生物统计学课件--11方差分析PPT格式课件下载.ppt
《生物统计学课件--11方差分析PPT格式课件下载.ppt》由会员分享,可在线阅读,更多相关《生物统计学课件--11方差分析PPT格式课件下载.ppt(58页珍藏版)》请在冰豆网上搜索。
(1-0.05)3=0.953=0.8574而则是拒绝H0的最小概率,也即显著水平,是发生I型错误的概率。
对四个样本平均数进行成组数据的t检验,则发生I型错误的概率为:
方差分析方差分析由此可见,使用一般意义上的tt检验,对三个或三个以上的样本平均数进行差异显著性测验时,是不合适的,需要引进新的检验方法。
这就是我们即将介绍的第七章方差(变量)分析(Analysisofvariance,ANOVA)方差分析是一类特定条件下的统计推断,或者说是平均数差异显著性测验的一种引申。
第一节方差分析的基本原理方差或称均方,它是一个表示变异的量。
在一项实验或调查中,往往存在许多造成生物性状变异的因素。
这些因素中有主要的,有次要的,方差分析就是要将总变异分裂为各个变异因素引起的变异,并对其作出数量估计,从而发现各个因素在变异中所占的重要程度。
在实验中,除了可以控制的实验因素造在实验中,除了可以控制的实验因素造成的变异以外,剩余的变异可以提供实成的变异以外,剩余的变异可以提供实验误差准确无偏的估计,作为统计假设验误差准确无偏的估计,作为统计假设测验的依据。
测验的依据。
方差分析可以帮助我们掌握客观规律的方差分析可以帮助我们掌握客观规律的主要矛盾或技术关键,是科学研究工作主要矛盾或技术关键,是科学研究工作中的重要工具。
中的重要工具。
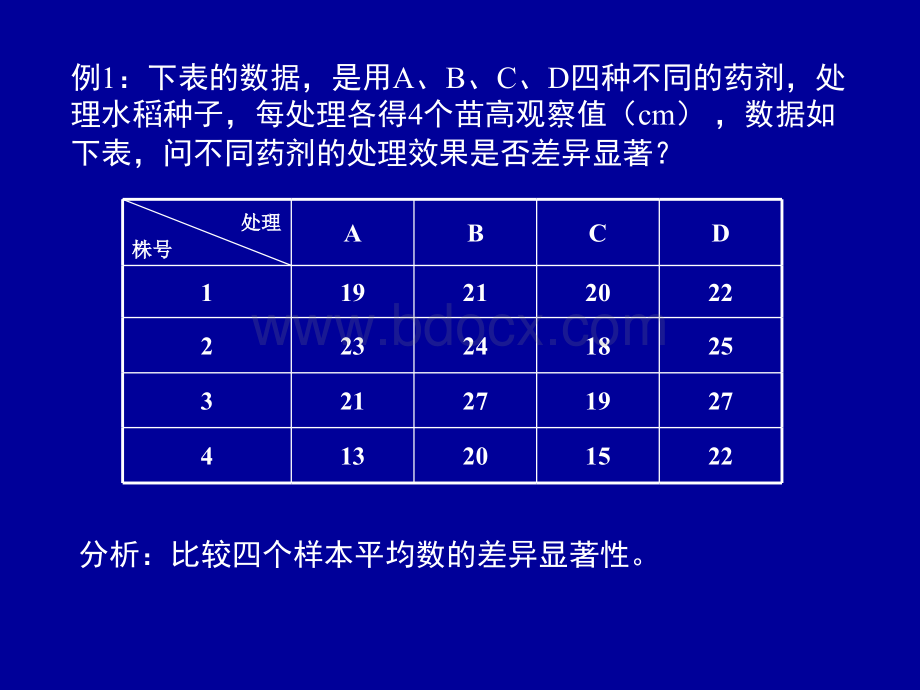
例例1:
下表的数据,是用:
下表的数据,是用A、B、C、D四种不同的四种不同的药剂,处理水稻种子,每处理各得药剂,处理水稻种子,每处理各得4个苗高观察值个苗高观察值(cm),数据如下表数据如下表,问不同药剂的处理效果是问不同药剂的处理效果是否差异显著?
否差异显著?
