大叔的大数据面试题.docx
《大叔的大数据面试题.docx》由会员分享,可在线阅读,更多相关《大叔的大数据面试题.docx(14页珍藏版)》请在冰豆网上搜索。
大叔的大数据面试题
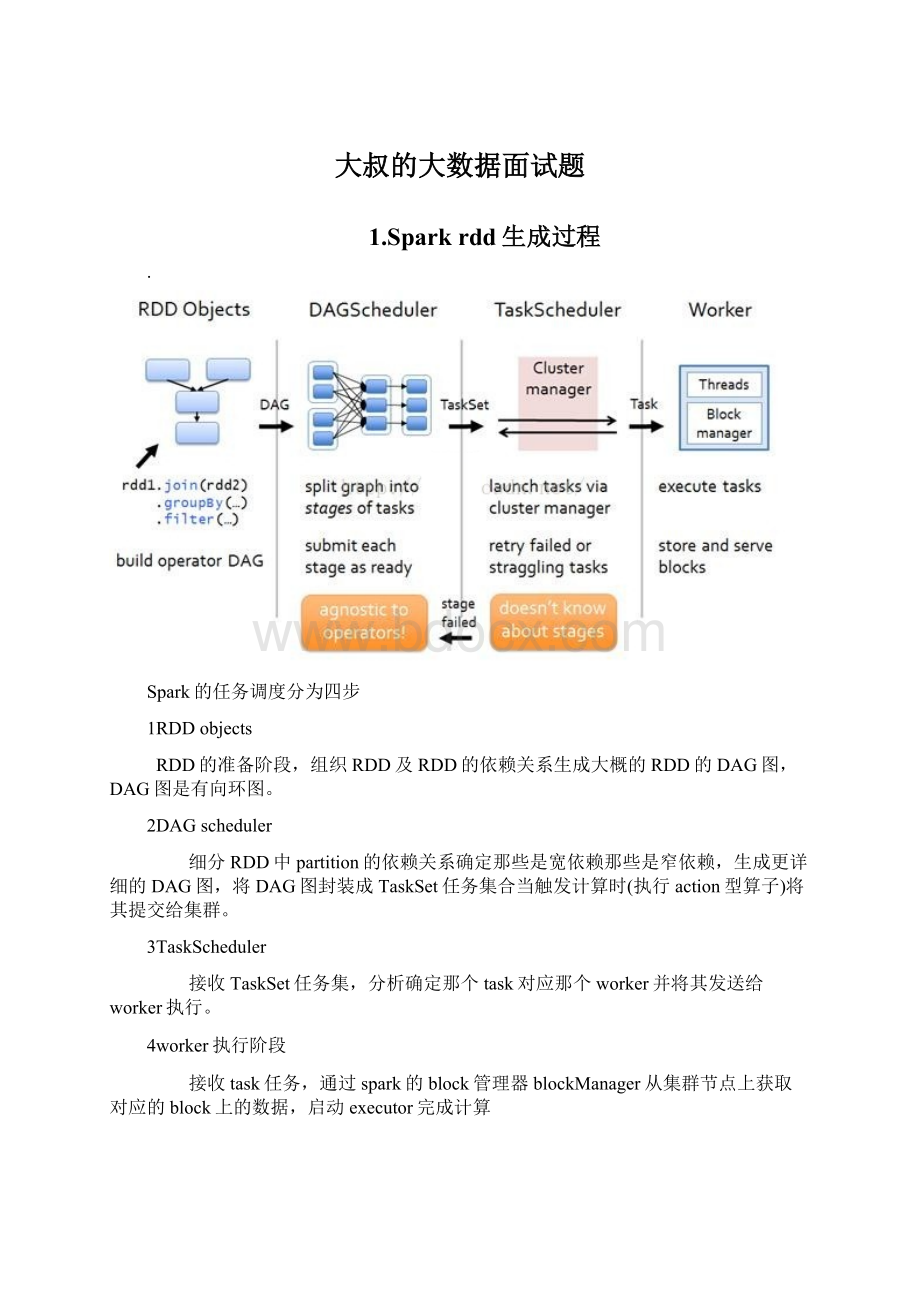
1.Sparkrdd生成过程
∙
Spark的任务调度分为四步
1RDDobjects
RDD的准备阶段,组织RDD及RDD的依赖关系生成大概的RDD的DAG图,DAG图是有向环图。
2DAGscheduler
细分RDD中partition的依赖关系确定那些是宽依赖那些是窄依赖,生成更详细的DAG图,将DAG图封装成TaskSet任务集合当触发计算时(执行action型算子)将其提交给集群。
3TaskScheduler
接收TaskSet任务集,分析确定那个task对应那个worker并将其发送给worker执行。
4worker执行阶段
接收task任务,通过spark的block管理器blockManager从集群节点上获取对应的block上的数据,启动executor完成计算
2.Spark任务提交流程
2.spark-submit命令提交程序后,driver和application也会向Master注册信息
3.创建SparkContext对象:
主要的对象包含DAGScheduler和TaskScheduler
4.Driver把Application信息注册给Master后,Master会根据App信息去Worker节点启动Executor
5.Executor内部会创建运行task的线程池,然后把启动的Executor反向注册给Dirver
6.DAGScheduler:
负责把Spark作业转换成Stage的DAG(DirectedAcyclicGraph有向无环图),根据宽窄依赖切分Stage,然后把Stage封装成TaskSet的形式发送个TaskScheduler;
同时DAGScheduler还会处理由于Shuffle数据丢失导致的失败;
7.TaskScheduler:
维护所有TaskSet,分发Task给各个节点的Executor(根据数据本地化策略分发Task),监控task的运行状态,负责重试失败的task;
8.所有task运行完成后,SparkContext向Master注销,释放资源;
3.Sparksql创建分区表
spark.sql("useoracledb")
spark.sql("CREATETABLEIFNOTEXISTS"+tablename+"(OBUIDSTRING,BUS_IDSTRING,REVTIMESTRING,OBUTIMESTRING,LONGITUDESTRING,LATITUDESTRING,\
GPSKEYSTRING,DIRECTIONSTRING,SPEEDSTRING,RUNNING_NOSTRING,DATA_SERIALSTRING,GPS_MILEAGESTRING,SATELLITE_COUNTSTRING,ROUTE_CODESTRING,SERVICESTRING)\
PARTITIONEDBY(areaSTRING,obudateSTRING)ROWFORMATDELIMITEDFIELDSTERMINATEDBY','")
#设置参数
#hive>sethive.exec.dynamic.partition.mode=nonstrict;
#hive>sethive.exec.dynamic.partition=true;
spark.sql("sethive.exec.dynamic.partition.mode=nonstrict")
spark.sql("sethive.exec.dynamic.partition=true")
#print("创建数据库完成")
ifaddoroverwrite:
#追加
spark.sql("INSERTINTOTABLE"+tablename+"PARTITION(area,obudate)SELECTOBUID,BUS_ID,REVTIME,OBUTIME,LONGITUDE,LATITUDE,GPSKEY,DIRECTION,SPEED,\
RUNNING_NO,DATA_SERIAL,GPS_MILEAGE,SATELLITE_COUNT,ROUTE_CODE,SERVICE,'gz'ASarea,SUBSTR(OBUTIME,1,10)ASobudateFROM"+tablename+"_tmp")
4.Java同步锁有哪些
Synchronizedlock
5.Arrarylist能存null吗
可以添加的数据类型位object类型null也是object类型
6.Springcloud控制权限
SpringCloud下的微服务权限怎么管?
怎么设计比较合理?
从大层面讲叫服务权限,往小处拆分,分别为三块:
用户认证、用户权限、服务校验。
