郑州大学ARM原理及应用课程报告.docx
《郑州大学ARM原理及应用课程报告.docx》由会员分享,可在线阅读,更多相关《郑州大学ARM原理及应用课程报告.docx(13页珍藏版)》请在冰豆网上搜索。
郑州大学ARM原理及应用课程报告
一、8位CPU体系结构的设计
1.CPU的概述
计算机的核心部件CPU通常包含运算器和控制器两大部分。
组成CPU的基本部件有运算部件,寄存器组,微命令产生部件和时序系统等。
这些部件通过CPU内部的总线连接起来,实现它们之间的信息交换。
2.CPU运行原理
在部件运行过程中,各部件单元的控制信号是人为模拟产生的,并能在微过程控制下自动产生各部件单元控制信号,实现特定的功能。
计算机数据通路的控制将由微过程控制器来完成,CPU从内存中取出一条机器指令到指令执行结束的一个指令周期,全部由微指令组成的序列来完成,即一条机器指令对应一个微程序。
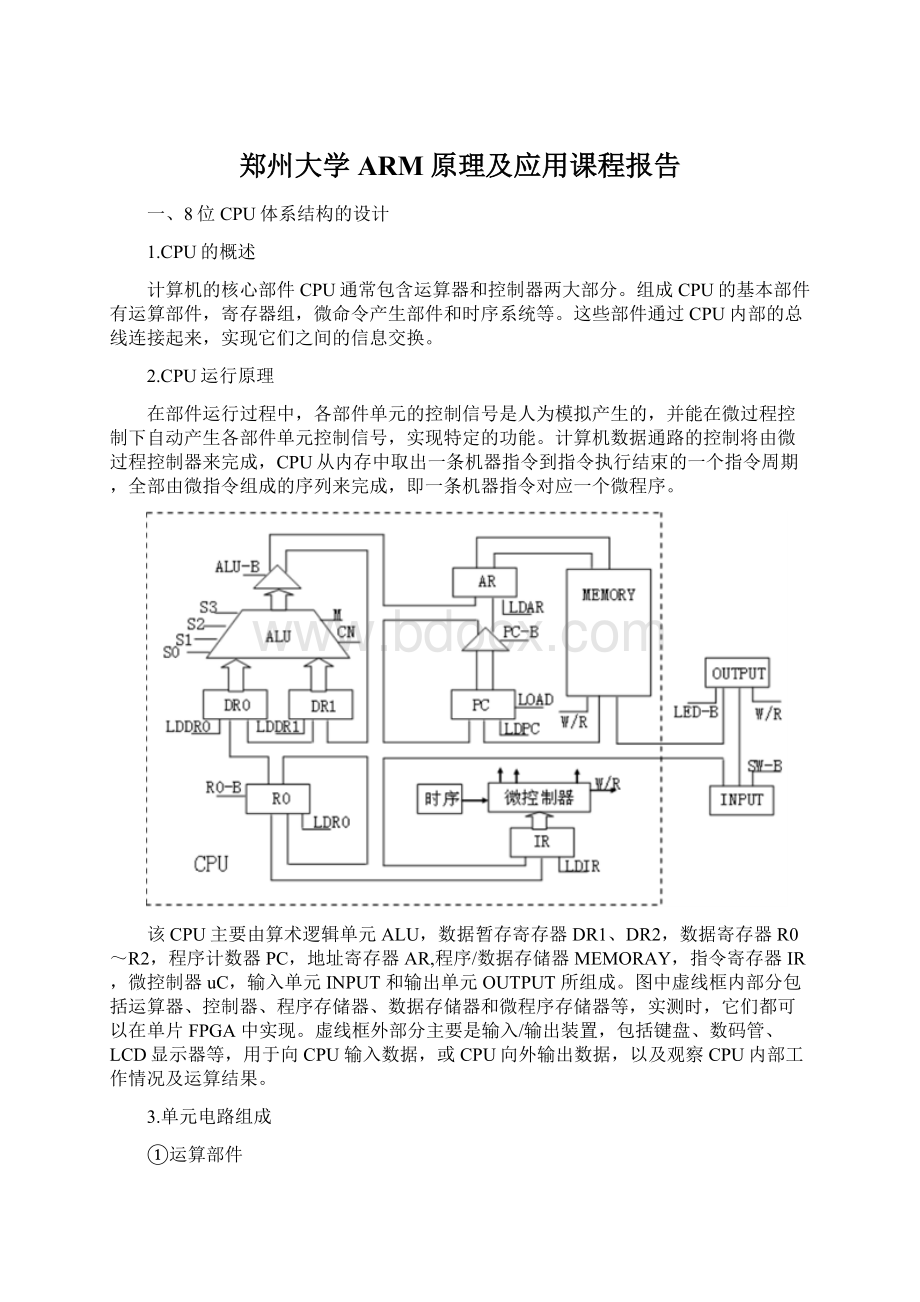
该CPU主要由算术逻辑单元ALU,数据暂存寄存器DR1、DR2,数据寄存器R0~R2,程序计数器PC,地址寄存器AR,程序/数据存储器MEMORAY,指令寄存器IR,微控制器uC,输入单元INPUT和输出单元OUTPUT所组成。
图中虚线框内部分包括运算器、控制器、程序存储器、数据存储器和微程序存储器等,实测时,它们都可以在单片FPGA中实现。
虚线框外部分主要是输入/输出装置,包括键盘、数码管、LCD显示器等,用于向CPU输入数据,或CPU向外输出数据,以及观察CPU内部工作情况及运算结果。
3.单元电路组成
①运算部件
运算部件的任务是对操作数进行加工处理。
主要由三部分组成:
a.输入逻辑
b.算术/逻辑运算部件ALU
c.输出逻辑
②寄存器组
计算机工作时,CPU需要处理大量的控制信息和数据信息。
例如对指令信息进行译码,以便产生相应控制命令对操作数进行算术或逻辑运算加工,并且根据运算结果决定后续操作等。
因此,在CPU中需要设置若干寄存器,暂时存放这些信息。
在模型CPU中,寄存器组由R0、R1、R2所组成。
③指令寄存器
指令寄存器(IR)用来存放当前正在执行的指令,它的输出包括操作码信息、地址信息等,是产生微命令的主要逻辑依据。
④程序计数器
程序计数器(PC)也称指令指针,用来指示指令在存储器中的存放位置。
当程序顺序执行时,每次从主存取出一条指令,PC内容就增量计数,指向下一条指令的地址。
增量值取决于现行指令所占的存储单元数。
如果现行指令只占一个存储单元,则PC内容加1;若现行指令占了两个存储单元,那么PC内容就要加2。
当程序需要转移时,将转移地址送入PC,使PC指向新的指令地址。
因此,当现行指令执行完,PC中存放的总是后续指令的地址;将该地址送往主存的地址寄存器AR,便可从存储器读取下一条指令。
⑤地址寄存器
CPU访问存储器,首先要找到需要访问的存储单元,因此设置地址寄存器(AR)来存放被访单元的地址。
当需要读取指令时,CPU先将PC的内容送入AR,再由AR将指令地址送往存储器。
当需要读取或存放数据时,也要先将该数据的有效地址送入AR,再对存储器进行读写操作。
⑥标志寄存器
