HuffMan课程设计报告.docx
《HuffMan课程设计报告.docx》由会员分享,可在线阅读,更多相关《HuffMan课程设计报告.docx(15页珍藏版)》请在冰豆网上搜索。
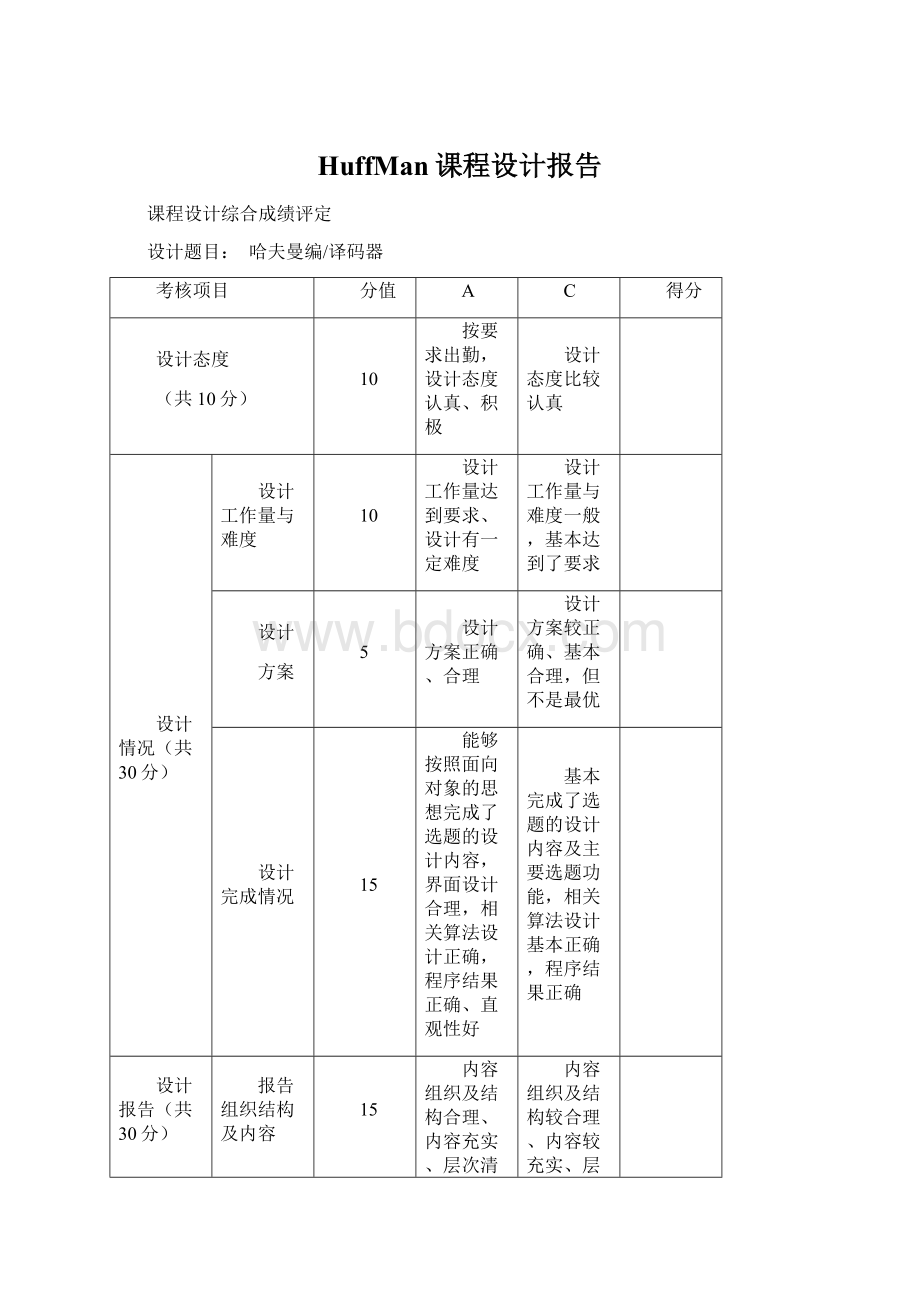
HuffMan课程设计报告
课程设计综合成绩评定
设计题目:
哈夫曼编/译码器
考核项目
分值
A
C
得分
设计态度
(共10分)
10
按要求出勤,设计态度认真、积极
设计态度比较认真
设计情况(共30分)
设计工作量与难度
10
设计工作量达到要求、设计有一定难度
设计工作量与难度一般,基本达到了要求
设计
方案
5
设计方案正确、合理
设计方案较正确、基本合理,但不是最优
设计完成情况
15
能够按照面向对象的思想完成了选题的设计内容,界面设计合理,相关算法设计正确,程序结果正确、直观性好
基本完成了选题的设计内容及主要选题功能,相关算法设计基本正确,程序结果正确
设计报告(共30分)
报告组织结构及内容
15
内容组织及结构合理、内容充实、层次清晰、图表得当
内容组织及结构较合理、内容较充实、层次较清晰、图表应用基本得当
报告排版格式
15
格式规范,完全符合要求
格式基本规范,基本符合要求
答辩情况
(共30分)
30
答辩思路清晰,问题回答准确
问题基本回答准确
综合得分
其它说明:
目录
一、问题描述1
二、概要设计2
2.1界面设计2
2.2算法设计3
三、详细设计4
四、程序运行说明与结果9
五、总结与分析13
一、问题描述
电文编码:
假如有一份电文中有若干个字符,以每个字符出现的频度作为叶子结点的权值创建对应的哈夫曼树(权值最小的作为左子树,次小的作为右子树),并输出每个字符对应的哈夫曼编码。
1.程序的输入
(1)若干字符(代表电文)
2.程序的输出
(1)每个字符对应的哈夫曼编码
(2)每个字符对应的权值
(3)电文经过编码后的二进制代码
电文译码:
给出一段二进制代码的电文,要求根据前面构造的哈夫曼树进行译码。
在前面编码的基础上,键盘输入一段电文,则能在屏幕上显示出自动翻译好的电文。
1.程序的输入
(1)由0和1组成的二进制代码(代表电文)
2.程序的输出
(1)每个字符对应的哈夫曼编码
(2)每个字符对应的权值
(3)电文经过译码后的译码结果
二、概要设计
2.1界面设计
图1哈夫曼编/译码器界面
哈夫曼编/译码器分为显示区域、输入区域和按钮区域三个部分。
显示区域分别显示字符编码、字符权值和编码结果。
输入区域输入若干字符(电文)。
按钮区域包括自动获取权值、保存字符权值、打开编码文件、保存编码内容、保存编码结果和开始编码按钮。
对应控件属性如表1所示。
表1主界面控件属性
控件(Name)
属性
属性新值
richTextBoxScan
Text
输入编/译码内容
richTextBoxPrint
Text
输出编/译码结果
richTextBoxPrintCode
Text
输出字符编码
richTextBoxSetWeight
Text
输出字符权值
labelScan
Text
请输入要编/译码的内容:
labelPrint
Text
编/译码结果为:
续表
控件(Name)
属性
属性新值
labelPrintCode
Text
字符编码为:
labelPrintWeight
