语法分析器设计.docx
《语法分析器设计.docx》由会员分享,可在线阅读,更多相关《语法分析器设计.docx(18页珍藏版)》请在冰豆网上搜索。
语法分析器设计
1.2语法分析器设计
语法分析是编译程序的核心部分,其主要任务是确定语法结构,检查语法错误,报告错误的性质和位置,并进行适当的纠错工作.法分析的方法有多种多样,常用的方法有递归子程序方法、运算符优先数法、状态矩阵法、LL(K)方法和LR(K)方法。
归纳起来,大体上可分为两大类,即自顶向下分析方法和自底向上分析方法.Syntax进行语法分析.对于语法分析,这里采用LR
(1)分析法,判断程序是否满足规定的结构.构造LR
(1)分析程序,利用它进行语法分析,判断给出的符号串是否为该文法识别的句子,了解LR(K)分析方法是严格的从左向右扫描,和自底向上的语法分析方法。
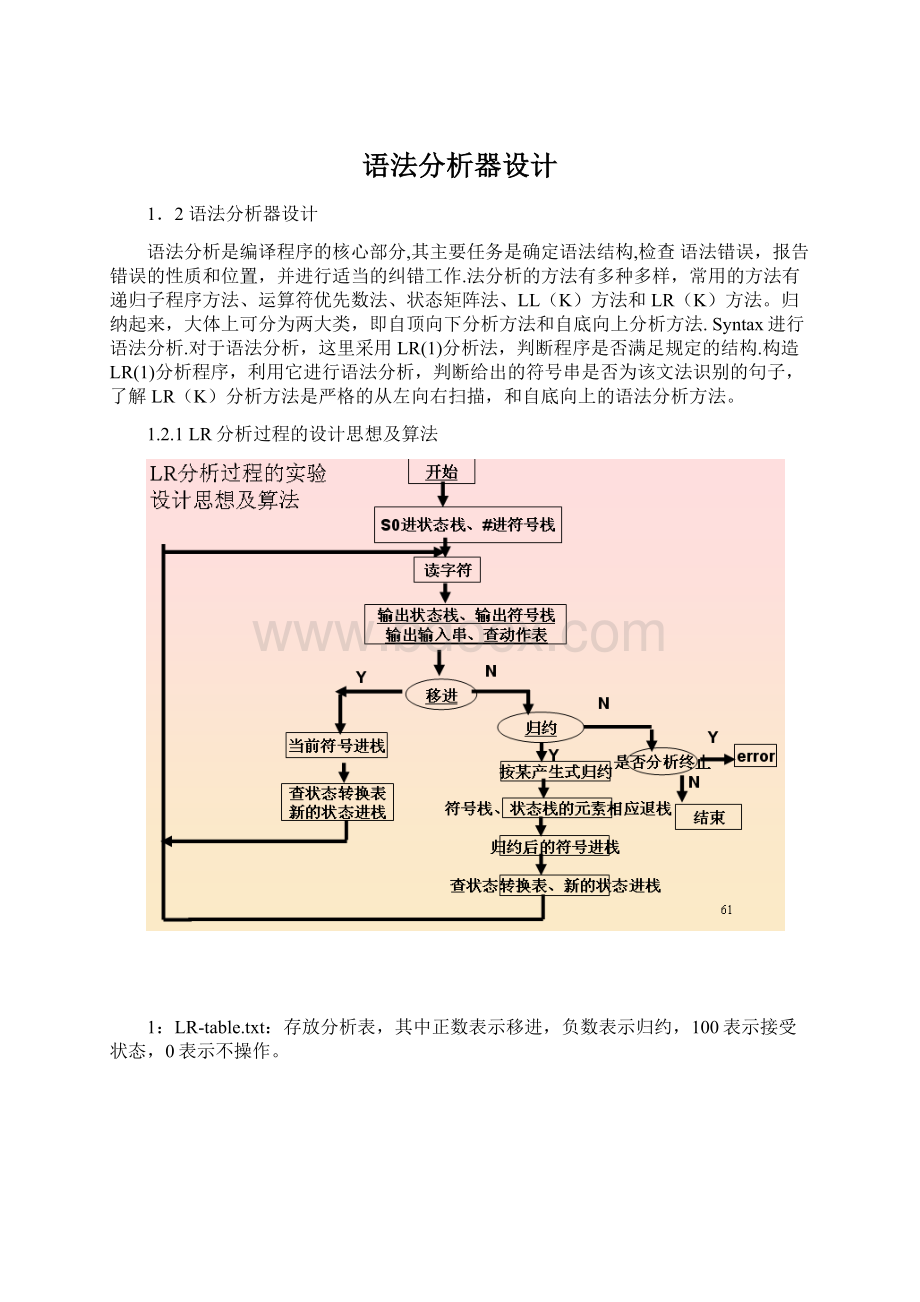
1.2.1LR分析过程的设计思想及算法
1:
LR-table.txt:
存放分析表,其中正数表示移进,负数表示归约,100表示接受状态,0表示不操作。
2:
grammar.txt存放文法开始符号
3:
lengh.txt存放产生式右部字符长度
4:
inpur.txt输入的程序
语法规则
定义的文法,如下:
(1)Z---S
(2)S---AB
(3)A---->CDE
(4)C---void
(5)D---main
(6)E---()
(7)B---{F}
(8)F---GF
(9)F---G
(10)G--->HIJ
(11)H--int
(12)I--KLM
(13)K--character
(14)L--=
(15)M--->num
(16)J--;
根据上面文法画出的分层有限自动机并根据分层自动机构造的LR
(1)分析表:
void
main
()
{
int
char
=
num
S
A
B
C
D
E
F
G
H
I
J
K
L
M
}
;
#
0
2
1
8
3
1
Ac
2
-3
3
4
5
4
-4
5
6
7
6
-5
7
-2
8
10
9
9
-1
10
25
11
13
15
11
12
12
-6
13
25
14
13
15
-8
14
-7
15
16
17
20
16
-12
17
19
18
18
-15
-15
19
-9
-9
20
21
22
21
-13
22
23
24
23
24
-14
25
-11
1.2.2程序核心代码和注释:
publicvoidanalyzer()
{
//***************************
//循环读取grammar.txt
//***************************
/*此处代码略*/
//***************************
//循环读取lengh.txt
//***************************
/*此处代码略*/
//****************************
//读入文件,进行语法分析
//****************************
stringstrReadFile;
strReadFile="input.txt";
myTextRead.myStreamReader=newStreamReader(strReadFile);
stringstrBufferText;
intwid=0;
Console.WriteLine("分析读入程序(记号ID):
\n");
do
{
strBufferText=myTextRead.myStreamReader.ReadLine();
if(strBufferText==null)
break;
foreach(StringsubStringinstrBufferText.Split())
{
if(subString!
="")
{
intll;
if(subString!
=null)
{
ll=subString.Length;//每一个长度
}
else
{
break;
}
inta=ll+1;