标志寄存器F是用来记录现行程序的运行状态和指示程序的工作方式的,标志位则用来反映当前程序的执行状态。
一条指令执行后,CPU根据执行结果设置相应特征位,作为决定程序流向的判断依据。
例如,当特征位的状态与转移条件符合时,程序就进行转移;如果不符合,则顺序执行。
在后面将要介绍的较复杂模型计算机设计中设置了两个标志位:
进位位Fc:
运算后如果产生进位,将Fc置为1;否则将Fc清为0。
零位Fz:
运算结果为零,将Fz置为1,否则将Fz清为0。
⑦微命令产生部件
实现信息传送要靠微命令的控制,因此在CPU中设置微命令产生部件,根据控制信息产生微命令序列,对指令功能所要求的数据传送进行控制,同时在数据传送至运算部件时控制完成运算处理。
微命令产生部件可由若干组合逻辑电路组成,也可以由专门的存储逻辑组成。
产生微命令的方式可分为组合逻辑控制方式和微程序控制方式两种。
在本章所介绍的8位模型CPU设计中,采用微程序控制方式通过微程序控制器和微指令存储器产生微命令,因此此CPU属于复杂指令CISCCPU。
⑧时序系统
计算机的工作常常是分步执行的,那么就需要有一种时间信号作为分步执行的标志,如周期、节拍等。
节拍是执行一个单步操作所需的时间,一个周期可能包含几个节拍。
这样,一条指令在执行过程中,根据不同的周期、节拍信号,就能在不同的时间发出不同的微命令完成不同的微操作。
周期、节拍、脉冲等信号称为时序信号,产生时序信号的部件称为时序发生器或时序系统,它由一组触发器组成。
由石英晶体振荡器输出频率稳定的脉冲信号,也称时钟脉冲,为CPU提供时钟基准。
时钟脉冲经过一系列计数分频,产生所需的节拍(时钟周期)信号。
时钟脉冲与周期、节拍信号和有关控制条件相结合,可以产生所需的各种工作脉冲。
4.指令系统的结构及功能的确定
指令是计算机执行某种操作的命令,而指令系统是一台计算机中所有机器指令的集合。
通常性能较好的计算机都设置有功能齐全、通用性强、指令丰富的指令系统,而指令功能的实现需要复杂的硬件结构来支持。
因此在设计CPU时,首先要明确机器硬件应具有哪些功能,然后根据这些功能来设置相应指令,包括确定所采用的指令格式、所选择的寻址方式和所需要的指令类型。
设模型机指令系统中包含有五条基本指令,分为算术运算指令、存取指令和控制转移指令等三种类型。
五条机器指令分别是:
IN(输入)、ADD(二进制加法)、STA(存数)、OUT(输出)、JMP(无条件转移)。
IN为单字长(8位二进制),其余为双字长指令,XXH为addr对应的十六进制地址码。
①微命令和微操作
微命令和微操作是一一对应的。
微命令是微操作的控制信号,微操作是微命令的操作过程。
微命令有兼容性和互斥性之分。
兼容性微命令是指那些可以同时产生,共同完成某一些微操作的微命令;而互斥性微命令是指在机器中不允许同时出现的微命令。
兼容和互斥都是相对的,一个微命令可以和一些微命令兼容,和另一些微命令互斥。
对于单独一个微命令,就无所谓兼容性或互斥性了。
②微指令、微地址
微指令是指控制存储器中的一个单元的内容,即控制字,是若干个微命令的集合,存放控制字的控制存储器的单元地址就称为微地址。
一条微指令通常至少包含两大部分信息:
