按照教学大纲内容实验设计按照章节内容依次展开如下所Word文档下载推荐.docx
《按照教学大纲内容实验设计按照章节内容依次展开如下所Word文档下载推荐.docx》由会员分享,可在线阅读,更多相关《按照教学大纲内容实验设计按照章节内容依次展开如下所Word文档下载推荐.docx(31页珍藏版)》请在冰豆网上搜索。
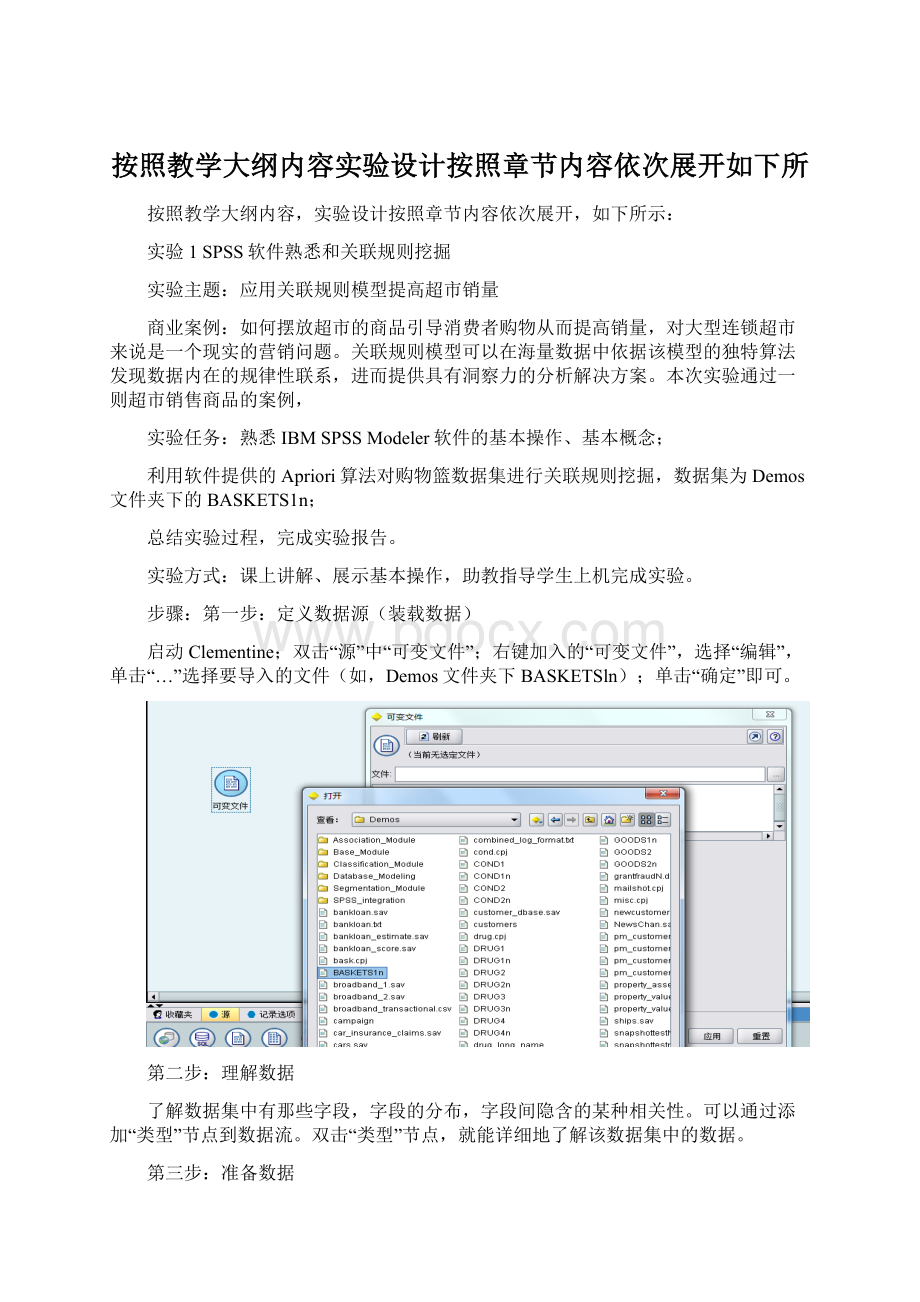
可以通过添加“类型”节点到数据流。
双击“类型”节点,就能详细地了解该数据集中的数据。
第三步:
准备数据
把暂时没有用到的字段剔除。
做法:
选中“类型”,通过“方向”列中的选项设定。
第四步:
建模
模型一:
“Apriori”
将“建模”中的“Apriori”模型节点加入到数据流中。
右键单击“Apriori”节点,选择“执行”,此时,在右侧管理器窗口“模型”中就会生成一个模型。
右键单击该模型,选择“浏览”。
查看结果:
模型二:
“GRI”
在数据流上增加“GRI”模型,步骤同“Apriori”模型。
但是对于市场购物篮数据分析,得到的结果不同(比Apriori模型多了一种商品——frozenmeal)。
说明,数据挖掘中,模型的不同,得到的结果也可能不同。
“Apriori”模型和“GRI”模型都属于定量分型方法;
下面给出一种定性分析方法。
步骤三:
定性分析方法:
“网络”
前面两个模型是采用定量的分析,下面采用一种定性的分析——“网络”。
双击“网络”节点,将“网络”节点加入到数据流中。
对网络节点进行设置。
同“类型”节点的做法一样,对与挖掘无关的字段进行剔除。
右键单击“网络”,选择“执行”。
拖动游标,可得到不同关联强度的字段关联规则。
数据流图:
运行结果:
实验2利用SPSS软件进行分类建模
应用SPSS决策树分析超市顾客购物信息
使用超市顾客购物信息,建立一个健康食品购买者的决策树分析。
假设同时购买鱼和水果的顾客为健康食品购买者。
利用IBMSPSSModeler软件提供的决策树算法,对超市购买信息进行决策树分析,建立模型,对结果进行分析并完成实验报告。
导入数据
在“选项板区”找到“源”中的“手动输入”,双击“手动输入”,将其添加到数
据流区域。
查看导入数据
添加新的属性
增加一个属性health,并设定同时购买鱼和水果顾客的健康属性为T,否则为F。
设定节点类型,属性的流入流出方向。
第五步:
添加C5.0节点,并生成生成树查看结果。
第六步:
增加C&
RT节点
