服务器硬件架构.docx
《服务器硬件架构.docx》由会员分享,可在线阅读,更多相关《服务器硬件架构.docx(43页珍藏版)》请在冰豆网上搜索。
服务器硬件架构
盛年不重来,一日难再晨。
及时宜自勉,岁月不待人。
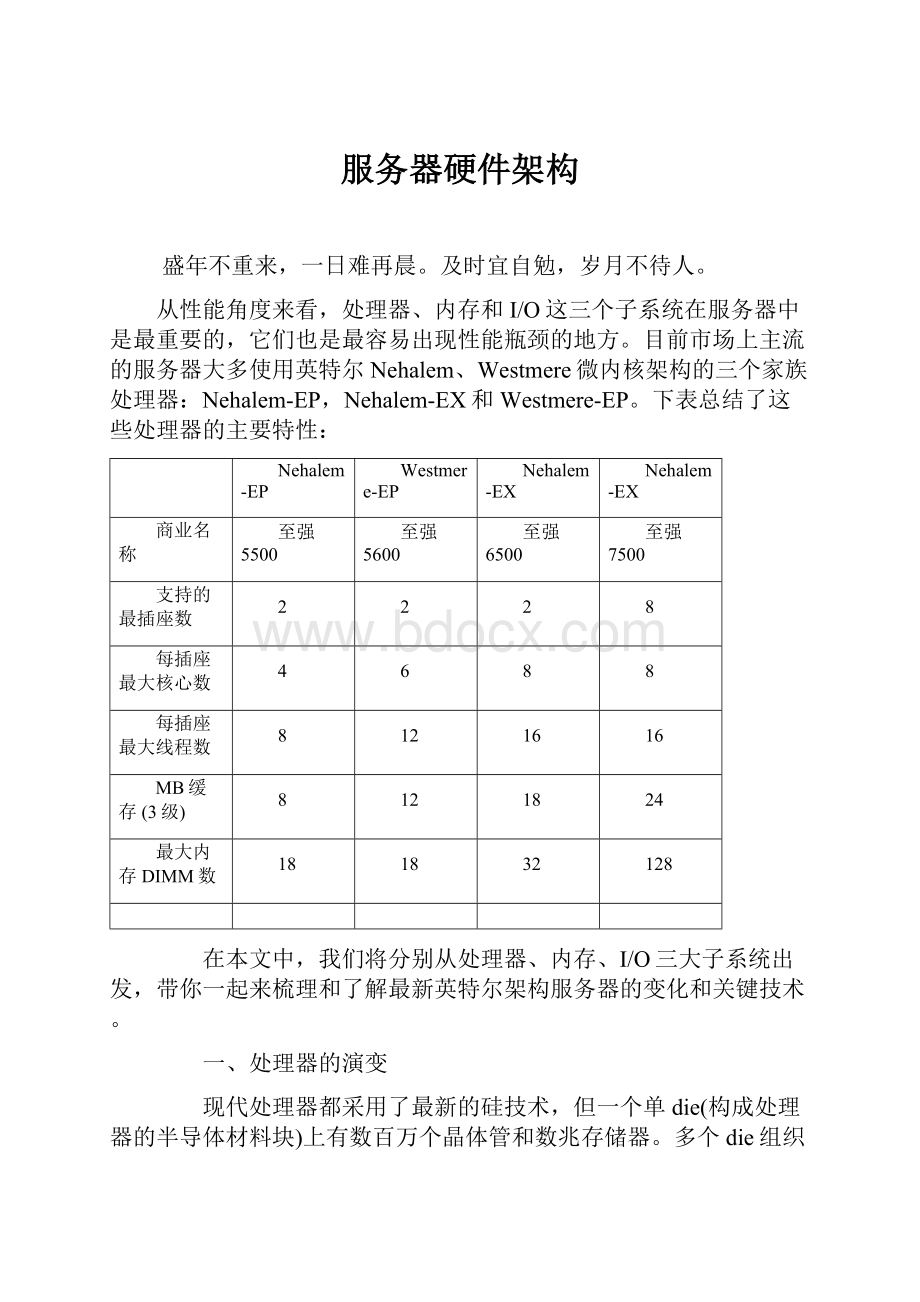
从性能角度来看,处理器、内存和I/O这三个子系统在服务器中是最重要的,它们也是最容易出现性能瓶颈的地方。
目前市场上主流的服务器大多使用英特尔Nehalem、Westmere微内核架构的三个家族处理器:
Nehalem-EP,Nehalem-EX和Westmere-EP。
下表总结了这些处理器的主要特性:
Nehalem-EP
Westmere-EP
Nehalem-EX
Nehalem-EX
商业名称
至强5500
至强5600
至强6500
至强7500
支持的最插座数
2
2
2
8
每插座最大核心数
4
6
8
8
每插座最大线程数
8
12
16
16
MB缓存(3级)
8
12
18
24
最大内存DIMM数
18
18
32
128
在本文中,我们将分别从处理器、内存、I/O三大子系统出发,带你一起来梳理和了解最新英特尔架构服务器的变化和关键技术。
一、处理器的演变
现代处理器都采用了最新的硅技术,但一个单die(构成处理器的半导体材料块)上有数百万个晶体管和数兆存储器。
多个die组织到一起就形成了一个硅晶片,每个die都是独立切块,测试和用陶瓷封装的,下图显示了封装好的英特尔至强5500处理器外观。
图1英特尔至强5500处理器
插座
处理器是通过插座安装到主板上的,下图显示了一个英特尔处理器插座,用户可根据自己的需要,选择不同时钟频率和功耗的处理器安装到主板上。
图2英特尔处理器插座
主板上插座的数量决定了最多可支持的处理器数量,最初,服务器都只有一个处理器插座,但为了提高服务器的性能,市场上已经出现了包含2,4和8个插座的主板。
在处理器体系结构的演变过程中,很长一段时间,性能的改善都与提高时钟频率紧密相关,时钟频率越高,完成一次计算需要的时间越短,因此性能就越好。
随着时钟频率接近4GHz,处理器材料物理性质方面的原因限制了时钟频率的进一步提高,因此必须找出提高性能的替代方法。
核心
晶体管尺寸不断缩小(Nehalem使用45nm技术,Westmere使用32nm技术),允许在单块die上集成更多晶体管,利用这个优势,可在一块die上多次复制最基本的CPU(核心),因此就诞生了多核处理器。
现在市场上多核处理器已经随处可见,每颗处理器包含多个CPU核心(通常是2,4,6,8个),每个核心都有一级缓存(L1),通常所有的核心会共享二级(L2)、三级缓存(L3)、总线接口和外部连接,下图显示了一个双核心的CPU架构。
图3双核心CPU架构示意图
现代服务器通常提供了多个处理器插座,例如,基于英特尔至强5500系列(Nehalem-EP)的服务器通常包含两个插座,每个插座四个核心,总共可容纳八个核心,而基于英特尔至强7500系列(Nehalem-EX)的服务器通常包含八个插座,每个插座八个核心,总共可容纳64个核心。
下图显示了更详细的双核处理器架构示意图,CPU的主要组件(提取指令,解码和执行)都被复制,但系统总线是公用的。
图4双核处理器的详细架构示意图
线程
为了更好地理解多核架构的含义,我们先看一下程序是如何执行的,服务器会运行一个内核(如Linux,Windows的内核)和多个进程,每个进程可进一步细分为线程,线程是分配给核心的最小工作单元,一个线程需要在一个核心上执行,不能进一步分割到多个核心上执行。
下图显示了进程和线程的关系。