分析:
处理处理株号株号ABCD119212022223241825321271927413201522和和76927296平均平均x19231824数据处理:
现在的测验目的就是要比较19,23,18,24这四个平均数的差异显著性。
处理处理株号株号ABCD119212022223241825321271927413201522和和76927296平均平均x19231824现在,我们可以将A、B、C、D四种药剂处理的种子当作四个亚总体看待,每处理的4个观察值当作该亚总体的一个随机样本,比较四个样本的平均数的差异显著性。
为了这一目的,我们有必要分析一下试验数据的总变异即总的试验方差是多少。
在这个实验中,引起数据变异的原因有不同的药剂不同的药剂试验误差试验误差我们可以尝试将试验的总变异分解为由药剂处理我们可以尝试将试验的总变异分解为由药剂处理引起的变异(方差)和由于试验误差引起的变异引起的变异(方差)和由于试验误差引起的变异(方差),并且对两者的差异显著性作出判断。
(方差),并且对两者的差异显著性作出判断。
若这两个方差差异显著,且药剂的方差大于误差方差,则必然不同处理(药剂)间的差异显著,即四个样本平均数的差异是显著的;
否则,则样本平均数间的差异不显著。
据此,我们就可以对多个平均数进行比较。
处理处理平方和平方和误差误差自由度自由度处理处理自由度自由度方差方差=平方和平方和/自由度自由度总的平方和总的平方和总的自由度总的自由度误差误差平方和平方和若处理方差显著大于误差方差,则不同实验处若处理方差显著大于误差方差,则不同实验处理间的平均数,至少有两个是差异显著的理间的平均数,至少有两个是差异显著的处处理理株株号号ABCD119212022223241825321271927413201522和和76927296平均平均x19231824一、平方和与自由度的分解一、平方和与自由度的分解目的:
将总的自由度与总的平方和分解为各个变目的:
将总的自由度与总的平方和分解为各个变异因素引起的自由度与平方和,从而求出各个变异因素引起的自由度与平方和,从而求出各个变异因素引起的方差。
异因素引起的方差。
1、自由度的分解:
、自由度的分解:
df总总=dfT=kn-1=44-1=15df处处=dft=k-1=4-1=3df误误=dfe=k(n-1)=4(4-1)=12df总总=df处处+df误误=3+12=15,dfT=dft+dfe=3+12=15其中其中kk为样本数,为样本数,nn为每个样本的样本容量。
为每个样本的样本容量。
22、平方和的分解:
、平方和的分解:
处处理理株株号号ABCD119212022223241825321271927413201522和和76927296平均平均x19231824未考虑不同药剂对株高的影响3、求各个变异原因引起的方差、求各个变异原因引起的方差二、二、F检验检验在我们的试验中,我们想推断不同药剂对水稻苗高的影响差异是否显著。
我们已经分析了在这个实验中,引起水稻苗高变异的原因有两个,一个是不同药剂的处理效果,一个是试验误差,在这两个原因中,哪一个占主导地位?
如果由于不同药剂的处理引起的变异即处理方差明显大于误差方差,则不同药剂间的苗高平均数必然差异显著,否则,则平均数的差异不显否。
现在问题的关键是处理方差和误差方差是否差异显著?
若测验两个方差的差异显著性,我们可以进行F检验。
在方差分析的体系中,F测验是用于测验某项变异因素的效应是否真实存在,所以在计算F值时,总是将要测验的那一项变异因素的方差做分子,而以另一项变异因素的方差做分母,在测验时,若分子的方差小于做分母的方差,则F0.05,接受H0。
H0:
t2=e2,HA:
t2e2,=0.05F3,12,0.05=3.49,FF0.05,3,12,拒绝拒绝H0:
t2=e2,接受HA:
t2e2,即药剂间对水稻苗高的影响差异是显著的。
三、进行平均数的多重比较1、最小显著差数法(LSD法)原理:
在两个独立样本(成组数据)的平均数的差异显著性测验中,若:
1=2=,且n1=n2=n则:
若:
则:
|t|t0.05/2,dfe则:
两个平均数差异显著即:
也即:
称为最小显著差数,并以LSD表示。
即:
称均数差异标准差本例中,当据此,不同平均数在据此,不同平均数在0.05显著水平进行的多重比较的最小显著显著水平进行的多重比较的最小显著差数差数LSD0.05=4.83。
这种比较会加大犯I型错误的概率。
因此,实际应用于在试验设计中有标准或对照的试验数据的分析。
若该试验的AA药剂为对照,则前述多重比较的结果:
处理处理平均数平均数各处理与平均数的各处理与平均数的差数差数B234C18-1D245*A19LSD法多重比较的结果法多重比较的结果2、最小显著极差法(、最小显著极差法(LSR法)法)这种方法的特点是不同的平均数间的比这种方法的特点是不同的平均数间的比较采用不同的显著差数标准,因而克服较采用不同的显著差数标准,因而克服了了LSD法的局限性。
法的局限性。
可以用于任意两个平均数间的所有相互可以用于任意两个平均数间的所有相互比较。
比较。
最小显著极差的计算公式:
其中:
SSR(k,df)可以从附表99中查出。
SSR(k,df)由两个参数决定,一个是自由度,另一个是秩次距秩次距kk。
附表9即为SSR值表。
改r为SSR。
dfk23456789102050100190.0214.038.268.58.646.516.86.955.705.966.11204.024.224.33403.891003.71附表附表9多重比较中的多重比较中的Duncan表表r0.01(k,df)秩次距k是两个欲比较的平均数间包含的平均数的个数。
把平均数按照从小到大的次序排列起来,确定秩次距:
据此,可以计算出据此,可以计算出LSRLSR值表,用以平均数的多重比较。
值表,用以平均数的多重比较。
LSR值值计算表计算表k234SSR0.053.083.223.33SSR0.014.324.554.68LSR0.054.845.075.23LSR0.016.787.147.35例例:
4种药剂对水稻苗高影响多重比较的种药剂对水稻苗高影响多重比较的LSR值的计算值的计算:
当当df=dfe=12,查,查SSR值表,计算值表,计算LSR:
编号编号43216*5125431梯形表法处理代号处理代号DBAC平均数平均数24231918编号编号12343、多重比较的表示方法将平均数按从大到小(或从小到大)排列并编码:
将不同编号的平均数的差数列在相应的位置上,标星号的为平均数间的差异显著。
处理代号处理代号平均数平均数显著水平显著水平0.050.01D24aB23A19C18利用字母标记法表示多重比较的结果处理代号处理代号平均数平均数显著水平显著水平0.050.01D24aB23aA19C18处理代号处理代号平均数平均数显著水平显著水平0.050.01D24aB23aA19aC18处理代号处理代号平均数平均数显著水平显著水平0.050.01D24aB23aA19aC18b处理代号处理代号平均数平均数显著水平显著水平0.050.01D24aB23aA19abC18b处理代号处理代号平均数平均数显著水平显著水平0.050.01D24aB23abA19abC18b处理代号处理代号平均数平均数显著水平显著水平0.050.01D24aAB23abAA19abAC18bAk234LSR0.054.845.075.23LSR0.016.787.147.35方差分析中平方和与自由度分解的计算公式:
方差分析中平方和与自由度分解的计算公式:
四、方差分析的基本假定四、方差分析的基本假定11、可加性、可加性每个处理的效应与误差的效应是可加的,即每个处理的效应与误差的效应是可加的,即处处理理株株号号ABCD119212022223241825321271927413201522平均平均x192318242、正态性试验误差ijij是服从正态分布N(0,2)的独立随机变量。
若实验误差之间可能存在某种关联时,可以采用随机化的方法去破坏,例如取对数或取反正弦值等。
3、方差的齐性各处理的误差方差应具备齐性,它们具有一个公共的总体方差2,一般以实验的误差方差Se2来作为2的点估计值。
五、两种不同的处理效应
(一)有关试验设计的几个概念1、试验指标:
衡量试验结果的标准2、试验因素:
就是影响试验指标的人为条件或措施3、(因素)水平:
是对试验因素在质的方面或量的方面进行的分级4、处理(组合)
(二)两种不同的处理效应1、固定因素及固定效应模型2、随机因素及随机效应模型若试验因素的水平是从该因素的所有水平中随机选取的,则称该试验因素为随机因素,该数据方差分析的效应模型为随机模型不同模型对结论的解释不同,随机模型的结论可以外延和扩展,固定模型的结论,不可以扩展,只在选定的水平内有效。
第二节单向分组资料的方差分析一、单向分组资料的特点:
二、组内重复观察值数相等的方差分析n1=n2=nk
(一)平方和与自由度的分解公式
(二)例题1调查了5个不同小麦品系的株高,列于下表,问这5个小麦品系的株高,差异是否显著?
68.670
 升级会员
升级会员 