微操作码字段,又称操作控制字段,该字段指出微指令执行的微操作;微地址码字段,又称顺序控制字段,指出下一条要执行的微指令的地址。
③微周期
所谓微周期是指从控存中读取出一条微指令并执行规定的相应操作所需的时间。
④微程序
一系列微指令的有序集合就是微程序。
若干条有序的微指令构成了微程序。
微程序可以控制实现一条机器指令的功能。
或者说一条机器指令可以分解为特定的微指令序列。
一旦机器的指令系统确定以后,每条指令所对应的微程序被设计好并且存入控存后,控存总是处于只读的工作状态,所以控存一般采用只读存储器(ROM)存放。
重新设计控存内容就能增加、删除、修改机器指令系统。
在FPGA
中通常采用嵌入式阵列块构成的LPM_ROM作为控存,存放微指令。
24位微代码定义
24
23
22
21
20
19
18
17
16
151413
S3
S2
S1
S0
M
Cn
WE
A9
A8
A
操作控制信号
译码器
121110
987
6
5
4
3
2
1
B
C
uA5
uA4
uA3
uA2
uA1
uA0
译码器
译码器
下地址段
uA5~uA0:
微程序控制器的微地址输出信号,是下一条要执行的微指令的微地址。
S3、S2、Sl、S0:
由微程序控制器输出的ALU操作选择信号,以控制执行16种算术操作或16种逻辑操作中的某一种操作。
M:
微程序控制输出的ALU操作方式选择信号。
M=0执行算术操作;M=l执行逻辑操作。
。
Cn:
微程序控制器输出的进位标志信号,Cn=0表示ALU运算时最低位有进位;Cn=1则表示无进位。
WE:
微程序控制器输出的RAM控制信号。
当CE=0时,如WE=0,为存储器读;如WE=1,为存储器写A9、A8:
译码后产生CS0、CS1、CS2信号,分别作为SW_B、
RAM、LED的选通控制信号。
A字段
B字段
C字段
15
14
13
选择
12
11
10
选择
9
8
7
选择
0
0
0
0
0
0
0
0
0
0
0
1
LDRi
0
0
1
RS-B
0
0
1
P
(1)
0
1
0
LDDR1
0
1
0
RD_B
0
1
0
P
(2)
0
1
1
LDDR2
0
1
1
RJ_B
0
1
1
P(3)
1
0
0
LDIR
1
0
0
SFT_B
1
0
0
P(4)
1
0
1
LOAD
1
0
1
ALU_B
1
0
1
LDAR
1
1
0
LOAD
1
1
0
PC-B
1
1
0
LDPC
A字段(15、14、13):
译码后产生与总线相连接的各单元的输入选通信号。
B字段(12、11、10):
译码后产生与总线相连接的各单元的输出选通信号。
C字段(9、8、7):
译码后产生分支判断测试信号P
(1)~P(4)和LDPC信号。
5、微程序及指令
一个具有五条指令IN、ADD、STA、OUT和JMP的微程序流程图。
其中方框代表基本的微操作,菱形框为分支判断框。
①IN指令:
为了执行输入指令,CPU要做两件事情。
首先,由INPUT输入装置的数据开关SW输入数据送到数据总线上;其次,通过数据总线将输入的数据写入寄存器R0中。
BUS←SW;R0←BUS
