虚拟化技术IO虚拟化.docx
《虚拟化技术IO虚拟化.docx》由会员分享,可在线阅读,更多相关《虚拟化技术IO虚拟化.docx(6页珍藏版)》请在冰豆网上搜索。
虚拟化技术IO虚拟化
1虚拟化技术-I/O虚拟化
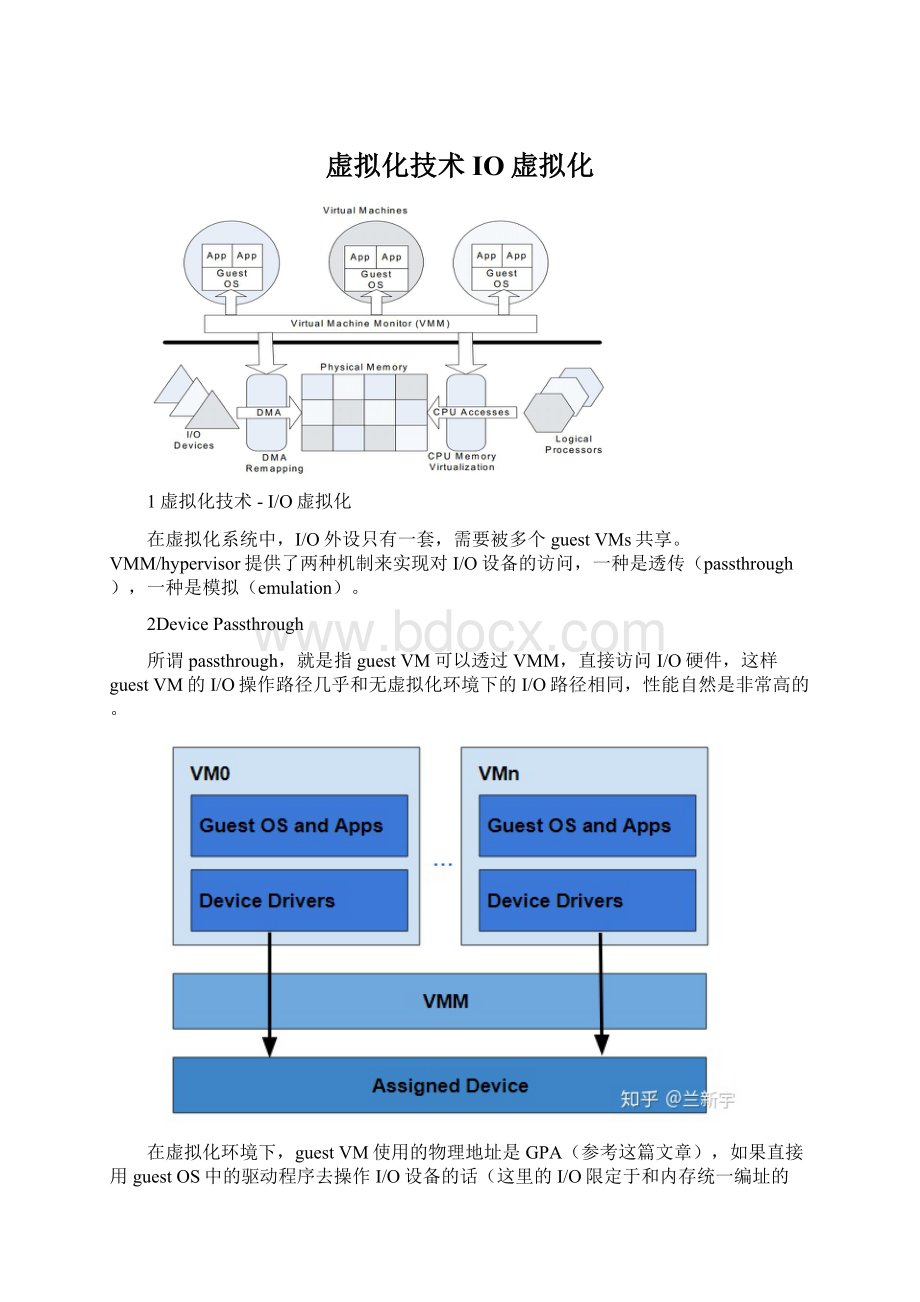
在虚拟化系统中,I/O外设只有一套,需要被多个guestVMs共享。
VMM/hypervisor提供了两种机制来实现对I/O设备的访问,一种是透传(passthrough),一种是模拟(emulation)。
2DevicePassthrough
所谓passthrough,就是指guestVM可以透过VMM,直接访问I/O硬件,这样guestVM的I/O操作路径几乎和无虚拟化环境下的I/O路径相同,性能自然是非常高的。
在虚拟化环境下,guestVM使用的物理地址是GPA(参考这篇文章),如果直接用guestOS中的驱动程序去操作I/O设备的话(这里的I/O限定于和内存统一编址的MMIO),那么设备使用的地址也是GPA。
这倒不难办,使用CPU的EPT/NPTMMU查询对应guestVM的nPT页表,进行一下GPA->HPA的转换就可以了。
可是别忘了,有一些I/O设备是具备DMA(DirectMemoryAccess)功能的。
由于DMA是直接在设备和物理内存之间传输数据,必须使用实际的物理地址(也就是HPA),但DMA本身是为了减轻CPU的处理负担而存在的,其传输过程并不经过CPU。
对于一个支持DMA传输的设备,当它拿着GPA去发起DMA操作时,由于没有真实的物理内存地址,传输势必会失败。
那如何实现对进行DMA传输的设备的GPA->HPA转换呢?
再来一个类似于EPT/NPT的MMU?
没错,这种专门转换I/O地址的MMU在x86的阵营里就是IOMMU。
然而,不和AMD使用相同的名字是Intel一贯的路数,所以Intel通常更愿意把这种硬件辅助的I/O虚拟化技术叫做VT-d(VirtualizationTechnologyforDirectI/O)。
作为后起之秀的ARM自然也不甘示弱,推出了对应的SMMU(SystemMMU)。
IOMMU查找的页表通常是专门的I/Opagetables。
既然都是进行GPA->HPA的转换,为什么不和EPT/NPTMMU共享nPT页表呢?
这个问题将在接下来的文章中给出解答。
为了加速查找过程,IOMMU中也有类似于EPT/NPTTLB的IOTLB硬件单元。
以Intel的VT-d为例,它规定了一个domain对应一个IO页表。
在具体的实现中,通常是一个guestVM作为一个domain,因此分配给同一个guestVM的设备将共享同一个IO页表。
这里为了支持devicepassthrough模式下的DMA传输,IOMMU进行的是GPA->HPA的转换。
既然EPT/NPTMMU都可以同时支持GVA->GPA和GPA->HPA的转换,那IOMMU是否也可以呢?