增加CART算法决策树,并查看结果。
实验3利用SPSS软件进行聚类分析
应用SPSS帮助电信运营商细分用户
目前电信运营商面临着激烈的市场竞争。
对电信运营商来说,客户即生命,如何保持现有客户是企业客户管理的重中之重。
用户细分后,企业管理者可以根据不同客户群体的特征,做出不同的营销策略。
本次实验利用IBMSPSSModeler中提供的k均值聚类方法对用户进行聚类,并对结果进行分析和应用。
该次实验数据集需要进行一定预处理。
利用数据集建立模型,细分用户后完成实验报告。
选定对话框
打开SPSS软件,选择菜单栏中的【File(文件)】→【Open(打开)】→【Data(数据)】命令,弹出【OpenData(打开数据)】对话框。
选定打开文件类型
在【Filesoftype(文件类型)】下拉列表框中指定打开Excel文件类型。
接着,选择iris.xls文件。
最后单击【Open(打开)】按钮。
设置变量名称
弹出的对话框中的【Readvariablenamesfromthefirstrowofdate(从第一行数据读取变量名)】复选框表示SPSS将Excel工作表的第一行设定为SPSS的变量名称,【Range(范围)】文本框表示选定Excel文件导入SPSS的数据范围。
这里,保持系统默认选项。
完成操作
最后,单击【OK(确定)】按钮,数据即可导入成功。
此时,SPSS的数据浏览窗口中会出现相关的数据内容。
打开对话框
选择菜单栏中的【Analyze(分析)】→【Classify(分类)】→【K-MeansCluster(K均值聚类)】命令,弹出【K-MeansClusterAnalysis(K均值聚类分析)】对话框,这是快速聚类分析的主操作窗口。
选择聚类分析变量
在【K-MeansClusterAnalysis(K均值聚类分析)】对话框左侧的候选变量列表框中选择进行聚类分析的变量,将其添加至【Variables(变量)】列表框中。
同时可以选择一个标识变量移入【LabelCasesby(个案标记依据)】列表框中。
第七步:
确定分类个数
在【NumberofClusters(聚类数)】列表框中,可以输入确定的聚类分析数目,用户可以根据需要自行修改调整。
系统默认的聚类数为2。
第八步:
选择聚类方法
在【Method(方法)】下拉列表框中可以选择聚类方法。
系统默认值选择【Iterativeandclassify(迭代与分类)】项。
Iterateandclassify:
选择初始类中心,在迭代过程中不断更新聚类中心。