由于输入到数据总线上的数据就是要写入寄存器的数据,因此可以将这两个操作合并成一个操作:
R0←SW
②ADD指令:
存储单元的地址是存放在紧跟在操作码后的字节中的,因此,首先要以该字节的内容为地址,即将该单元内容送地址寄存器AR;然后,从AR所指向的RAM存储单元取出操作数送给DR2。
由于在取指令操作码时,PC已经自动加1,指向下一字节,该地址就是存放操作数的存储单元的地址。
通过执行以下三个步骤,
可以从存储器中取出操作数送到DR2:
AR←PC,PC←PC+1;以AR的内容作为取操作数的地址
BUS←RAM,AR←BUS;AR指向存放操作数的RAM单元
BUS←RAM,DR2←BUS;RAM中的数据通过BUS送DR2
DR1←R0;将R0中的数据送DR1
R0←(DR1)+(DR2);在ALU中进行加法运算,运算结果送R0
1
2
3
4
5
6
7
8
微地址
LOAD
LDPC
LDAR
LDIR
LDRi
LDPSW
Rs-B
S2
000000
1
1
0
1
0
0
1
0
000111
1
0
0
1
1
1
1
0
9
10
11
12
13
14
15
16
微地址
S1
S0
ALU-B
RD-D
CS-D
RD-I
CS-I
ARRD-B
000000
0
0
1
0
1
1
0
1
000111
0
0
0
0
1
0
1
1
17
18
19
20
21
22
23
24
微地址
P1
P2
uA5
uA4
uA3
uA2
uA1
uA0
000000
1
0
0
0
0
0
0
0
000111
0
0
0
0
0
0
0
0
③STA指令:
向存储器RAM写数据操作STA,以紧跟在操作码后的字节作为存放操作数地址,将R0中的数据存入该地址单元。
首先将紧跟在操作码后的字节的内容送给地址寄存器AR:
AR←PC,PC←PC+1;以PC的内容作为存数据的地址
BUS←RAM,AR←BUS;AR指向存放操作数的RAM单元
BUS←R0,RAM←BUS
④OUT指令:
AR←PC,PC←PC+1;以PC的内容作为存数据的地址
BUS←RAM,AR←BUS;AR指向存放操作数的RAM单元
BUS←RAM,DR1←BUS
OUT←DR1
⑤JMP指令:
AR←PC,PC←PC+1;以PC的内容作为取数据的地址
1
2
3
4
5
6
7
8
微地址
LOAD
LDPC
LDAR
LDIR
LDRi
LDPSW
Rs-B
S2
000000
1
1
0
1
0
0
1
0
000111
0
1
0
1
0
0
1
0
9
10
11
12
13
14
15
16
微地址
S1
S0
ALU-B
RD-D
CS-D
RD-I
CS-I
ARRD-B
000000
0
0
1
0
1
1
0
1
000111
0
0
1
0
1
0
0
0
17
18
19
20
21
22
23
24
微地址
P1
P2
uA5
uA4
uA3
uA2
uA1
uA0
000000
1
0
0
0
0
0
0
0
000111
0
0
0
0
0
0
0
0
一、现代计算机CPU架构的特点对比
1.ARM架构
ARM架构,过去称作进阶精简指令集机器(AdvancedRISCMachine,更早称作:
AcornRISCMachine),是一个32位精简指令集(RISC)处理器架构,其广泛地使用在许多嵌入式系统设计。
由于节能的特点,ARM处理器非常适用于行动通讯领域,符合其主要设计目标为低耗电的特性。
在今日,ARM家族占了所有32位嵌入式处理器75%的比例,使它成为占全世界最多数的32位架构之一。
ARM处理器可以在很多消费性电子产品上看到,从可携式装置(PDA、移动电话、多媒体播放器、掌上型电子游戏,和计算机)到电脑外设(硬盘、桌上型路由器)甚至在导弹的弹载计算机等军用设施中都有他的存在。
在此还有一些基于ARM设计的派生产品,重要产品还包括Marvell的XScale架构和德州仪器的OMAP系列。
优势:
①是体积小、低功耗、低成本、高性能;
②是大量使用寄存器且大多数数据操作都在寄存器中完成,指令执行
速度更快;
③是寻址方式灵活简单,执行效率高;
④是指令长度固定,可通过多流水线方式提高处理效率。
特点:
①许多指令的执行周期数可变,例如多寄存器传送指令ldm/stm;
②桶形移位器的引入;
③绝大多数ARM指令都具有条件执行的功能;
④增强指令集,主要为DSP乘法指令;
⑤thumb和arm两种指令模式。
2.MIPS架构
MIPS是世界上很流行的一种RISC处理器。
MIPS的意思是“无内部互锁流水级的微处理器”(Microprocessorwithoutinterlockedpipedstages),其机制是尽量利用软件办法避免流水线中的数据相关问题。
它最早是在80年代初期由斯坦福(Stanford)大学Hennessy教授领导的研究小组研制出来的。
MIPS公司的R系列就是在此基础上开发的RISC工业产品的微处理器。
这些系列产品为很多计算机公司采用构成各种工作站和计算机系统。
MIPS技术公司是美国著名的芯片设计公司,它采用精简指令系统计算结构(RISC)来设计芯片。
和英特尔采用的复杂指令系统计算结构(CISC)相比,RISC具有设计更简单、设计周期更短等优点,并可以应用更多先进的技术,开发更快的下一代处理器。
MIPS是出现最早的商业RISC架构芯片之一,新的架构集成了所有原来MIPS指令集,并增加了许多更强大的功能。
特点:
MIPS是高效精简指令集计算机体系结构中的一种,与当前商业化最成功的ARM架构相比,MIPS的优势主要有五点:
①早于ARM支持64bit指令和操作,截至目前MIPS已面向高中低端市场先后发布了P5600系列、I6400系列和M5100系列64位处理器架构,其中P5600、I6400单核性能分别达到3.5和3.0DMIPS/MHz,即单核每秒可处理350万条和300万条指令,超过ARMCortex-A53230万条/秒的处理速度;
②MIPS有专门的除法器,可以执行除法指令;
③MIPS的内核寄存器比ARM多一倍,在同样的性能下MIPS的功耗会比ARM
更低,同样功耗下性能比ARM更高;
④MIPS指令比ARM稍微多一些,执行部分运算更为灵活;
⑤MIPS在架构授权方面更为开放,允许授权商自行更改设计,如更多核的
设计。
同时,MIPS架构也存在一些不足之处:
①MIPS的内存地址起始有问题,这导致了MIPS在内存和cache的支持方面
