几款分布式数据库的对比Word文档格式.doc
《几款分布式数据库的对比Word文档格式.doc》由会员分享,可在线阅读,更多相关《几款分布式数据库的对比Word文档格式.doc(10页珍藏版)》请在冰豆网上搜索。
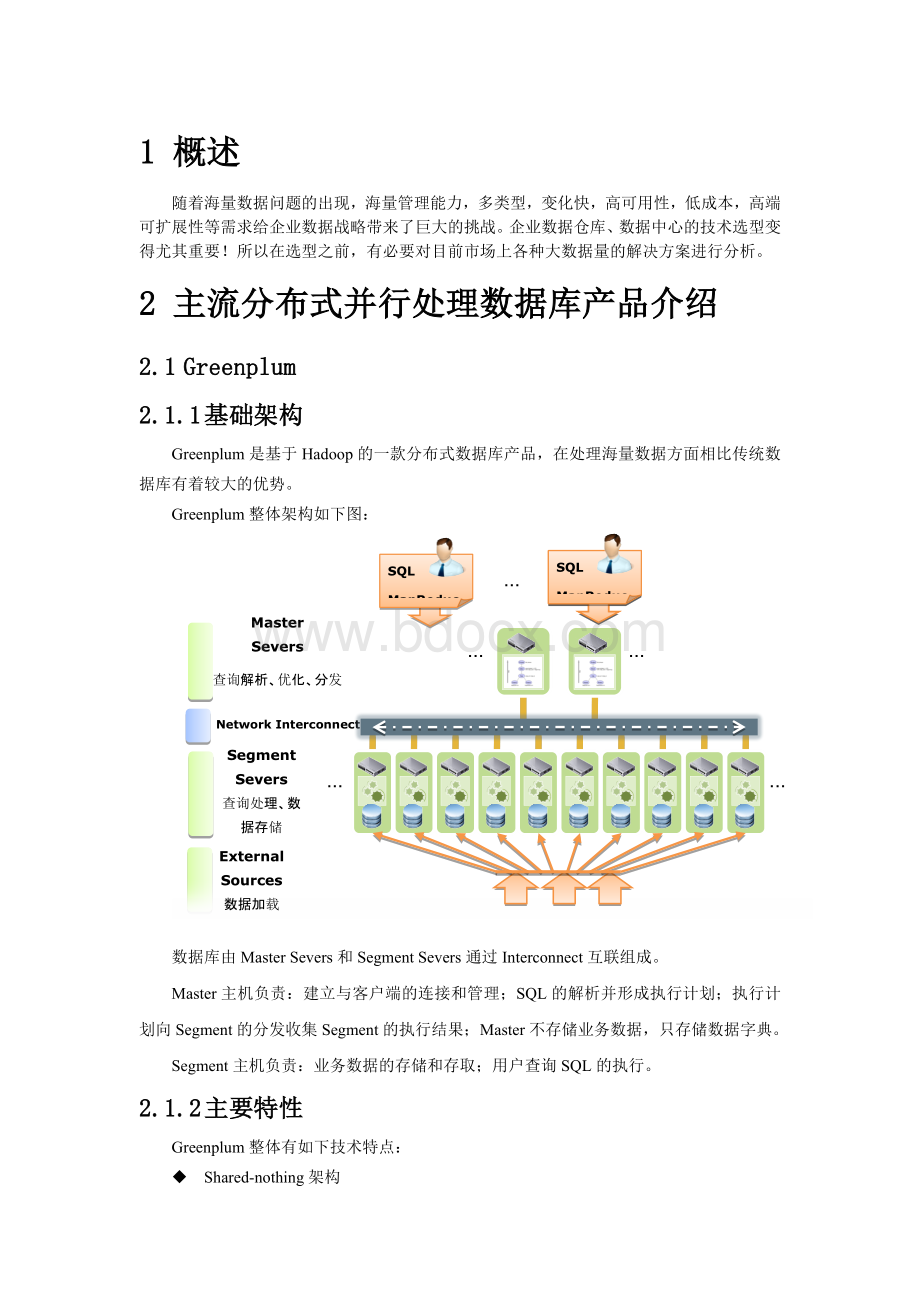
查询解析、优化、分发
Segment
查询处理、数据存储
SQL
MapReduce
External
Sources
数据加载
数据库由MasterSevers和SegmentSevers通过Interconnect互联组成。
Master主机负责:
建立与客户端的连接和管理;
SQL的解析并形成执行计划;
执行计划向Segment的分发收集Segment的执行结果;
Master不存储业务数据,只存储数据字典。
Segment主机负责:
业务数据的存储和存取;
用户查询SQL的执行。
2.1.2主要特性
Greenplum整体有如下技术特点:
uShared-nothing架构
海量数据库采用最易于扩展的Shared-nothing架构,每个节点都有自己的操作系统、数据库、硬件资源,节点之间通过网络来通信。
u基于gNetSoftwareInterconnect
数据库的内部通信通过基于超级计算的“软件Switch”内部连接层,基于通用的gNet(GigE,10GigE)NICs/switches在节点间传递消息和数据,采用高扩展协议,支持扩展到1000个以上节点。
u并行加载技术
利用并行数据流引擎,数据加载完全并行,加载数据可达到4。
5T/小时(理想配置)。
并且可以直接通过SQL语句对外部表进行操作
u支持行、列压缩存储技术
海量数据库支持ZLIB和QUICKLZ方式的压缩,压缩比可到10:
1。
压缩数据不一定会带来性能的下降,压缩表通过利用空闲的CPU资源,而减少I/O资源占用。
海量数据库除支持主流的行存储模式外,还支持列存储模式。
如果常用的查询只取表中少量字段,则列模式效率更高,如查询需要取表中的大量字段,行模式效率更高。
海量数据库的多种压缩存储技术在提高数据存储能力的同时,也可根据不同应用需求提高查询的效率
2.1.3主要局限
l列存储模式的使用有限制,不支持delete/update操作。
l用户不可灵活控制事务的提交,用户提交的处理将被自动视作整体事务,整体提交,整体回滚。
l数据库需要额外的空间清理维护(vacuum),给数据库维护带来额外的工作量。
l用户不能灵活分配或控制服务器资源。
l对磁盘IO有比较高的要求。
l备份机制还不完善,没有增量备份。
2.2Vertica
2.2.1基础架构
与以往常见的行式关系型数据库不同,Vertica是一种基于列存储(Column-Oriented)的数据库体系结构,这种存储机构更适合在数据仓库存储和商业智能方面发挥特长。
常见的RDBMS都是面向行(Row-OrientedDatabase)存储的,在对某一列汇总计算的时候几乎不可避免的要进行额外的I/O寻址扫描,而面向列存储的数据库能够连续进行I/O操作,减少了I/O开销,从而达到数量级上的性能提升。
同时,Vertica支持海量并行存储(MPP)架构,实现了完全无共享,因此扩展容易,可以利用廉价的硬件来获取高的性能,具有很高的性价比。
如下图,展示的是单节点上的Vertica的基本体系结构。
Vertica体系结构
作为关系型数据库,Vertica的查询SQL也是在前端被解析和优化的。