图5进程和线程的关系
进程可以是单线程也可以是多线程的,单线程进程同一时间只能在一个核心上执行,其性能取决于核心本身,而多线程进程同一时间可在多个核心上执行,因此它的性能就超越了单一核心上的性能表现。
因为许多应用程序都是单线程的,在多进程环境中,多插座、多核心的架构通常会带来方便,在虚拟化环境中,这个道理一样正确,Hypervisor允许在一台物理服务器上整合多个逻辑服务器,创建一个多进程和多线程的环境。
英特尔超线程技术
虽然单线程不能再拆分到两个核心上运行,但有些现代处理器允许同一时间在同一核心上运行两个线程,每个核心有多个并行工作能力的执行单元,很难看到单个线程会让所有资源繁忙起来。
下图展示了英特尔超线程技术是如何工作的,同一时间在同一核心上有两个线程执行,它们使用不同的资源,因此提高了吞吐量。
图6英特尔超线程技术工作原理
前端总线
在多插座和多核心的情况下,理解如何访问内存和两个核心之间是如何通信的非常重要,下图显示了过去许多英特尔处理器使用的架构,被称作前端总线(FSB)架构。
在FSB架构中,所有通信都是通过一个单一的,共享的双向总线发送的。
在现代处理器中,64位宽的总线以4倍速总线时钟速度运行,在某些产品中,FSB信息传输速率已经达到1.6GT/s。
图7基于前端总线的服务器平台架构
FSB将所有处理器连接到芯片组的叫做北桥(也叫做内存控制器中枢),北桥连接所有处理器共享访问的内存。
这种架构的优点是,每个处理器都可以访问其它所有处理可以访问的所有内存,每个处理器都实现了缓存一致性算法,保证它的内部缓存与外部存储器,以及其它所有处理器的缓存同步。
但这种方法设计的平台要争夺共享的总线资源,随着总线上信号传输速度的上升,要连接新设备就变得越来越困难了,此外,随着处理器和芯片组性能的提升,FSB上的通信流量也会上升,会导致FSB变得拥挤不堪,成为瓶颈。
双独立总线
为了进一步提高带宽,单一共享总线演变成了双独立总线架构(DIB),其架构如下图所示,带宽基本上提高了一倍。
图8基于双独立总线的服务器平台架构
但在双独立总线架构中,缓存一致性通信必须广播到两条总线上,因此减少了总有效带宽,为了减轻这个问题,在芯片组中引入了“探听过滤器”来减少带宽负载。
如果缓存未被击中,最初的处理器会向FSB发出一个探听命令,探听过滤器拦截探听,确定是否需要传递探听给其它FSB。
如果相同FSB上的其它处理器能满足读请求,探听过滤器访问就被取消,如果相同FSB上其它处理器不满意读请求,探听过滤器就会确定下一步的行动。
如果读请求忽略了探听过滤器,数据就直接从内存返回,如果探听过滤器表示请求的目标缓存在其它FSB上不存在,它将向其它部分反映探听情况。
如果其它部分仍然有缓存,就会将请求路由到该FSB,如果其它部分不再有目标缓存,数据还是直接从内存返回,因为协议不支持写请求,写请求必须全部传播到有缓存副本的所有FSB上。
专用高速互联
在双独立总线之后又出现了专用高速互联架构(DedicatedHigh-SpeedInterconnect,DHSI),其架构如下图所示。
图9基于DHSI的服务器平台架构
基于DHSI的平台使用四个独立的FSB,每个处理器使用一个FSB,引入探听过滤器实现了更好的带宽扩容,FSB本身没多大变化,只是现在变成点对点的配置了。
使用这种架构设计的平台仍然要处理快速FSB上的电信号挑战,DHSI也增加了芯片组上的针脚数量,需要扩展PCB路线,才能为所有FSB建立好连接。
英特尔QuickPath互联
随英特尔酷睿i7处理器引入了一种新的系统架构,即著名的英特尔QuickPath互联(QuickPathInterconnect,QPI),这个架构使用了多个高速单向连接将处理器和芯片组互联,使用这种架构使我们认识到了:
①.多插座和多核心通用的内存控制器是一个瓶颈;
②.引入多个分布式内存控制器将最符合多核处理器的内存需要;
③.在大多数情况下,在处理器中集成内存控制器有助于提升性能;
④.提供有效的方法处理多插座系统一致性问题对大规模系统是至关重要的。
下图显示了一个多核处理器,集成了内存控制器和多个连接到其它系统资源的英特尔QuickPath的功能示意图。
图10集成英特尔QPI和DDR3内存通道的处理器架构
在这个架构中,每个插座中的所有核心共享一个可能有多个内存接口的IMC(IntegratedMemoryControllers,集成内存控制器)。
IMC可能有不同的外部连接:
①.DDR3内存通道–在这种情况下,DDR3DIMM直接连接到插座,如下图所示,Nehalem-EP(至强5500)和Westmere-EP(至强5600)就使用了这种架构。
图11具有高速内存通道的处理器
②.高速串行内存通道–如下图所示,在这种情况下,外部芯片(SMB:
ScalableMemoryBuffer,可扩展内存缓存)创建DDR3内存通道,DDR3DIMM通过这个通道连接,Nehalem-EX使用了这种架构。
图12四插座Nehalem-EX
IMC和插座中的不同核心使用英特尔QPI相互通信,实现了英特尔QPI的处理器也可以完全访问其它处理器的内存,同时保持缓存的一致性,这个架构也叫做“缓存一致性NUMA(Non-UniformMemoryArchitecture非统一内存架构)”,内存互联系统保证内存和所有潜在的缓存副本总是一致的。
英特尔QPI是一个端到端互联和消息传递方案,在目前的实现中,每个连接由最高速度可达25.6GB/s或6.4GT/s的20条线路组成。
英特尔QPI使用端到端连接,因此在插座中需要一个内部交叉路由器,提供全局内存访问,通过它,不需要完整的连接拓扑就可以构建起系统了。
图12显示了四插座Nehalem-EX配置,每个处理器有四个QPI与其它三个处理器和Boxboro-EX芯片组互联。
二、内存子系统
电子业在内存子系统上付出了艰辛的努力,只为紧跟现代处理器需要的低访问时间和满足当今应用程序要求的高容量需求。
解释当前内存子系统之前,我们先了解一下与内存有关的一些常用术语。
①.RAM(随机访问存储器)
②.SRAM(静态RAM)
③.DRAM(动态RAM)
④.SDRAM(同步DRAM)
⑤.SIMM(单列直插式内存模块)
⑥.DIMM(双列直插内存模块)
⑦.UDIMM(无缓冲DIMM)
⑧.RDIMM(带寄存器的DIMM)
⑨.DDR(双数据速率SDRAM)
⑩.DDR2(第二代DDR)
⑩.DDR3(第三代DDR)
电子器件工程联合委员会(JointElectronDeviceEngineeringCouncil,JEDEC)是半导体工程标准化机构,JEDEC21,22定义了从256位SRAM到最新的DDR3模组的半导体存储器标准。
现代服务器的内存子系统是由RAM组成的,允许数据在一个固定的时间按任意顺序访问,不用考虑它所在的物理位置,RAM可以是静态的或动态的。
SRAM
SRAM(静态RAM)通常非常快,但比DRAM的容量要小,它们有一块芯片结构维持信息,但它们不够大,因此不能作为服务器的主要内存。
DRAM
DRAM(动态RAM)是服务器的唯一选择,术语“动态”表示信息是存储在集成电路的电容器内的,由于电容器会自动放电,为避免数据丢失,需要定期充电,内存控制器通常负责充电操作。
SDRAM