Text
字符权值为:
buttonSetWeight
Text
自动获取权值
buttonSaveWeight
Text
保存字符权值
buttonOpen
Text
打开编/译码文件
buttonSaveText
Text
保存编/译码内容
buttonSave
Text
保存编/译码结果
buttonTra
Text
开始编/译码
checkBoxEnCode
Text
编码
checkBoxDeCode
Text
译码
2.2算法设计
在此程序算法设计中,核心算法为哈夫曼树的构造算法与哈夫曼编码算法。
在哈夫曼树的构造算法中,需要定义哈夫曼树的存储类型,需要根据结点数量以及权值构建哈夫曼树。
在哈夫曼编码算法中,需从每个叶子结点访问至根节点,并记录访问路径(0或1)。
1.LeafNode类中定义了叶子结点的权值(weight),双亲结点(parent),左孩子结点(lChild),右孩子结点(rChild),以及叶子结点的名字(nameStr)。
此类中还有一个无参构造方法(LeafNode()),用于对叶子结点进行初始化操作。
2.CreateHuffmananTree类含无参构造器(CreateHuffmananTree()),用以对所有叶子结点进行初始化操作。
类中还包含一个方法(Creat()),可以根据所有叶子结点的权值构造哈夫曼树。
3.GetHuffmanCode类中有GetHuffCode(),GetNameStr()两个方法。
GetHuffCode()用来获取哈夫曼编码,GetNameStr()用于实现将二进制代码解译为字符(电文)。
4.EnCodeAndDeCode类中两个方法,GetCode()方法和DeCode()方法。
GedCode()方法中创建CreateHuffmanTree类的对象,实现创建哈夫曼树,并对字符进行编码。
DeCode()方法中创建CreateHuffmanTree类的对象,实现创建哈夫曼树,并解译二进制代码。
三、详细设计
1.LeafNode类(定义叶子结点类型)
publicclassLeafNode
{
publicintweight;//用来存储叶子结点的权值
publicintlChild;//存储左孩子的数组编号
publicintrChild;//用来存储右孩子的数组编号
publicintparents;//用来存储双亲的数组编号
publicstringnameStr;//用来存储叶子结点的信息
//无参构造器
publicLeafNode()
{
weight=-1;
lChild=-1;
rChild=-1;
parents=-1;
nameStr=null;
}
}
2.CreateHuffmanTree类(构建哈夫曼树算法)
publicclassCreateHuffmanTree
{
publicstaticLeafNode[]leaf;//结点以数组形式存放
publicstaticintleafNum;//叶子结点数目
//构造器
publicCreateHuffmanTree()
{
StreamReaderreader=newStreamReader("SetWeight.txt",Encoding.Default);//读取文件流
for(leafNum=0;!
