F用计量值=64.314,Sig=0.000<
0.005,说明二者之间用当前模型进行回归有统计学意义,可以用模型进行回归。
表2-7给出了包括常数项在内的所有系数的检验结果,用的是t检验,同时还会给出标准化/未标准化系数,可见常数项和
都是有统计学意义的。
由此得到ln
、lny之间的一元回归方程为y=1.481-0.110
。
综上所述,当显著性水平α=0.005时,lny与ln
之间的回归关系显著。
 升级会员
升级会员 