把观测量分派到与之最近的以类中心为标志的类中去。
Classifyonly:
只使用初始类中心对观测量进行分类,聚类中心始终不变。
第九步:
聚类中心的输入与输出
在主对话框中,【ClusterCenters(聚类中心)】选项组表示输入和输出聚类中心。
用户可以指定外部文件或数据集作为初始聚类中心点,也可以将聚类分析的聚类中心结果输出到指定文件或数据集中。
第十步:
输出聚类结果
在主对话框中单击【Save(保存)】按钮,弹出【SaveNewVariables(保存新变量)】对话框,它用于选择保存新变量。
结果:
实验4利用SPSS软件挖掘频繁序列模式
应用序列模式挖掘购物篮,建立聪明的营销策略
同实验一,但这次使用序列模式挖掘,分析的将更加详尽。
利用IBMSPSSModeler软件提供的序列模式挖掘功能对购物篮进行序列模式挖掘,更深入的挖掘超市购物记录,建模后分析实验结果,并完成实验报告。
实验步骤:
实验将采用购物篮作为实验案例,输入数据如下表所示,给出了五个用户的购物清单:
Seq.ID
Sequence
1
<
(bd)cb(ac)>
2
(bf)(ce)b(fg)>
3
(ah)(bf)abf>
4
(be)(ce)d>
5
a(bd)bcb(ade)>
1.导入数据:
在“选项板区”找到“源”中的“手动输入”,双击“手动输入”,将其添加到数据流区域。
双击数据流区域的“用户输入”,选中“生成数据”的方式为“状况良好”,并输入数据如下:
id代表用户id,time标识购物的先后顺序,a-h代表商品,F代表未购买,T代表已购买。
值区域每一列代表一个购物项。
如第一列的含义为:
用户1第1次购买的商品为b和d。
点击上图中的“类型”,修改“方向”栏如下:
2.单击选中数据流区域的“用户输入”,再双击“选项板区”中“建模”下的“序列”,将其添加至数据流区域,它将自动与“用户输入”连接。
双击数据流区域的“无目标”,将对话框填写如下,点击“执行”
你将在右上角看到分析结果节点,如图:
双击“id”将其添加到数据流区域,如下:
3.双击数据流区域中的“id”,得到分析结果。
4.点击上图中的“
”,选择“显示全部”,则实验结果如下
实验5利用SPSS软件分析社交网络
实验目的:
掌握PageRank算法的基本原理,分析影响算法性能的因素。
实验要求:
根据伪代码,实现简单的PageRank算法,并验证结果
分析影响迭代次数的两个因素S和,并测试
1.编程实现简单的PageRank算法,验证输出结果
2.