reader.EndOfStream;)
{
if(reader.ReadLine().Trim()!
="")leafNum++;
}
reader.Close();
leaf=newLeafNode[2*leafNum-1];
for(inti=0;i<2*leafNum-1;i++)
{
leaf[i]=newLeafNode();//初始化全部叶结点
}
}
//创建huffmantree,用creat()方法
publicvoidCreat()
{
inttmp1;//用来存放未加入树的结点的权值
inttmp2;//判定tmp1是否已经被赋值
intmin1;
intmin2;//用来存放权值最小的两个结点
//输入n个叶子结点的权值和储存的信息
string[]str;
StreamReaderreader=newStreamReader("SetWeight.txt");//读取文件流
for(inti=0;i{
str=reader.ReadLine().Split('=');//以“=”为标志将一行字符串分割成左右两部分字符串,如果不是这个格式的信息将会抛出异常,被catch捕获
leaf[i].weight=int.Parse(str[1]);//“=”右边的部分转成整形收入到叶子结点的权值
leaf[i].nameStr=str[0];//"="左边的部分依然保持string类型作为叶子结点的信息存储
}
reader.Close();//关闭读入流
for(inti=0;i{
tmp1=tmp2=int.MaxValue;
min1=min2=0;//在全部结点中找权值最小的两个结点
for(intj=0;j{
if(leaf[j].parents==-1)
{
if(leaf[j].weight{
tmp2=leaf[j].weight;
min2=j;
if(tmp2{
intswap=tmp2;
tmp2=tmp1;
tmp1=swap;
swap=min2;
min2=min1;
min1=swap;
}
}
}
}
leaf[min1].parents=leafNum+i;
leaf[leafNum+i].weight=leaf[min1].weight+leaf[min2].weight;
leaf[leafNum+i].lChild=min1;
leaf[leafNum+i].rChild=min2;
leaf[min2].parents=leafNum+i;
}
}
}
3.GetHuffmanCode类(获取哈夫曼编码)
publicclassGetHuffmanCode
{
publicstaticstringcode;//code用来存储编码
publicstaticintcodeTmp;//这个用来存储0/1临时编码的
publicstaticstring[]PrintCode;
publicstaticinti,j;
publicstaticvoidGetHuffCode(stringtoBeTran)//获取哈夫曼编码
{
StackcodeStack=newStack();//利用栈的先进后出反转代码
for(i=0;i{
if(toBeTran==CreateHuffmanTree.leaf[i].nameStr)//如果传入的字符和叶子结点的字符信息相同,回溯法找代码
{
j=CreateHuffmanTree.leaf[i].parents;
break;
}
}
if(i==CreateHuffmanTree.leafNum)
{
GetHuffmanCode.code=toBeTran;
}
if(j==-1)//只存在一个叶子结点
{
codeTmp=0;
codeStack.Push(codeTmp.ToString());
}
while(j!
=-1)//直到根节点(parent属性为-1)时跳出循环
{
if(CreateHuffmanTree.leaf[j].lChild==i)codeTmp=0;
elseif(CreateHuffmanTree.leaf[j].rChild==i)codeTmp=1;//左0右1
codeStack.Push(codeTmp.ToString());
i=j;
j=CreateHuffmanTree.leaf[i].parents;
}//代码全部入栈
while(codeStack.Count!
