SPSS统计与EXCEL统计.docx
《SPSS统计与EXCEL统计.docx》由会员分享,可在线阅读,更多相关《SPSS统计与EXCEL统计.docx(27页珍藏版)》请在冰豆网上搜索。
SPSS统计与EXCEL统计
SPSS统计与EXCEL统计
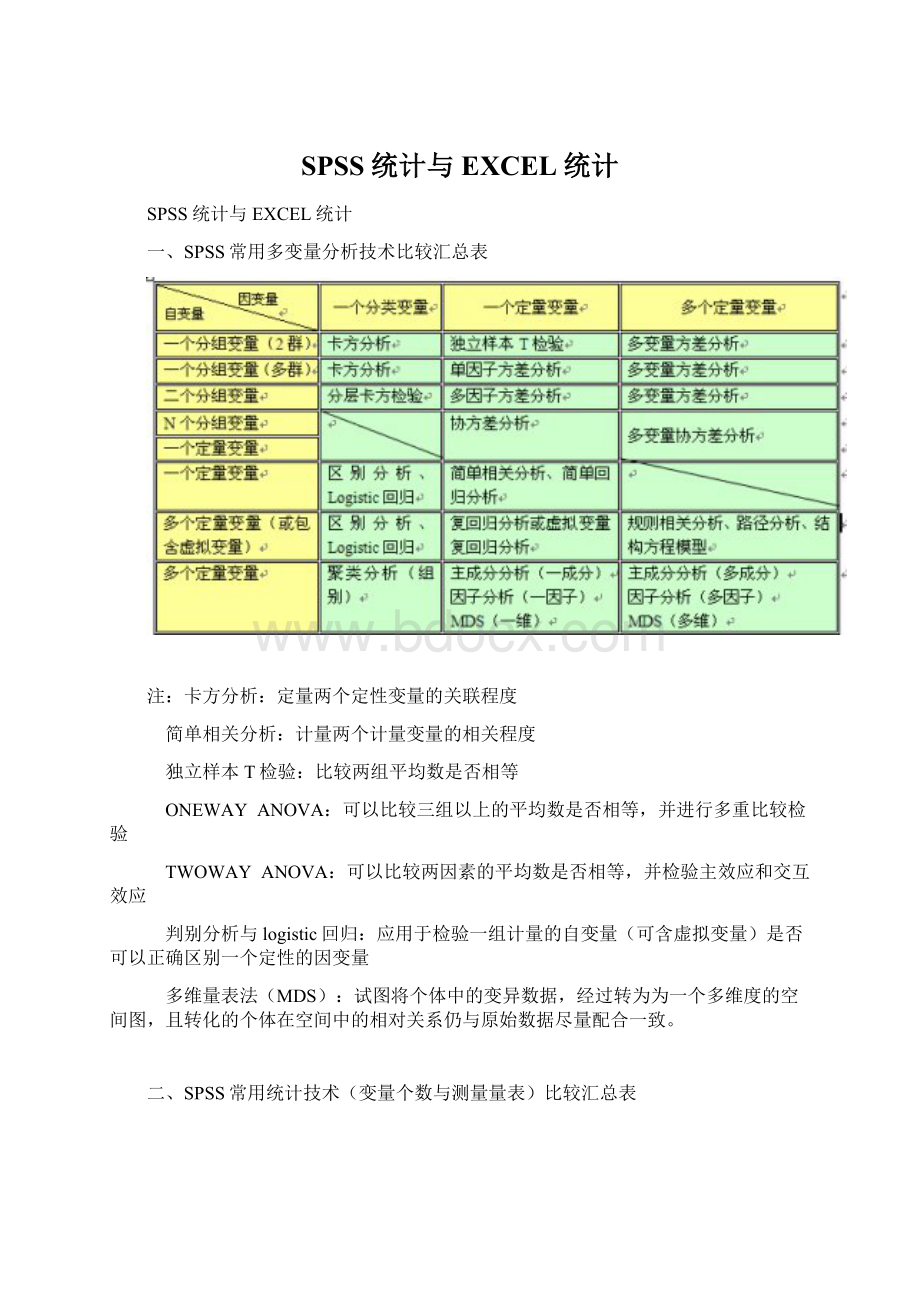
一、SPSS常用多变量分析技术比较汇总表
注:
卡方分析:
定量两个定性变量的关联程度
简单相关分析:
计量两个计量变量的相关程度
独立样本T检验:
比较两组平均数是否相等
ONEWAY ANOVA:
可以比较三组以上的平均数是否相等,并进行多重比较检验
TWOWAY ANOVA:
可以比较两因素的平均数是否相等,并检验主效应和交互效应
判别分析与logistic回归:
应用于检验一组计量的自变量(可含虚拟变量)是否可以正确区别一个定性的因变量
多维量表法(MDS):
试图将个体中的变异数据,经过转为为一个多维度的空间图,且转化的个体在空间中的相对关系仍与原始数据尽量配合一致。
二、SPSS常用统计技术(变量个数与测量量表)比较汇总表
注:
理论模型中变量通常很难测量,这类变量称为潜变量,如绩效、满意度、忠诚度等。
PS:
原本这篇想做一个SPSS学习大纲的,却没找到思维导图软件,只好在WORD上整理了汇总了一些SPSS常用的方法同时也整理了一个SPSS学习的大致框架。
统计假设检验有很多,从大的方面包括参数检验与非参数检验。
参数检验有我们常见的关于方程模型显著性检验的F检验,方程参数的T检验等;而非参数检验中比较常见的则包括符号检验、秩和检验以及游程检验。
提到参数检验时,不得不说的一个概念就是P-值,也就是SAS&SPSS等统计软件输出结果中的做sig.值,到底什么是sig.值是什么,它与我们平时所熟悉的概率P有什么关系,最初它是怎样形成的……提到这些,不得不提到的概念有上分位点、两类错误(弃真和纳伪)以及阀值K又是怎样一回事?
下面我将一一道来:
图1 α值与P值的关系图
一、相关统计概念
1.上分位点
学统计的同学都知道正态分布,而上分位点的由来正与正态分布有关。
最初由标准正态分布由来,随后扩展到t分布,F分布,卡方等其他分布。
下面以标准正态分布为例,设X~N(0,1),若Zα满足条件
P{X>Zα}=α,0<α<1
则称点Zα为标准正态分布的上α分位点,例如:
Z0.05=1.645,Z0.005=2.57,Z0.001=3.10
2.两类错误
简单的讲两类错误是指第一类错误:
"弃真"错误(其发生的概率常用α表示);第二类错误:
"取伪"错误(其发生的概率常用β表示)。
3.阀值(阈值)
这里的阀值与箱型图中的阀值意思相同,都是与判断标准相关的一个临界值,由于使用目的的不同,致使形态上有些许差别。
例如在检验样本均值与总体均值是否有差别时,与检验统计量比较的临界值k(这里姑且先这样定义),就是阀值。
4.显著性水平
假设检验运用了小概率原理,事先确定的作为判断的界限,即允许的小概率的标准,称为显著性水平。
如果根据命题的原假设所计算出来的概率小于这个标准,就拒绝原假设;大于这个标准则接受原假设。
这样显著性水平把概率分布分为两个区间:
拒绝区间,接受区间。
(通常假设检验时只考虑到了第一类错误,而忽视掉了第二类错误,所以将此时的假设检验称为显著性检验)
二、相关概念与P值
前面讲了那么多的统计概念,貌似与P值没什么关联,下面回到文章最初提到的问题,看看上面提到的各种概念和P值(sig.值)是怎样联系起来的,下面以正态分布均值检验为例进行说明:
假设检验的原理清楚了(上面的例子针对正态分布方差已知的情况,其他参数检验只是参照的检验统计量不同罢了),同样由上面的原理可推导出另一种检验—P值检验,P值检验是国际上流行的检验格式。
该格式是通过计算P值,再将它与显著性水平α作比较,决定拒绝还是接受原假设。
所谓P值就是拒绝原假设所需的最低显著性水平。
P值判断的原则是:
如果P值小于给定的显著性水平α,则拒绝原假设,否则,接受原假设。
或者,更加直观的原则是:
如果P值很小,拒绝Ho,P值很大,接受Ho.P值检验为计算机进行统计分析带来方便,P值检验无需针对不同的显著性水平,先查分布表确定临界值,然后才能进行检验判断。
在SPSS统计软件中,不论是哪个检验程序,其所显示的P值都是双尾检验的结果。
若使用者欲进行的是单尾检验,其程序与双尾检验相同,但所得到的P值自行除以2,再与期望的显著水平相比较。
SAS&SPSS等统计软件常用*号表示显著性水平的程度,通常一个*号表示0.1的显著水平,两个**表示0.05的显著水平。
以往运用的一些统计回归方法前面往往有很多的假设,而这些假设往往又是我们大多少数人在使用各种各样的统计方法前最容易忽略的问题.某日,终于能静下心来将一些最常用的方法整理了一通.