但与传统的关系型数据库有所不同,Vertica内部是混合存储的,包括两种不同的存储结构:
写优化器(WOS)和读优化器(ROS)。
(1)写优化器WOS(Write-OptimizedStore)
是位于主存储器上的一个数据结构,用于有效的支持数据插入和更新操作;
数据的存放是无序的,非压缩的。
(2)读优化器ROS(Read-OptimizedStore)
是磁盘物理存储,存放的是排序和压缩后的数据库大块数据,因此这里的查询相比于WOS性能更好。
(3)TupleMover进程
是Vertica内部的一个进程,定期的以大数据块的形式把数据从WOS移到ROS,由于是对整个WOS操作,TupleMover一次能非常有效的排序很多记录,最后批量把它们写入磁盘。
在Vertica内部,不论是WOS还是ROS都是按列存储的。
2.2.2主要特性
Vertica的关键特性:
1列存储(Column-orientation)
由于大多数的查询都是要从磁盘读取数据,因此可以说diskI/O在很大程度上决定了一个查询的最终响应时间。
2压缩机制(AggressiveCompression)
在数据存储方面,Vertica利用内部的特定算法对数据进行压缩处理。
这样的机制会大大减少diskI/O的时间(D),同时由于Vertica对扫描和聚合等操作也在内部进行了优化,可以直接处理压缩后的数据,这样CPU的工作负载(C)也减少了。
如上例中的AVG聚合函数,Vertica是不需要将压缩数据先做类似解压这种处理的,因此查询性能得到优化。
3读优化存储(Read-OptimizedStorage)
Vertica的数据库存储容器ROSContainer专门为读操作进行了优化设计,且其中的数据是经过了排序和压缩处理的,即每个磁盘页上不会有空白空间,而传统的数据库一般会在每页上预留空间以便日后的insert操作来使用。
4多种排序方式的冗余存储
为了高可用性和备份恢复的需要,Vertica会按照不同的排序方式对数据做冗余存储,这不但避免了大量的日志操作,也为查询带来了便利。
Vertica的查询优化器会自动选择最优的排序方式来完成特定的查询。
5并行无共享设计
Vertica支持完全无共享海量并行存储(MPP)架构,随着硬件Server的增加,多个CPU并行处理,性能也可以得到线性的扩展,这样用户使用廉价的硬件就可以获得较高的性能改善。
6其他管理特征
除了有优越的性能以外,Vertica在数据库管理方面也进行了非常人性化的设计。
VerticaDatabaseDesigner是一个界面化的日常管理工具,并且能为用户作出详尽的DB层物理设计方案,大大减少了日后的性能调优方面的开销。
Vertica通过K-Safety值的设置,完成了数据库的备份恢复机制,并保证了高可用性。
对于数据库中的每个表每个列,Vertica都会在至少K+1个节点上存储,如果有K个节点宕机,依然能够保证VerticaDB是完整可用的;
当损坏的节点恢复时,Vertica自动完成节点间的热交换,把其他节点上的正确数据恢复过来。
通过这种机制也保证了Vertcia库的节点数目可以自由伸缩而不会影响到数据库的操作。
Vertica通过两种技术来实现在线的持续数据装载而不会影响到数据库的访问。
Vertica通常运行在快照隔离(SnapshotIsolation)模式下,该模式下查询读取的是最近的一致的数据库快照,这个快照是不能被并发的update或delete操作更改的,因此查询操作也不需要占用锁,这种方式保证了数据装载(insert)和其他查询能互不干扰。