=0)//代码全部弹出栈,实现反序
{
code+=codeStack.Pop();
}
}
publicstaticvoidGetNameStr(intnameCode)//解译哈夫曼编码
{
//根节点一定是leaf[2*leafNum-2],即最后一个数组
if(nameCode==0)
{
i=CreateHuffmanTree.leaf[i].lChild;
if(CreateHuffmanTree.leaf[i].lChild==-1)
{
code+=CreateHuffmanTree.leaf[i].nameStr;
i=2*CreateHuffmanTree.leafNum-2;
}
}
elseif(nameCode==1)
{
i=CreateHuffmanTree.leaf[i].rChild;
if(CreateHuffmanTree.leaf[i].lChild==-1)
{
code+=CreateHuffmanTree.leaf[i].nameStr;
i=2*CreateHuffmanTree.leafNum-2;
}
}
}
}
4.EnCodeAndDeCode类(编/译字符)
publicclassEnCodeAndDeCode
{
publicstaticstringcodeFile;//最终用来存放代码串的
//publicstaticstringcodeFile2;
publicstaticvoidGetCode()
{
CreateHuffmanTreehuff=newCreateHuffmanTree();
huff.Creat();
char[]toBeTranText=HuffManTra.CodeInfo.ToCharArray();
try//在这里抛出异常是为了防止大面积出现编码错误是反复弹出出错提示窗口,这里只弹出第一个出错信息提示
{
for(inti=0;i{
GetHuffmanCode.GetHuffCode(toBeTranText[i].ToString());
codeFile+=GetHuffmanCode.code;
GetHuffmanCode.code=null;
}
}
catch(IndexOutOfRangeException)
{
codeFile=null;
GetHuffmanCode.code=null;
}
}
publicstaticvoidDeCode()
{
CreateHuffmanTreehuff=newCreateHuffmanTree();
huff.Creat();
GetHuffmanCode.i=2*CreateHuffmanTree.leafNum-2;
char[]tmpChar;
tmpChar=HuffManTra.CodeInfo.ToCharArray();
for(inti=0;i{
GetHuffmanCode.GetNameStr(tmpChar[i]-48);
}
codeFile=GetHuffmanCode.code;
GetHuffmanCode.code=null;
}
}
四、程序运行说明与结果
运行程序,首先进入主界面(如上文图1所示)。
若进行电文编码,首先选中“编码”,然后在“请输入要编码的内容”下的richTextBox控件内输入内容(如图2所示),或者点击“打开编码文件”按钮,选择txt文件。
图2输入编码内容
点击“自动获取权值”按钮,获取字符编码与字符权值(如图3所示)。
图3自动获取权值
点击“开始编码”按钮,显示编译结果(如图4所示)。
图4编译结果
此时,电文编码成功。
可以点击“保存字符权值”按钮,保存字符权值信息,可以点击“保存编码内容”按钮,保存编码内容,也可以点击“保存编码结果”按钮,保存编码结果。
若要进行电文译码,首先选中“译码”,并输入二进制代码(如图5所示),或者点击“打开译码文件”按钮,打开txt文件。
图5输入译码内容
点击“自动获取权值”按钮,弹出“设置权值”窗体(如图6所示)。
图6设置权值
此时,窗体中显示的是上一次进行编码时的权值信息。
若使用此权值,则直接退出即可。
若不使用此权值,可打开“文件”菜单中的“打开文件”选项,选择其它权值txt文件,并点击“文件”菜单中的“保存”按钮,退
出即可。
这里我们选择直接退出,然后就会显示出字符编码与字符权值信息。
图7显示字符编码与权值
点击“开始译码”按钮,显示编译结果(如图8所示)。
图8译码结果
五、总结与分析
本程序是由C#编写的标准Windows窗体应用程序,是结合数据结构与Windows窗体的综合设计。
数据结构设计中包含哈夫曼树的建立,以及对哈夫曼树中每个叶子结点的遍历,并用静态链表实现哈夫曼树的存储。
在获取字符(电文)对应的编码时,利用栈的后进先出(FIFO)特性,将得到的编码反序后输出。
本程序中包含对字符(电文)的编码和对二进制串的译码,同时可显示编译时的字符权值、字符编码、编译结果。
本程序存在一些不足,将不能对中文字符或某些特殊字符进行编码。
编译时会出现错误提示,提醒使用者进行修改输入内容,以便于正确编译。
 升级会员
升级会员 