生成AWR报告操作步骤.docx
《生成AWR报告操作步骤.docx》由会员分享,可在线阅读,更多相关《生成AWR报告操作步骤.docx(13页珍藏版)》请在冰豆网上搜索。
生成AWR报告操作步骤
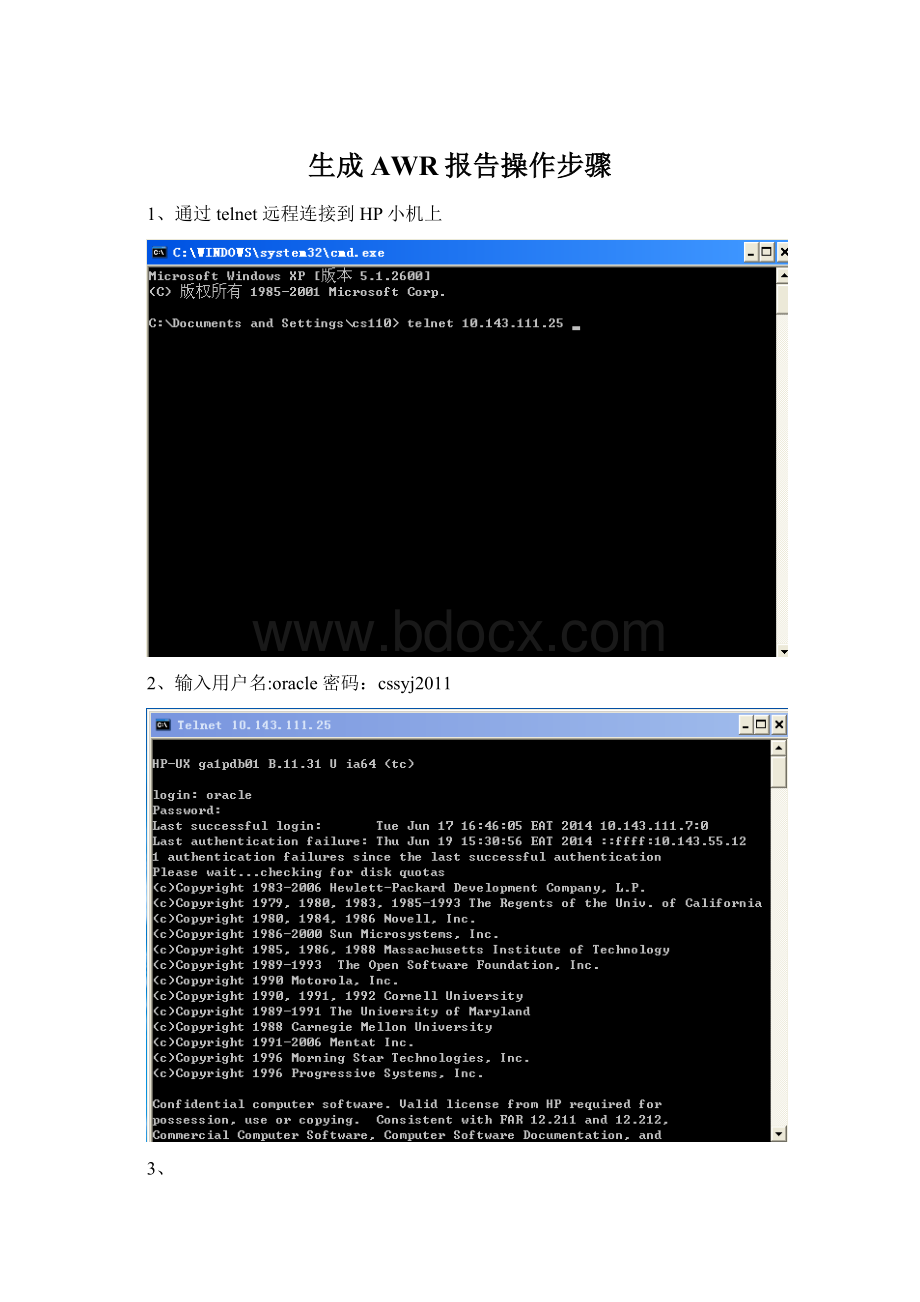
1、通过telnet远程连接到HP小机上
2、输入用户名:
oracle密码:
cssyj2011
3、
4、执行@awrrpti.sql脚本,report_type:
处直接敲回车键。
在dbid处输入:
DBId显示的数字3249394952后,敲回车键
在inst_num处输入对应的实例号,截图oracle部署的是RAC集群,因此有2个实例,这里输入:
1,对应第1个实例。
在num_days处输入对应的天数,表示需要统计的天数,下图所示统计最近30天,若想统计所有天数的信息,则无需输入数字,直接敲回车即可。
输入30后,敲回车会生成下图所示1长串信息。
begin_snap处输入需要统计的快照(Snap)起始ID,如下图所示21496
end_snap处输入需要统计的快照(Snap)结束ID,如下图所示21504
输入完上图所示信息后,直接敲回车键,在report_name:
处直接敲回车键后,会开始生成awr报告。
生成完毕会输出上图所示的Reportwrittentoawrrpt_1_21496_21504.html名称。
该AWR报告默认生成在上面执行awrrpti.sql脚本的目录下。
该机器已配置好FTP服务,直接通过FTP即可找到该文件,用户名输入:
root,密码:
cssyj2011
登录进去后,进入到oracle/product/10.2.0/db_1/rdbms/admin/目录下,鼠标右键排列图标,修改时间,找到刚生成的名字叫awrrpt_1_21496_21504.htm的报告。
该awr报告用浏览器直接打开进行分析。
以下是AWR各部分代表的意思说明:
DBName
DBId
Instance
Instnum
StartupTime
Release
RAC
Db10
663168021
Db10
1
28-5月 -1222:
05
11.2.0.1.0
NO
HostName
Platform
CPUs
Cores
Sockets
Memory(GB)
PC-200910080511
MicrosoftWindowsIA(32-bit)
2
2
1
.75
SnapId
SnapTime
Sessions
Cursors/Session
BeginSnap:
73
28-5月 -1222:
28:
57
23
1.5
EndSnap:
74
28-5月 -1223:
00:
43
23
1.5
Elapsed:
31.76(mins)
DBTime:
0.10(mins)
DBName :
数据库名字 DBid:
数据库id
DBTime不包括Oracle后台进程消耗的时间。
如果DBTime远远小于Elapsed时间,说明数据库比较空闲。
在31分钟里,数据库耗时0.1分钟,数据中显示系统有2个CPU
LoadProfile
PerSecond
PerTransaction
PerExec
PerCall
DBTime(s):
0.0
0.0
0.00
0.02
DBCPU(s):
0.0
0.0
0.00
0.02
Redosize:
5,896.4
59,450.5
Logicalreads:
71.9
724.7
Blockchanges:
41.1
414.7
Physicalreads:
2.2
21.9
Physicalwrites:
0.9
9.2
Usercalls:
0.2
1.8
Parses:
3.7
37.6
Hardparses:
0.3
2.5
W/AMBprocessed:
0.0
0.2
Logons:
0.1
0.6
Executes:
8.1
81.7