1、统计图形判断
a、直方图(Histogram)
常用于大致判断变量数据满足的分布类型
spss大致程序:
GRAPH
/HISTOGRAM(NORMAL)=var1.
一般只要数据样本足够大,通常可以判断变量满足的大致分布类型
b、P-P图&Q-Q图
如果说直方图是大致判断数据满足的分布类型,这种判断常常依赖于统计工作者的经验,人的主观因素太大,难免有所偏差,同时也无法判断估计分布与实际分布的差距有多大,这时候常常用P-P图&Q-Q图来客观表述。
spss大致程序:
PPLOT
/VARIABLES=var1
/TYPE=P-P.
SPSS中提供了13种最常见的分布类型.检验数据是否较好的服从给定分布的标准有2个.第一,看P-P图上的数据点与直线的重合度.第二,看P-P趋势图上的点是否关于Y=0在一个较小的范围内上下波动.Q-Q图与P-P图的定义类似,只是P-P图比较的是真实数据与待检验分布的累计概率.而Q-Q图比较的是真实数据与待检验分布的分位点值.
2、非参数检验判断
一般而言,一个典型的统计推断过程通常由5个步骤构成,假定分布族、抽样、计算统计量和抽样分布,进行推估和检验、评价模型。
SPSS中提供了8种最常用最简单的非参数检验方法,这8种检验方法又被分为分布类型检验和分布位置检验2类。
A、分布类型检验
⑴、卡方检验
卡方检验又称卡方拟合优度检验,用于检验观测数据是否与某种概率分布的理论值相符合,进而推断观测数据是否来自该分布的样本问题。
(要求变量是厕度水平为经排列或未经排列的数值型分类变量,若为连续型变量,可以通过SPSS中的recode过程将样本空间划分区间或者分类。
)
⑵、二项分布检验
二项分布检验过程用于对二元变量的2个分类的观测频数与某个具有确定的概率参数的二项分布的期望频数进行比较的假设检验问题。
(要求检验变量是数值型的二元变量,若不是二元变量可以将数据分成2组)
⑶、游程检验
游程检验是利用总个数获得统计推断结论的方法。
(要求检验变量必须是数量型的)。
⑷、单个样本的K-S检验
K-S检验就是kolmogorov-smirnov检验的简称,它的检验方法是以样本数据的累计频数分布与某一特定的理论分布相比较,若2者间的差距很小,则推论这样本取至某特定分布族。
B、分布位置检验
⑴、两个独立样本分布位置检验
通常用于当样本所属总体的分布类型不明却时,检验2个样本是否来自相同分布的总体。
检验方法:
Mann-whitney的U检验法,即wilcoxon秩和检验法。
Moses极端反映检验法
K-S的Z检验法
Wald-wolfowitz游程检验法
⑵、多个独立样本分布位置检验
多个独立样本分布位置检验是要检验解决多个独立样本间是否具有相同分布的问题。
检验方法:
Kruskal-wallisH检验法,他是mann-whitneyU检验法的推广,是类似于单因素分析的一种检验方法。
中位数检验法
Jonckheere-terpstra检验法,用于解决位置参数某一方向的假设检验问题。
⑶、两个相关样本分布位置检验
当2个样本间的数据不再是相互独立,而是彼此相关时,可以用2个样本分布位置检验来检验2个样本是否有相同的分布。
例如:
检验一超市促销活动的效果等。
⑷、多个相关样本分布位置检验
通常用于检验多个相关样本间是否具有相同的分布。
例如:
可应用于比较厨师的手艺是否有区别。
以上所用检验变量或数据是否服从某一分布都是运用SPSS这一数据处理工具来完成,当然除了上面提到的一些常用方法外,还有很多其他的方法。
SPSS函数是一个常用程序(rountine),并且利用一个或多个自变量(参数)来执行。
每个SPSS函数均有一个关键名称(keywordname),且绝不能写错。
通常,函数的格式为:
函数名称(自变量,自变量,……),某些函数可能只含有一个自变量,而有些函数则可能含有多个自变量,当一个函数含有多个自变量时,各自变量间用逗号(,)隔开,而函数的自变量通常又可分为以下三种:
1)常数,如SQRT(100):
2)变量名称,如MEAN(VAR1,VAR2,VAR3);3)表达式,如MIN(30,SQRT(100))。
总之,SPSS函数和我们平时EXCEL里面函数格式规则并无差别。