SDRAM(同步DRAM)是最常用的DRAM,SDRAM具有同步接口,它们的操作与时钟信号保持同步,时钟用于驱动流水线内存访问的内部有限状态机,流水线意味着上一个访问未结束前,芯片可以接收一个新的内存访问,与传统DRAM相比,这种方法大大提高了SDRAM的性能。
DDR2和DDR3是两个最常用的SDRAM,下图显示了一块DRAM芯片的内部结构。
图13DRAM芯片的内部结构
内存阵列是由存储单元按矩阵方式组织组成的,每个单元都一个行和列地址,每一位都是存储在电容器中的。
为了提高性能,降低功耗,内存阵列被分割成多个“内存库(bank)”,下图显示了一个4-bank和一个8-bank的内存阵列组织方式。
图14内存bank
DDR2芯片有四个内部内存bank,DDR3芯片有八个内部内存bank。
DIMM
需要将多个内存芯片组装到一起才能构成一个内存子系统,它们就是按著名的DIMM(双列直插内存模块)组织的。
下图显示了内存子系统的传统组织方式,例如,内存控制器连接四个DIMM,每一个由多块DRAM芯片组成,内存控制器有一个地址总线,一个数据总线和一个命令(也叫做控制)总线,它负责读,写和刷新存储在DIMM中的信息。
图15传统内存子系统示例
下图展示了一个内存控制器与一个DDR3DIMM连接的示例,该DIMM由八块DRAM芯片组成,每一块有8位数据存储能力,每存储字(内存数据总线的宽度)则共有64位数据存储能力。
地址总线有15位,它可在不同时间运送“行地址”或“列地址”,总共有30个地址位。
此外,在DDR3芯片中,3位的bank地址允许访问8个bank,可被视作提高了控制器的地址空间总容量,但即使内存控制器有这样的地址容量,市面上DDR3芯片容量还是很小。
最后,RAS(RowAddressSelection,行地址选择),CAS(ColumnAddressSelection,列地址选择),WE(WriteEnabled,写启用)等都是命令总线上的。
图16DDR3内存控制器示例
下面是一个DIMM的示意图。
图17DIMM示意图
上图显示了8个DDR3芯片,每个提供了8位信息(通常表示为x8)。
ECC和Chipkill
数据完整性是服务器架构最关注的一个点,很多时候需要安装额外的DIMM检测和恢复内存错误,最常见的办法是增加8位ECC(纠错码),将存储字从64位扩大到72位,就象海明码一样,允许纠正一位错误,检测两位错误,它们也被称作SEC(SingleErrorCorrection,单纠错)/DED(DoubleErrorDetection,双检错)。
先组织存储字再写入到内存芯片中,EEC可以用于保护任一内存芯片的失效,以及单内存芯片的任意多位错误,这些功能有几个不同的名字。
①.Chipkill是IBM的商标
②.Oracle称之为扩展EEC
③.惠普称之为Chipspare
④.英特尔有一个类似的功能叫做x4单设备数据校正(Intelx4SDDC)
Chipkill通过跨多个内存芯片位散射EEC字的位实现这个功能,任一内存芯片失效只会影响到一个ECC位,它允许重建内存中的内容。
下图了显示了一个读和写128位数据的内存控制器,增加EEC后就变成144位了,144位分成4个36位的存储字,每个存储字将是SEC/DED。
如果使用两个DIMM,每个包含18个4位芯片,可以按照下图所示的方法重组位,如果芯片失效,每4个字中只会有一个错误,但因为字是SEC/DED的,每4个字可以纠正一个错误,因此所有错误都可以被纠正过来。
图18Chipkill示例
内存Rank
我们重新回到DIMM是如何组织的,一组产生64位有用数据(不计ECC)的芯片叫做一个Rank,为了在DIMM上存储更多的数据,可以安装多个Rank,目前有单,双和四个Rank的DIMM,下图显示了这三种组织方法。