Rollbacks:
0.0
0.0
Transactions:
0.1
LoadProfile
PerSecond PerTransaction
这两部分是数据库资源负载的一个明细列表,分割成每秒钟的资源负载和每个事务的资源负载情况,性能指标的含义如下:
redosize:
每秒/每个事务产生的redo量(单位字节)
logicalreads:
每秒/每个事务产生的逻辑读的块数
blockchanges:
每秒/每个事务改变的数据块数
physicalreads:
每秒/每个事务产生的物理读
physicalwrites:
每秒/每个事务产生的物理写的块数
usercalls:
每秒/每个事务用户的调用次数
parses:
每秒/每个事务分析次数
hardparses:
每秒/每个事务硬分析次数
sorts:
每秒/每个事务排序次数
logons:
每秒/每个事务登录数据库次数
executes:
每秒/每个事务SQL的执行次数
rollbacks:
每秒/每个事物回滚次数
transactions:
每秒的事务数
InstanceEfficiencyPercentages(Target100%)
BufferNowait%:
100.00
RedoNoWait%:
100.00
BufferHit%:
96.98
In-memorySort%:
100.00
LibraryHit%:
90.91
SoftParse%:
93.27
ExecutetoParse%:
53.96
LatchHit%:
99.99
ParseCPUtoParseElapsd%:
64.26
%Non-ParseCPU:
67.81
BufferNowait:
表示在内存获得数据的未等待比例。
bufferhit:
表示进程从内存中找到数据块的比率,内存数据块命中率
RedoNoWait:
表示在LOG缓冲区获得BUFFER的未等待比例。
libraryhit:
表示共享池中SQL解析的命中率
LatchHit:
Latch是一种保护内存结构的锁,可以认为是SERVER进程获取访问内存数据结构的许可。
ParseCPUtoParseElapsd:
解析总时间中消耗总CPU的时间百分比
Non-ParseCPU :
SQL实际运行时间/(SQL实际运行时间+SQL解析时间),太低表示解析消耗时间过多。
ExecutetoParse:
是语句执行与分析的比例,如果要SQL重用率高,则这个比例会很高。
该值越高表示一次解析后被重复执行的次数越多。
In-memorySort:
在内存中排序的比率,如果过低说明有大量的排序在临时表空间中进行。
考虑调大PGA。
SoftParse:
软解析的百分比(softs/softs+hards),近似当作sql在共享区的命中率,太低则需要调整应用使用绑定变量。
SharedPoolStatistics
Begin
End
MemoryUsage%:
84.18
83.00
%SQLwithexecutions>1:
74.54
76.34
%MemoryforSQLw/exec>1:
78.06
73.38
MemoryUsage%:
对于一个已经运行一段时间的数据库来说,共享池内存使用率,应该稳定在75%-90%间,如果太小,说明SharedPool有浪费,而如果高于90,说明共享池中有争用,内存不足。
SQLwithexecutions>1:
执行次数大于1的sql比率,如果此值太小,说明需要在应用中更多使用绑定变量,避免过多SQL解析。
MemoryforSQLw/exec>1:
执行次数大于1的SQL消耗内存的占比。
Top5TimedForegroundEvents
Event
Waits
Time(s)
Avgwait(ms)
%DBtime
WaitClass
DBCPU
5
87.64
dbfilesequentialread
258
1
5
22.30
UserI/O