SPSS提供了180多种函数,共可分为十多类(SPSS17.0中大大小小分了18类)。
和EXCEL一样,我们也不可能记住所有函数,只要知道一些常用函数,至于其他函数要用的时候再去查找也不迟,下面本人将列举一些常用函数:
(一)算术函数
函数
说明
范例(x=2.6,y=3)
ABS(numbexpr)
绝对值函数
ABS(y-x)=0.4
RND(numbexpr)
四舍五入函数
RND(x)=3
TRUNC(numbexpr)
取整函数
TRUNC(x)=2
SORT(numbexpr)
平方根函数
SQRT(y)=1.71
MOD(numbexpr,modulus)
求算两数相除后的余数
MOD(y,x)=0.4
EXP(numbexpr)
以e为底的指数函数
EXP(y)=20.09
LG10(numbexpr)
以10底的对数函数
LG10(x*10)=1.41
LN(numbexpr)
自然对数函数
LN(y)=1.1
(二)统计函数
函数
说明
范例(X1=2,X2=5,X3=8)
MEAN(numexpr,numexpr,…)
自变量的平均值
MEAN(X1,X2,X3)=5
MIN(value,value,…)
自变量的最小值
MIN(X1,X2,X3)=1
MAX(value,value,…)
自变量的最大值
MAX(X1,X2,X3)=8
SUM(numexpr,numexpr,…)
求和
SUM(X1,X2,X3)=15
SD(numexpr,numexpr,…)
求标准差
SD(X1,X2,X3)=3
VARIANCE(numexpr,numexpr,…)
求方差
VAR(X1,X2,X3)=9
CFVAR(numexpr,numexpr,…)
求变异系数
CFVAR(X1,X2,X3)=0.6
(三)缺失值函数
函数
说明
范例
MISSING(variable)
若变量缺失,则为T或1,否则为F或0
MISSING(X1)=1
MISSING(X2)=1
MISSING(X3)=0
SYSMIS(numvar)
若变量是系统缺失值则为T或1,如为自定缺失或非缺失则为F或0
SYSMIS(X1)=0
SYSMIS(X2)=1
SYSMIS(X3)=0
NMISS(variable,…)
缺失值个数
NMISS(X1,X2,X3)=2
NVALID(variable,…)
有效值个数
NVALID(X1,X2,X3)=1
VALUE(variable,…)
忽略自定义缺失值,当作非缺失
VALUE(X1)=X1
注:
X1为使用者界定缺失值,X2为系统缺失值,X3为非缺失值
(四)字符串型函数
函数
说明
范例
ANY(test,value,value)
若自变量1和后面自变量窜相同则为真,记为1
ANY(is,this)=0
ANY(is,this,is)=1
CONCAT(strexpr,strexpr)
将自变量连成一个新自变量
CONCAT(th,is)=this
INDEX(haystack,needle,divisor)
Divisor在needle最左侧开始出现的位置
INDEX(‘thisis’,’is’)=3
LENGTH(strexpr)
自变量所含文字的个数(包括特殊字符和空格)
LENGTH(‘this’)=5
LOWER(strexpr)
自变量中的大写字母改为小写字母
LOWER(‘This’)=’this’
UPCASE(strexpr)
将自变量中的小写字母改为大写字母
UPCASE(‘this’)=’THIS’
LTRIM(strexpr,char)
在strexpr开始处去除char所形成的常量,如无char则去除strexpr左侧的空格
LTRIM(‘this’,’t’)=’his’
LTRIM(‘this’,’is’)=’th’
LTRIM(‘this’)=’this’
NUMBER(strexpr,format)
当自变量为数字的文字变量时,按文字变量指定格式转换为数字变量
NUMBER(‘23’,F8.1)=2.3
NUMBER(‘23’,F8.0)=23
RANGE(test,lo,hi,lo,hi)
如果自变量1的值包含在自变量集lo至hi的范围内,则为T或1