都有限制,即MIPS单内核无法面对高容量内存配置;
②MIPS技术演进方向是并行线程,类似INTEL的超线程,而ARM未来的发
展方向是物理多核,从目前核心移动设备的发展趋势来看物理多核占据了
上风;
③MIPS虽然结构更加简单,但是到现在还是顺序单/双发射,ARM则已经进
化到了乱序双/三发射,执行指令流水线周期远不如ARM高效;
④MIPS学院派发展风格导致其商业进程远远滞后于ARM,当ARM与高通、苹
果、NVIDIA等芯片设计公司合作大举进攻移动终端的时候,MIPS还停留
在高清盒子、打印机等小众市场产品中;
⑤MIPS自身系统的软件平台也较为落后,应用软件与ARM体系相比要少很多。
3.x86架构
x86CISC是一种为了便于编程和提高记忆体访问效率的芯片设计体系,包括两大主要特点:
①使用微代码,指令集可以直接在微代码记忆体里执行,新设计的处理器,
只需增加较少的电晶体就可以执行同样的指令集,也可以很快地编写新的
指令集程式;
②拥有庞大的指令集,x86拥有包括双运算元格式、寄存器到寄存器、寄存
器到记忆体以及记忆体到寄存器的多种指令类型,为实现复杂操作,微处
理器除向程序员提供类似各种寄存器和机器指令功能外,还通过存于只读
存储器(ROM)中的微程序来实现极强的功能,微处理器在分析完每一条指
令之后执行一系列初级指令运算来完成所需的功能。
x86指令体系的优势体现在能够有效缩短新指令的微代码设计时间,允许实现CISC体系机器的向上兼容,新的系统可以使用一个包含早期系统的指令集合。
另外微程式指令的格式与高阶语言相匹配,因而编译器并不一定要重新编写。
相较ARMRISC指令体系,其缺点主要包括四个方面:
①通用寄存器规模小,x86指令集只有8个通用寄存器,CPU大多数时间是
在访问存储器中的数据,影响整个系统的执行速度。
而RISC系统往往具
有非常多的通用寄存器,并采用了重叠寄存器窗口和寄存器堆等技术,使
寄存器资源得到充分的利用。
②解码器影响性能表现,解码器的作用是把长度不定的x86指令转换为长度
固定的类似于RISC的指令,并交给RISC内核。
解码分为硬件解码和微解
码,对于简单的x86指令只要硬件解码即可,速度较快,而遇到复杂的x86
指令则需要进行微解码,并把它分成若干条简单指令,速度较慢且很复杂。
③x86指令集寻址范围小,约束用户需要。
④x86CISC单个指令长度不同,运算能力强大,不过相对来说结构复杂,很
难将CISC全部硬件集成在一颗芯片上。
而ARMRISC单个指令长度固定,
只包含使用频率最高的少量指令,性能一般但结构简单,执行效率稳定。
4.PowerPC架构
PowerPC是一种精简指令集(RISC)架构的中央处理器(CPU),其基本的设计源自IBM(国际商用机器公司)的IBMPowerPC601微处理器POWER(PerformanceOptimizedWithEnhancedRISC;《IBMConnect电子报》2007年8月号译为“增强RISC性能优化”)架构。
二十世纪九十年代,IBM(国际商用机器公司)、Apple(苹果公司)和Motorola(摩托罗拉)公司开发PowerPC芯片成功,并制造出基于PowerPC的多处理器计算机。