图19DIMM和内存排
上图最前面显示的是一个单Rank的RAM,由9个8位芯片组成,一般表示为1Rx8,中间显示的是一个1Rx4,由18个4位芯片组成,最后显示的是一个2Rx8,由18个8位芯片组成。
内存Rank不能使用地址位选择,只能使用芯片选择,现代内存控制器最多可达8个独立的芯片选择,因此最大可支持8个Rank。
UDIMM和RDIMM
SDRAMDIMM进一步细分为UDIMM(无缓冲DIMM)和RDIMM(带寄存器的DIMM),在UDIMM中,内存芯片直接连接到地址总线和控制总线,无任何中间部分。
RDIMM在传入地址和控制总线,以及SDRAM之间有额外的组件(寄存器),这些寄存器增加了一个延迟时钟周期,但它们减少了内存控制器上的电负荷,允许内存控制器安装更多的DIMM。
RDIMM通常更贵,因为它需要附加组件,但它们在服务器中得到了普遍使用,因为对于服务器来说,扩展能力和稳定性比价格更重要。
虽然理论上带寄存器/无缓冲的和ECC/非ECCDIMM是可以任何组合的,但大多数服务器级内存模块都同时具有ECC和带寄存器功能。
下图显示了一个ECCRDIMM,寄存器是箭头指向的芯片,这个ECCDIMM由9个内存芯片组成。
图20ECCRDIMM
DDR2和DDR3
第一代SDRAM技术叫做SDR(SingleDataRate),表示每个时钟周期传输一个数据单元,之后又出现了DDR(DoubleDataRate)标准,其带宽几乎是SDR的两倍,无需提高时钟频率,可在时钟上升沿和下降沿信号上同时传输数据,DDR技术发展到今天形成了两套标准:
DDR2和DDR3。
DDR2SDRAM的工作电压是1.8V,采用240针DIMM模块封装,通过改善总线信号,它们可以以两倍于DDR的速度工作在外部数据总线上,规则是:
①.每DRAM时钟数据传输两次
②.每次数据传输8个字节(64位)
下表显示了DDR2标准。
表2.DDR2DIMM
标准名称
DRAM时钟频率
每秒传输的数据(百万)
模块名称
峰值传输速率GB/s
DDR2-400
200MHz
400
PC2-3200
3.200
DDR2-533
266MHz
533
PC2-4200
4.266
DDR2-667
333MHz
667
PC2-5300 PC2-5400
5.333
DDR2-800
400MHz
800
PC2-6400
6.400
DDR2-1066
533MHz
1,066
PC2-8500 ©PC2-8600
8.533
DDR3SDRAM在DDR2的基础上对以下这些方面做了改进:
①.将工作电压降低到1.5v,减少功耗;
②.通过引入0.5-8Gb的芯片增加了内存密度,单Rank的容量最大可达16GB;
③.增加了内存带宽,内存突发长度从4字增加到8字,增加突发长度是为了更好地满足不断增长的外部数据传输速率,随着传输速率的增长,突发长度(传输的大小)必须增长,但不能超出DRAM核心的访问速度。
DDR3DIMM有240针,数量和尺寸都和DDR2一样,但它们在电气特性上是不兼容的,缺口位置不一样,未来,DDR3将工作在更快的时钟频率,目前,市面上存在DDR3-800,1066和1333三种类型。
下表对不同的DDR3DIMM模块进行了总结。
表3.DDR3DIMM
标准名称
RAM时钟频率
每秒传输的数据(百万)
模块名称
峰值传输速率GB/s
DDR3-800
400MHz
800
PC3-6400
6.400
DDR3-1066
533MHz
1,066
PC3-8500
8.533
DDR3-1333
667MHz
1,333
PC3-10600
10.667