RANGE(‘c’,’a’,’k’)=T
STRING(strexpr,format)
按指定格式将自变量转换为文字型变量
STRING(3+4,F8.2)=’7.00’
SUBSTR(sterxpr,pos,length)
从strexpr子窜的第pos位置开始取length的字符串长度
SUBSTR(‘thisis’,6,2)=’is’
(五)时间日期函数
函数
说明
范例
DATA.DMY(d,m,y)
与指定日月年对应的日期
DATA.DMY(3,5,99)=05/03/99
DATA.MDY(m,d,y)
与指定月日年对应的日期
DATA.MDY(5,3,99)=05/03/99
DATA.YRDA(y,d)
与指定年日对应的日期
DATA.YRDA(99,35)=02/04/99
DATA.QYR(q,y)
指定的季节年份对应的日期
DATA.QYR(2,99)=04/01/99
DATA.MOYR(m,y)
与指定的月年度对应的日期
DATA.MOYR(5,99)=05/01/99
DATA.WKYR(w,y)
与指定的周年度对应的日期
DATA.WKYR(38,98)=9/17/98
注:
1要正确显示以上函数值,必须先赋予其SPSS得日期型变量(DATA)格式,假设以上日期用mm/dd/yy格式显示,时间则用hh:
mm:
ss格式表示
21<=d<=31、1<=m<=12、1<=w<=52、1<=q<=4
(六)其他函数
SPSS除了上述函数外,尚有日期和时间转换函数(YOMODA\CTMIESDAYS\CTIMEHOURS\MDAYS等)、连续几率密度函数(CDF\BINOM\CHISQ\CDF\EXP\LOGISTIC等),此外还有NORMAL(stddev)可产生平均数为0,标准差为stddev的正态分布随机数字。
UNIFORM(max)可产生平均数为0与max间呈均等分布的随机数字。
PS:
还可以像EXCEL一样利用脚本编写自定义函数,目前SPSS支持python,SaxBasic(一种与VB兼容的编程语言)等语言,利用new--script可编写出自己需要的函数。
script界面如下:
EXCEL常见的统计函数及其用法
EXCEL中包含有79个统计函数,从最基本的求和、最大值、最小值函数,到各种复杂统计分布函数,如正态分布函数,超几何函数等等。
和其他函数一样,使用统计函数时并不需要记住所有的函数,我们只需要记住了解有那么一个函数,等到真正使用的时候F1比什么都强,当然,前提是你首先知道那个函数,譬如当提到正态分布的时候,我们首先想到的就是均值和标准差;提到大小排序你可能想到large/small/rank之类的,至于其他的一些具体的详细的说明用法交给F1吧。
EXCEL中的函数常见的用法无外乎直接使用,嵌套使用,与数据透视表、VBA等结合的高级使用等等,对于统计函数,EXCEL有其更加高级的数据分析功能(需要加载宏,添加数据分析模块)。
直接使用法
此类方法通常解决最基本、最简单的问题,有时候为了操作方便会采用与数组结合的方式使用。
譬如老师计算每个同学的各科成绩和,然后根据总成绩排名,就属于此类用法。
嵌套使用
此类方法主要解决较直接使用方法更复杂的一类问题,这类方法更多的是组合各函数功能解决问题。
譬如if类函数,countif计算区域中满足给定条件的单元格的个数,sumif根据指定条件对若干单元格求和。
其他高级应用
此类应用主要分为内部应用和外部应用,内部应用常见的与VBA结合的使用产生的满足企业个性需求的自定义函数(自定义函数的简单应用),以及与数据透视表结合的公式应用;外部应用这里主要指EXCEL与其他软件的结合使用,目前最典型的范例就是与Xcelsius(水晶易表)的使用。
相关统计模块的使用
此类方法的应用需要加载宏,其中宏的来源主要分为2部分,一部分是EXCEL系统自带的,譬如规划求解、欧元工具等,另一部分则是由其他个人或组织二次开发所定制的满足个性需求的小插件,譬如下图中的IP。
完成相关加载宏后,我们就可以在自定义函数区域或是工具菜单栏找到相应的选项,譬如我的EXCEL加载了分析工具模块,我就可以直接调用数据分析功能。