char[]b=newchar[a];
StringReadersr=newStringReader(subString);
sr.Read(b,0,ll);//把substring读到char[]数组里
intsort=(int)b[0];
//word[i]和wordNum[i]对应
//先识别出一整个串,再根据开头识别是数字还是字母
Word[wid]=subString;
if(subString.Equals("void"))
{wordNum[wid]=0;}
else
{
if(subString.Equals("main"))
{wordNum[wid]=1;}
else
{
if(subString.Equals("()"))
{wordNum[wid]=2;}
else
{
if(subString.Equals("{"))
{wordNum[wid]=3;}
else
{
if(subString.Equals("int"))
{wordNum[wid]=4;}
else
{
if(subString.Equals("="))
{wordNum[wid]=6;}
else
{
if(subString.Equals("}"))
{wordNum[wid]=22;}
else
{
if(subString.Equals(";"))
{wordNum[wid]=23;}
else//识别变量和数字
{
if(sort>47&sort<58)
{wordNum[wid]=7;}
else
{wordNum[wid]=5;}
}
}
}
}
}
}
}
}
Console.Write(subString+"("+wordNum[wid]+")"+"");
wid++;
}
}
Console.WriteLine("\n");
}while(strBufferText!
=null);
wordNum[wid]=24;
myTextRead.myStreamReader.Close();
//*********************************
//读入LR分析表
//
//***********************************
/*此处代码略*/
int[]state=newint[100];
string[]symbol=newstring[100];
state[0]=0;
symbol[0]="#";
intp1=0;
intp2=0;
Console.WriteLine("\n按文法规则归约顺序如下:
\n");
//***************
//归约算法如下所显示
//***************
while(true)
{
intj,k;
j=state[p2];
k=wordNum[p1];
t=LR[j,k];//当出现t为0的时候
if(t==0)
{
//错误类型
stringerror;
if(k==0)
error="void";
else
if(k==1)
error="main";
else
if(k==2)
error="()";
else
if(k==3)
error="{";
else
if(k==4)
error="int";
else
if(k==6)
error="=";
else
if(k==22)
error="}";
else
if(k==23)
error=";";
else
error="其他错误符号";
Console.WriteLine("\n检测结果:
");
Console.WriteLine("代码中存在语法错误");
Console.WriteLine("错误状况:
错误状态编号为"+j+"读头下符号为"+error);
break;
}
else
{
if(t==-100)//-100为达到接受状态
{
Console.WriteLine("\n");
Console.WriteLine("\n检测结果:
");
Console.WriteLine("代码通过语法检测");
break;
}
if(t<0&&t!