DDR3-1600
800MHz
1,600
PC3-12800
12.800
DDR3-1866
933MHz
1,866
PC3-14900
14.900
三、I/O子系统
I/O子系统负责在服务器内存和外部世界之间搬运数据,传统上,它是通过服务器主板上兼容PCI标准的I/O总线实现的,开发PCI的目的就是让计算机系统的外围设备实现互联,PCI的历史非常悠久,现在最新的进化版叫做PCI-Express。
外围组件互联特殊兴趣小组(PeripheralComponentInterconnectSpecialInterestGroup,PCI-SIG)负责开发和增强PCI标准。
PCIExpress
PCIExpress(PCIe)是一个计算机扩展接口卡格式,旨在替代PCI,PCI-X和AGP。
它消除了整个所有I/O引起的限制,如服务器总线缺少I/O带宽,目前所有的操作系统都支持PCIExpress。
上一代基于总线拓扑的PCI和PCI-X已经被点到点连接取代,由此产生的拓扑结构是一个单根联合体的树形结构,根联合体负责系统配置,枚举PCIe资源,管理中断和PCIe树的错误。
根联合体和它的端点共享一个地址空间,通过内存读写和中断进行通信。
PCIe使用点到点链接连接两个组件,链接由N个通道组成,每个通道包含两对电路,一对用于传输,另一对用于接收。
南桥(也叫做ICH:
I/OControllerHub)通常会提供多个PCIe通道实现根联合体的功能。
每个通道连接到一个PCIExpress端点,一个PCIExpressSwitch,一个PCIe或一个PCIe桥,如下图所示。
图21PCIExpress根联合体
根据通道编号使用不同的连接器,下图显示了四个不同的连接器,及单/双向时的速度。
图22PCIExpress连接器
在PCIe1.1中,通道运行在2.5Gbps,可同时部署16条通道,如下图所示,可支持的速度从2Gbps(1x)到32Gbps(16x),由于协议开销,支持10GE接口需要8x。
图23PCIExpress通道
PCIe2.0(也叫第二代PCIe)带宽提升了一倍,从2Gbit/s提高到4Gbit/s,通道数量也扩大到了32x,PCIe4x就足以支持10GE了。
PCIe3.0将会再增加一倍带宽,最终的PCIe3.0规范预计会在2010年年中发布,到2011年就可看到支持PCIe3.0的产品,PCIe3.0能有效地支持40GE(下一代以太网标准)。
目前所有的PCIExpress产品都是单根的(SingleRoot,SR),如控制多个端点的单I/O控制器中枢(ICH)。
多根(MultiRoot,MR)也发展了一段时间,但目前还未见到曙光,由于缺少元件和关注,目前还有诸多问题。
SR-IOV(SingleRootI/OVirtualization,单根I/O虚拟化)是PCI-SIG开发的另一个相关标准,主要用于连接虚拟机和Hypervisor。
四、英特尔微架构
英特尔Nehalem和Westmere微架构,也被称为32和45nm酷睿微架构。
Nehalem微架构于2009年初引入了服务器,也是第一个使用45nm硅技术的架构,Nehalem处理器可应用于高端桌面应用程序,超大规模服务器平台等,代号名来源于美国俄勒冈州的Nehalem河。
根据英特尔的说法,处理器的发展速度就象嘀嗒(TickandTock)钟声的节奏一样,如下图所示,Tick是对现有处理器架构进行缩小,而Tock则是在前一代技术上发展起来的全新架构,Nehalem就是45nm的Tock,Westmere就是紧跟Nehalem的32nmTick。
图24英
 升级会员
升级会员 