这个问题也将留在后续的文章中讨论。
Devicepassthrough机制要求VMM为guestVM分配好设备,并提供隔离。
假设系统中现在有三个guestVMs,编号分别是0,1,2,如果VM0分配到了网卡A,就要阻止VM1和VM2对网卡A的访问。
可以采用的方法是在拥有设备的guestVM加载驱动程序前,先给要分配出去的设备加载一个伪驱动作为占位符,由于没有真正的驱动程序,这个设备对于其他的guestVM来说就相当于是“隐藏”了。
这同时也暴露了使用devicepassthrough存在的一个问题,就是同一个I/O设备通常无法在不同的guestVM之间实现共享和动态迁移(比如PCI设备的热插拔)。
下文将介绍的deviceemulation机制将可以解决设备共享和迁移的问题。
3虚拟化技术-I/O虚拟化[二]
上文介绍了无需VMexit(参考这篇文章),性能优良,但不利于实现设备共享和迁移的devicepassthrough(I/O透传)机制,本文将介绍I/O虚拟化的另一种实现方式。
4DeviceEmulation
前面的文章提到,直接基于bare-metal的VMM分为两种,一种是由加入了虚拟化功能的操作系统组成的hypervisor模型,一种是像Xen和Acrn这种VMM层相对精简,主要负责CPU管理和内存管理的混合模型。
在hypervisor模型中,VMM直接就可以提供各种外设驱动,因此实现对guestVM所访问设备的模拟是很方便的。
对于混合模型,设备模拟的方法就要稍微复杂一些。
在混合模型中,guestVM访问设备的请求依然是会被VMM“截获”,根据I/O编址类型的不同,截获的方法也不一样。
对于I/O单独编址的PMIO(PortMappedI/O),是使用in/out,ins/outs指令来读写的,所以只需要将这几个指令设定为会产生VMexit的敏感指令就可以了。
对于和memory统一编址的MMIO(MemoryMapedI/O),如果不为其使用的I/O地址设置对应的页表项,那么在访问这些地址的时候势必会产生pagefault,这样的I/O访问也可以被VMM成功截获。
如果是一些简单的外设,比如RTC(参考这篇文章),VMM只需要读取一下现在硬件RTC的时间信息,返回给guestVM就可以了。
如果是比较复杂的外设,VMM中没有相应的驱动,那么它就会把这个请求转发给一个拥有该设备驱动程序的guestVM,在Xen中,承担这个角色的VM是Dom0,其他的guestVM则是DomU,分别对应Acrn中的SOS(ServiceOS)和UOS(UserOS)。
上图描述的是Acrnhypervisor中I/O处理的流程,当UOS发出访问I/O的请求触发VMexit后,VMM将解析产生VMexit的原因,并判断这个I/O请求是不是自己能提供驱动服务的,如果是(图的左下部分),就直接调用对应的I/Ohandler处理,如果不是(图的右下部分),就提交一个I/Orequest给SOS。