PowerPC架构的特点是可伸缩性好、方便灵活。
PowerPC处理器有广泛的实现范围,包括从诸如Power4那样的高端服务器CPU到嵌入式CPU市场(任天堂Gamecube使用了PowerPC)。
PowerPC处理器有非常强的嵌入式表现,因为它具有优异的性能、较低的能量损耗以及较低的散热量。
除了象串行和以太网控制器那样的集成I/O,该嵌入式处理器与“台式机”CPU存在非常显著的区别。
特点:
PowerPC处理器有32个(32位或64位)GPR(通用寄存器)以及诸如PC(程序计数器,也称为IAR/指令地址寄存器或NIP/下一指令指针)、LR(链接寄存器)、CR(条件寄存器)等各种其它寄存器。
有些PowerPCCPU还有32个64位FPR(浮点寄存器)。
PowerPC体系结构是RISC(精简指令集计算)体系结构的一个示例。
因此:
所有PowerPC(包括64位实现)都使用定长的32位指令。
PowerPC处理模型要从内存检索数据、在寄存器中对它进行操作,然后将它存储回内存。
几乎没有指令(除了装入和存储)是直接操作内存的。
5.DSP架构
DSP是微处理器的一种,这种微处理器具有极高的处理速度.因为应用这类处理器的场合要求具有很高的实时性(RealTime)。
比如通过移动电话进行通话,如果处理速度不快就只能等待对方停止说话,这一方才能通话。
如果双方同时通话,因为数字信号处理速度不够,就只能关闭信号连接.在DSP出现之前数字信号处理只能依靠MPU(微处理器)来完成。
但MPU较低的处理速度无法满足高速实时的要求。
因此,直到70年代,有人才提出了DSP的理论和算法基础。
那时的DSP仅仅停留在教科书上,即便是研制出来的DSP系统也是由分立元件组成的,其应用领域仅局限於军事、航空航天部门。
90年代DSP发展最快,相继出现了第四代和第五代DSP器件。
现在的DSP属於第五代产品,它与第四代相比,系统集成度更高,将DSP芯核及外围元件综合集成在单一芯片上。
这种集成度极高的DSP芯片不仅在通信、计算机领域大显身手,而且逐渐渗透到人们日常消费领域。
特点:
哈佛结构是不同于传统的冯·诺曼(VonNeuman)结构的并行体系结构,其主要特点是将程序和数据存储在不同的存储空间中,即程序存储器和数据存储器是两个相互独立的存储器,每个存储器独立编址,独立访问。
与两个存储器相对应的是系统中设置了程序总线和数据总线两条总线,从而使数据的吞吐率提高了一倍。
而冯·诺曼结构则是将指令、数据、地址存储在同一存储器中,统一编址,依靠指令计数器提供的地址来区分是指令、数据还是地址。
取指令和取数据都访问同一存储器,数据吞吐率低。
在哈佛结构中,由于程序和数据存储器在两个分开的空间中,因此取指和执行能完全重叠运行。
为了进一步提高运行速度和灵活性,TMS320系列DSP芯片在基本哈佛结构的基础上作了改进,一是允许数据存放在程序存储器中,并被算术运算指令直接使用,增强了芯片的灵活性;二是指令存储在高速缓冲器(Cache)中,当执行此指令时,不需要再从存储器中读取指令,节约了一个指令周期的时间。
 升级会员
升级会员 