另外,Vertica可以把数据直接装载到WOS结构中,WOS中的数据是不排序或索引的,所以装载速度会很快,然后再由TupleMover进程在后台把数据移入ROS中,由于TupleMover的操作是大块读取(bulk-load)的,所以性能也很好。
2.2.3主要局限
l不支持SQL存储过程及函数,用户需通过UDFs(UserDefinedFunction,基于C++)来自定义函数或过程。
l软件授权按原始未经压缩的裸数据量计算。
l列存储的一些劣势,复杂查询等性能不理想。
l对内存有比较高的要求。
l在国内还没有成功案例。
2.3SybaseIQ(15.4)
2.3.1基础架构
SYBASEIQ是Sybase公司推出的特别为数据仓库设计的关系型数据库。
SYBASEIQ的架构与大多数关系型数据库不同,它特别的设计用以支持大量并发用户的即席查询。
其设计与执行进程优先考虑查询性能,其次是完成批量数据更新的速度。
而传统关系型数据库引擎的设计既考虑在线的事务进程又考虑数据仓库(而事实上,往往更多的关注事务进程)。
Sybase在2010年推出的SybaseIQ15.3就采用了全共享架构的PlexQ技术,该技术重新定义了企业范围的业务信息,全共享架构可轻松支持涉及海量数据集、海量并发用户数和独特工作流程的多种复杂分析样式,大大增加了其效益。
与其他MPP解决方案不同,SybaseIQ的PlexQ网格技术能够动态管理可轻松扩展并且专用于不同组和流程的一系列计算与存储资源中的分析工作量,从而使其能够以更低的成本更轻松地支持日益增长的数据量以及快速增长的用户社区。
SybaseIQ15.4采用业内领先的MPP列式数据库和最先进的数据库内分析技术,并革命性地加入MapReduce与Hadoop集成,以应对大数据时代的分析挑战,开启洞察关键业务的能力。
SybaseIQ15.4正在打破数据分析的壁垒,彻底改变“大数据分析”领域。
基于成熟的PlexQ技术构建的SybaseIQ采用下图所示的三层构架:
基本层:
数据库管理系统(DBMS),这是一个全共享MPP分析DBMS引擎,是SybaseIQ最大的独特优势。
第二层:
分析应用程序服务层,其提供C++和Java数据库内API,并可实现与外部数据源的集成和联邦;
包括四种与Hadoop的集成方法。
顶层:
SybaseIQ生态系统,由四个强大且不同的合作伙伴和认证ISV应用程序组成。
基于这种PlexQ技术,SybaseIQ15.4将大数据转变成可指挥每个人都行动的情报信息,从而在整个企业的用户和业务流程范围内轻松具备大数据的分析能力。
2.3.2主要特性
SybaseIQ(15.4)的关键特性:
1.
更强的数据管理
大量增强的功能改善了SybaseIQ的数据管理、部署和可维护性。
更快速的批量加载:
批量加载数据通过ODBC和JDBC接口插入到Sybase中,从而实现具有更高可扩展性的应用程序,同时可极大提高加载性能。
更出色的文本压缩:
更出色地对VARCHAR、VARBINARY、CHAR和BINARY压缩可实现以更高效率、更低成本部署高性能文本分析应用程序,同时极大提高压缩速率。
2.
丰富的应用程序
SybaseIQ15.4增加了一系列API和工具,用于创建在数据库内运行的高级分析算法,并且能通过PlexQ网格能充分利用大规模并行处理的能力。
支持自带MapReduce的表参数化用户自定义函数(UDF)——这是SybaseIQ的本地应用程序编程接口
 升级会员
升级会员 