由SOS为UOS提供设备的驱动服务,就相当于实现了对UOS所使用I/O的模拟。
在这个过程中,VMM只是起了一个中间调度的作用,并不直接参与驱动数据的传输,用通信的数据来说就是,VMM负责的是"controlplane",而"dataplane"则留给了SOS和UOS自己去实现。
SOS和UOS之间关于驱动数据的交互可以有很多种方式,目前最常用的一种方式是virtio。
Virtio最早由RustyRussell于2007年在IBM工作期间开发,之后迅速成为KVM等主流虚拟化方案中默认的I/O虚拟化机制。
还是以Acrn为例,在virtio模型中,UOS为驱动数据的交互提供的接口被称为Frontendvirtiodriver(FE),FE只需要负责建立共享缓冲区,并产生I/O请求即可。
SOS中提供的驱动交互接口则被称为Backendvirtiodriver(BE),BE会接收VMM转发的来自FE的请求,并交给SOS中的设备驱动程序处理。
当SOS中的设备驱动程序处理完成了这一请求,BE将通过VMM告知对接的FE。
BE和FE是一一对应的关系,共享同一个硬件设备的多个UOS会拥有独立的FE,BE实例对,并维护各自的状态信息。
BE和FE之间是通过一个被称为virtqueue的结构来传递驱动数据的。
一个驱动程序可以使用一个或多个virtqueue,其数量取决于具体的需求,比如virtio网络驱动程序通常使用两个virtqueue(一个用于接收,另一个用于发送),而virtio块驱动程序则通常只使用一个virtqueue。
virtqueue由ringbuffer和descriptor机制组成,本质上是一块基于授权机制的共享内存,由请求服务的FE创建。
作为一个standard,同时考虑到扩展性,它会包含一些featurebits,需要BE和FE之间就此进行negotiate。
一个guestVM可以申明它所拥有的哪些内存页可以被其他VM共享,另一个VM可以将这些内存页映射到自己的地址空间中。
每个VM都有一个授权表,来控制其他VM访问自己所拥有的共享页的权限,授权表的每个entry定义了对于当前VM的某一内存页,其他的某个VM具有哪些访问权限(读/写)。
这里介绍的deviceemlution需要修改guestOS的代码,将普通的设备驱动程序转换为FE和BE的形式,因此属于I/Oparavirtualization(I/O半/类/准虚拟化),而对guestOS完全透明的模拟方式则属于I/Ofullvirtualization(I/O全虚拟化)。
要想使用I/O全虚拟化,必须从设备硬件的最底层开始模拟,尽管这样可以模拟得很彻底,以至于guestOS完全不会感知到自己是运行在一个模拟环境中,但它的效率相对较低。
结合上文讲的I/O透传,三者的实现原理分别大概是这样的:
 升级会员
升级会员 