譬如我要分析网站某一页面改版前后点击量是否有明显的改善,这时候我们就可以利用数据分析模块中的T检验做一个简单的判定。
PS:
本篇并未对统计函数的具体参数方法进行说明,也没有对各中方法的使用进行详细介绍,每种方法都轻轻的点了一下,而这些方法的使用更多的是结合我们工作中的实际情况而定,工具只是工具,业务背景的理解才是最重要的,工具只是帮助提高效率。
关于EXCEL的各种深入应用技巧可以去EXCELHOME论坛泡泡,相信在那里你会大有收获,至于其他的,你们懂的。
一基础篇(数据透视表的概念)
03
有人说,数据透视表就是一个小型数据库;也有人说数据透视表就是能够将筛选、排序和分类汇总等操作依次完成,并生成汇总表格,是Excel强大数据处理能力的具体体现;还有人说,数据透视表是从原始凭证到登记帐簿、编制报表的一个程序……
这些都没错,数据透视表确实具有上述这些功能,准确的讲,数据透视表是用来从Excel数据列表、关系数据库文件或OLAP多维数据集中的特殊字段中总结信息的分
析工具。
它是一种交互式报表,可以快速分类汇总、比较大量的数据,并可以随时选择其中页、行和列中的不同元素,以达到快速查看源数据的不同统计结果,同时还可以随意显示和打印出你所感兴趣区域的明细数据。
数据透视表有机的综合了数据排序、筛选、分类汇总等数据分析的优点,可方便地调整分类汇总的方式,灵活地以多种不同方式展示数据的特征。
一张“数据透视表”仅靠鼠标移动字段位置,即可变换出各种类型的报表。
同时,数据透视表也是解决函数公式速度瓶颈的手段之一。
因此,该工具是最常用、功能最全的Excel数据分析工具之一。
二数据透视表相关技巧介绍
1.排序技巧
A、手动排序数据透视表,手动排序数据透视表的方法有:
1. 使用工具栏按钮
2. 使用菜单命令排序。
(选定参与排序列的任意单元格---数据---排序)
3. 使用右键快捷菜单的顺序命令排序。
4. 利用鼠标快速排序(选中要排序的单元格拖动排序)。
手动排序的缺点,就是当数据透视表的数据源有改动的时候,透视表需要刷新,这里刷新透视表的话,所有的手动排序结果将不负存在,重新使用时需要再次重新操作。
B、自动排序数据透视表,自动排序数据表的方法有:
1. 双击字段名称,通过“数据透视表字段”的功能来完成排序工作。
双击自段名称---“数据透视表字段”---“高级”依各自的排序要求进行选择,从面达到排序目的。
2.利用数据透视表工具栏自动排序,从数据透视表工具栏选择数据透视表---排列并列出前十项进行排序。
3.根据列字段数据顺序对行字段进行排序。
C、按笔画排序
我们中国人的习惯喜欢按笔画来排序表格。
所以来看看怎样用笔划来对表格进行排序。
按笔画排序的顺序为:
比笔画的多少,笔画相同的情况下比笔划的起笔如横竖撇捺折的顺序。
起笔再相同的比字体的结构,先是左右结构再上下结构再整体结构。
1.按笔划顺序纵向排序。
从工具栏“数据”—“-排序”---“选项”---“笔划”
2.按笔划顺序横向排序。
方法同上。
D、自定义排序
自定义排序主要就是要会添加自定义顺序序列。
其方法为:
“工具”---“选项”---“自定义序列”---输入自已要定义的序列---“添加”。
使用自定义序列的方法是“数据”---“排序”---“升/降序”---“自定义排序次序”里选择刚才创建的序列---“确定”。
E、其他
数据透视表的另外一项排序功能就是挑选出自己需要的数字序列,而进行简单的数据分析工作。
譬如从一系列的网络连接中挑选出访问数据最大的三个站点,有譬如从成千上万的链接流量中挑选出贡献流量前15%的站点等等,这些都可以通过数据透视表来实现。
当然,实际工作中的情况需要个人进行更多的组合,譬如根据数据透视表的结果再一次透视,形成新的达到要求透视表;再譬如事先进行排序,利用产生的部分结果形成自定义序列,再进行下一步排序。
这里需要注意的是,不管是数据透视表还是自定义排序的数据列,都对字段数目有要求,EXCEL2003中自定义序列的数目应该不超过1000个,数据透视表字段选项的数目不超过3万个(具体多少本人也没测试过,平时工作中处理6W多条数据记录时透视表就无法达到要求了,拖动相关字段时总报错)。
2.项目分组技巧
A字段组合的调用
通常调用字段组合有
 升级会员
升级会员 