改变S和,查看结果输出
实验结果
(1):
S=(0.715,0.714,0.724,0.718,0.708,0.723,0.726)
=0.01
实验结果
(2):
=0.005
实验结果(3):
S=(1,1,1,1,1,1,1)
实验6利用SPSS软件进行异常检测
应用SPSS进行异常检测
背景是关于农业发展贷款申请。
主要考虑两种贷款类型:
土地开发贷款和退耕贷款。
找出那些农场类型和大小来说申请贷款过多的农场主。
完成实验报告。
字段名称
含义
Id
农场主标识符
Name
姓名
region
位置
Farmsize
农场大小
Rainfall
农场的年降水量
Landquality
农场对地产质量的声明
Farmincome
农场的年产量
Maincrop
农场内的主要作物
Claimtype
农场主要申请的贷款类型
claimvalue
申请贷款数额
一、准备数据
1.在数据流中连接“条形图”节点并选定字段名为“name”的字段。
2.选中“name”字段之后,单击“执行”按钮。
3.在数据流区域中添加一个“选择”节点,把该节点连接到数据流中,双击该节点,模式选择“丢弃”单选按钮、条件文本框中输入“name==‘name618’orname==‘name777’”。
4.一农场大小、主要作物类别、土壤质量等作为自变量建立一个回归模型来估计一个农场的收入是多少。
建模以前,还要添加一个“导出”节点,以便使用CLEM语言来生成一个新的字段。
5.为了发现那些偏离估计值得农场,可以先生成一个字段---diff,代表估计值与实际值偏离的百分数。
在数据流中再增加一个“导出”节点。
6.在数据流中增加一个“直方图”节点。
双击“直方图”节点,将“直方图”按照那个claimtype进行层叠。
7.设置完成后,单击“执行”按钮。
8.选择一个“选择”节点添加到“导出”节点“diff”的后面,使用CLEM表达式claimtype==’arable_dev’来进行筛选。
二、建模
1.将一个“类型”即诶但添加到当前数据流中,对数据集中的数据进行设置。
将calimvalue的方向设置为“输出”,id、name、farmincome的方向设置为“无”,其他字段设置为“输入”。
2.单击“确定”按钮之后双击“神经网络”节点,在数据流上添加一个“神经网络”节点。
3.设置完成之后,单击“执行”按钮,得出预测值与真实声明值的对照图。
4.在数据流中增加一个“导出”节点,双击该节点,对该节点进行设置,在“导出字段”框中给该字段命名为claimdiff,“导出为”下拉列表中选择“公式”。
在下面的“公式”框中输入CLEM表达式:
(abs(claimvalue-‘$N-claimvalue’/’claimvalue’))*100。
5.在数据流中再添加一个“直方图”节点。
双击该节点,在“字段”下啦列表中选择“claimdiff”单击“执行”按钮。
6.增加一个分割带到直方图中,右击带区生成一个选择节点,进一步查看那些claimdiff值较大的数据。
7.选择“生成带状区域的选择节点”命令后,在数据流区域就会出现一个“带状区域1”的“选择”节点。
把它添加到“claimdiff”节点后,双击该节点。
8.在该数据流中再增加一个“条形图”节点。
双击该节点,在“字段”下拉列表中选择“name”字段,单击“执行”按钮,得出实验结果。
5.导入数据:
6.单击选中数据流区域的“用户输入”,再双击“选项板区”中“建模”下的“序列”,将其添加至数据流区域,它将自动与“用户输入”连接。
7.双击数据流区域中的“id”,得到分析结果。
8.点击上图中的“
3.编程实现简单的PageRank算法,验证输出结果
4.
二、准备数据
9.在数据流中连接“条形图”节点并选定字段名为“name”的字段。
10.选中“name”字段之后,单击“执行”按钮。
11.在数据流区域中添加一个“选择”节点,把该节点连接到数据流中,双击该节点,模式选择“丢弃”单选按钮、条件文本框中输入“name==‘name618’orname==‘name777’”。
12.一农场大小、主要作物类别、土壤质量等作为自变量建立一个回归模型来估计一个农场的收入是多少。
13.为了发现那些偏离估计值得农场,可以先生成一个字段---diff,代表估计值与实际值偏离的百分数。
14.在数据流中增加一个“直方图”节点。
15.设置完成后,单击“执行”按钮。
16.选择一个“选择”节点添加到“导出”节点“diff”的后面,使用CLEM表达式claimtype==’arable_dev’来进行筛选。
三、建模
9.将一个“类型”即诶但添加到当前数据流中,对数据集中的数据进行设置。
10.单击“确定”按钮之后双击“神经网络”节点,在数据流上添加一个“神经网络”节点。
11.设置完成之后,单击“执行”按钮,得出预测值与真实声明值的对照图。
12.在数据流中增加一个“导出”节点,双击该节点,对该节点进行设置,在“导出字段”框中给该字段命名为claimdiff,“导出为”下拉列表中选择“公式”。
13.在数据流中再添加一个“直方图”节点。
14.增加一个分割带到直方图中,右击带区生成一个选择节点,进一步查看那些claimdiff值较大的数据。
15.选择“生成带状区域的选择节点”命令后,在数据流区域就会出现一个“带状区域1”的“选择”节点。
16.在该数据流中再增加一个“条形图”节点。
 升级会员
升级会员 