=-100)//归约
{
stringm=grammar[-t];
Console.Write(m+"");//输出开始符
intlength=lengh[-t];
p2=p2-(length-1);
SearchmySearch=newSearch();
intright=mySearch.search(m);
if(right==0)
{
Console.WriteLine("\n");
Console.WriteLine("代码中有语法错误");
break;
}
inta=state[p2-1];
intLRresult=LR[a,right];
state[p2]=LRresult;
symbol[p2]=m;
}
if(t>0)
{
p2=p2+1;
state[p2]=t;
symbol[p2]=Convert.ToString(wordNum[p1]);
p1=p1+1;
}
}
}
myTextRead.myStreamReader.Close();
Console.Read();
}
示例:
1:
voidmain()
{
inti=8;
intaa=10;
intj=9;
}
2:
voidmain()
{
intqi=8;
intaa=10;
intj=9;
}
对于intqi=8中intq这个错误类型,词法分析通过,而语法分析正确识别出了错误,达到预期目标
产生出错信息:
运行显示如下:
1.3中间代码生成器设计
进入编译程序的第三阶段:
中间代码产生阶段。
为了使编译程序有较高的目标程序质量,或要求从编译程序逻辑结构上把与机器无关和与机器有关的工作明显的分开来时,许多编译程序都采用了某种复杂性介于源程序语言和机器语言之间的中间语言。
常用的几种中间语言有:
逆波兰式、四元式、三元式、树表示。
本课程设计主要实现逆波兰式的生成。
1.3.1逆波兰式的定义和设计思想及算法
1、逆波兰式定义:
将运算对象写在前面,而把运算符号写在后面。
用这种表示法表示的表达式也称做后缀式。
逆波兰式的特点在于运算对象顺序不变,运算符号位置反映运算顺序。
采用逆波兰式可以很好的表示简单算术表达式,其优点在于易于计算机处理表达式。
2、生成逆波兰式的设计思想及算法
(1)首先构造一个运算符栈,此运算符在栈内遵循越往栈顶优先级越高的原则。
(2)读入一个用中缀表示的简单算术表达式,为方便起见,设该简单算术表达式的右端多加上了优先级最低的特殊符号“#”。
(3)从左至右扫描该算术表达式,从第一个字符开始判断,如果该字符是数字,则分析到该数字串的结束并将该数字串直接输出。
(4)如果不是数字,该字符则是运算符,此时需比较优先关系。
做法如下:
将该字符与运算符栈顶的运算符的优先关系相比较。
如果该字符优先关系高于此运算符栈顶的运算符,则将该运算符入栈。
倘若不是的话,则将此运算符栈顶的运算符从栈中弹出,将该字符入栈。
(5)重复上述操作
(1)-
(2)直至扫描完整个简单算术表达式,确定所有字符都得到正确处理,我们便可以将中缀式表示的简单算术表达式转化为逆波兰表示的简单算术表达式。
1.3.2核心代码及其结果显示
#include
#include
#definemax100
charex[max];
voidtrans()
{
charstr[max];
charstack[max];
charch;
intsum,j,t,top=0;
inti=0;/*计数器*/
printf("*****************************************\n");
printf("*说明:
以#号为结束标志.\n");
printf("******************************************\n");
printf("表达示:
");
do
{
i++;
scanf("%c",&str[i]);/*注:
str[0]没有数据*/
if(i>=max)printf("表达式长度过长!
");
}while(str[i]!
='#'&&i!
=max);
sum=i;/*数组长度,即表达式长度*/
t=1;
i=1;
ch=str[i];
i++;
while(ch!
='#')
{
switch(ch)
{
case'(':
top++;
stack[top]=ch;break;
case')':
while(stack[top]!
='(')
{
ex[t]=stack[top];
top--;
t++;
}
top--;break;
case'+':
case'-':
while(top!
=0&&stack[top]!
='(')
{
ex[t]=stack[top];
top--;
t++;
}
top++;
stack[top]=ch;break;
case'*':
case'/':
while(stack[top]=='*'||stack[top]=='/')
{
ex[t]=stack[top];
top--;
t++;
}
top++;
stack[top]=ch;break;
case'':
break;
default:
while(ch>='0'&&ch<='9')
{
ex[t]=ch;
t++;
ch=str[i];
i++;
}
i--;
ex[t]='&';
t++;
}
ch=str[i];
i++;
}
while(top!
=0)
if(stack[top]!
='(')
{
ex[t]=stack[top];
t++;
top--;
}
else
{
printf("error");
top--;
exit(0);
}
ex[t]='#';
printf("\n原表达式是:
");
for(j=1;jprintf("%c",str[j]);
printf("\n后缀表达式是:
");
for(j=1;jprintf("%c",ex[j]);
}
voidcompvalue()
{
floatstack[max],d;
charch;
intt=1,top=0;
ch=ex[t];
t++;
while(ch!
='#')
{
switch(ch)
{
case'+':
stack[top-1]=stack[top-1]+stack[top];/*根据运算符,进行四则运算*/
top--;break;
case'-':
stack[top-1]=stack[top-1]-stack[top];
top--;break;
case'*':
stack[top-1]=stack[top-1]*stack[top];
top--;break;
case'/':
if(stack[top]!
=0)
stack[top-1]=stack[top-1]/stack[top];
else
{
printf("\n\tchu0error!
\n");
exit(0);
}
top--;break;
default:
d=0;/*判断是否为数字,是则将数字字符转化为对应的数值,并入栈*/
while(ch>='0'&&ch<='9')
{
d=10*d+ch-'0';
ch=ex[t];
t++;
}
top++;
stack[top]=d;
}
ch=ex[t];
t++;
}
printf("\n计
 升级会员
升级会员 