librarycacheloadlock
1
0
87
1.45
Concurrency
dbfilescatteredread
17
0
3
0.85
UserI/O
logfilesync
35
0
1
0.77
Commit
这是报告概要的最后一节,显示了系统中最严重的5个等待,按所占等待时间的比例倒序列示。
当我们调优时,总希望观察到最显著的效果,因此应当从这里入手确定我们下一步做什么。
通常,在没有问题的数据库中,CPUtime总是列在第一个
SQLStatistics
∙SQLorderedbyElapsedTime
∙SQLorderedbyCPUTime
∙SQLorderedbyUserI/OWaitTime
∙SQLorderedbyGets
∙SQLorderedbyReads
∙SQLorderedbyPhysicalReads(UnOptimized)
∙SQLorderedbyExecutions
∙SQLorderedbyParseCalls
∙SQLorderedbySharableMemory
∙SQLorderedbyVersionCount
∙CompleteListofSQLText
二、解析报告
1.SQLorderedbyElapsedTime:
记录了执行总和时间的TOPSQL(请注意是监控范围内该SQL的执行时间总和,而不是单次SQL执行时间 ElapsedTime=CPUTime+WaitTime)
ElapsedTime(S):
SQL语句执行用总时长,此排序就是按照这个字段进行的。
注意该时间不是单个SQL跑的时间,而是监控范围内SQL执行次数的总和时间。
单位时间为秒。
ElapsedTime=CPUTime+WaitTime
CPUTime(s):
为SQL语句执行时CPU占用时间总时长,此时间会小于等于ElapsedTime时间。
单位时间为秒。
Executions:
SQL语句在监控范围内的执行次数总计。
ElapperExec(s):
执行一次SQL的平均时间。
单位时间为秒。
%TotalDBTime:
为SQL的ElapsedTime时间占数据库总时间的百分比。
SQLID:
SQL语句的ID编号,点击之后就能导航到下边的SQL详细列表中,点击IE的返回可以回到当前SQLID的地方。
SQLModule:
显示该SQL是用什么方式连接到数据库执行的,如果是用SQL*Plus或者PL/SQL链接上来的那基本上都是有人在调试程序。
一般用前台应用链接过来执行的sql该位置为空。
SQLText:
简单的sql提示,详细的需要点击SQLID。
2.SQLorderedbyCPUTime:
记录了执行占CPU时间总和时间最长的TOPSQL(请注意是监控范围内该SQL的执行占CPU时间总和,而不是单次SQL执行时间)。
3.SQLorderedbyGets:
记录了执行占总buffergets(逻辑IO)的TOPSQL(请注意是监控范围内该SQL的执行占Gets总和,而不是单次SQL执行所占的Gets).
4.SQLorderedbyReads:
记录了执行占总磁盘物理读(物理IO)的TOPSQL(请注意是监控范围内该SQL的执行占磁盘物理读总和,而不是单次SQL执行所占的磁盘物理读)。
5.SQLorderedbyExecutions:
记录了按照SQL的执行次数排序的TOPSQL。
该排序可以看出监控范围内的SQL执行次数。
6.SQLorderedbyParseCalls:
记录了SQL的软解析次数的TOPSQL。
7.SQLorderedbySharableMemory:
记录了SQL占用librarycache的大小的TOPSQL。
SharableMem(b):
占用librarycache的大小。
单位是byte。
8.SQLorderedbyVersionCount:
记录了SQL的打开子游标的TOPSQL。
 升级会员
升级会员 