7.Hashsetcontains方法
contains方法用来判断Set集合是否包含指定的对象。
语法 booleancontains(Objecto)
返回值:
如果Set集合包含指定的对象,则返回true;否则返回false。
8.Sparkstreaming数据块大小
buffer32k //缓冲区默认大小为32k SparkConf.set("spark.shuffle.file.buffer","64k")
reduce 48M //reduce端拉取数据的时候,默认大小是48M SparkConf.set("spark.reducer.maxSizeInFlight","96M")
spark.shuffle.file.buffer
默认值:
32k
参数说明:
该参数用于设置shufflewritetask的BufferedOutputStream的buffer缓冲大小。
将数据写到磁盘文件之前,会先写入buffer缓冲中,待缓冲写满之后,才会溢写到磁盘。
调优建议:
如果作业可用的内存资源较为充足的话,可以适当增加这个参数的大小(比如64k),从而减少shufflewrite过程中溢写磁盘文件的次数,也就可以减少磁盘IO次数,进而提升性能。
在实践中发现,合理调节该参数,性能会有1%~5%的提升。
spark.reducer.maxSizeInFlight
默认值:
48m
参数说明:
该参数用于设置shufflereadtask的buffer缓冲大小,而这个buffer缓冲决定了每次能够拉取多少数据。
调优建议:
如果作业可用的内存资源较为充足的话,可以适当增加这个参数的大小(比如96m),从而减少拉取数据的次数,也就可以减少网络传输的次数,进而提升性能。
在实践中发现,合理调节该参数,性能会有1%~5%的提升。
错误:
reduceoom
reducetask去map拉数据,reduce一边拉数据一边聚合 reduce段有一块聚合内存(executormemory*0.2)
解决办法:
1、增加reduce聚合的内存的比例 设置spark.shuffle.memoryFraction
2、增加executormemory的大小 --executor-memory5G
3、减少reducetask每次拉取的数据量 设置spark.reducer.maxSizeInFlight 24m
9.GC
JavaGC(GarbageCollection,垃圾收集,垃圾回收)机制,是Java与C++/C的主要区别之一,在使用JAVA的时候,一般不需要专门编写内存回收和垃圾清理代码。
这是因为在Java虚拟机中,存在自动内存管理和垃圾清扫机制。
10.Flume的推拉怎么保证数据的完整性
channel做持久化
11.Java1/0.0infinity
在浮点数运算时,有时我们会遇到除数为0的情况,那java是如何解决的呢?
我们知道,在整型运算中,除数是不能为0的,否则直接运行异常。
但是在浮点数运算中,引入了无限这个概念,我们来看一下Double和Float中的定义。
1.无限乘以0,结果为NAN
System.out.println(Float.POSITIVE_INFINITY*0);//output:
NAN
System.out.println(Float.NEGATIVE_INFINITY*0);//output:
NAN
2.无限除以0,结果不变,还是无限
System.out.println((Float.POSITIVE_INFINITY/0)==Float.POSITIVE_INFINITY);//output:
true
System.out.println((Float.NEGATIVE_INFINITY/0)==Float.NEGATIVE_INFINITY);//output:
true
3.无限做除了乘以0意外的运算,结果还是无限
System.out.println(Float.POSITIVE_INFINITY==(Float.POSITIVE_INFINITY+10000));//output:
true
System.out.println(Float.POSITIVE_INFINITY==(Float.POSITIVE_INFINITY-10000));//output:
true
System.out.println(Float.POSITIVE_INFINITY==(Float.POSITIVE_INFINITY*10000));//output:
true
System.out.println(Float.POSITIVE_INFINITY==(Float.POSITIVE_INFINITY/10000));//output:
true
要判断一个浮点数是否为INFINITY,可用isInfinite方法
System.out.println(Double.isInfinite(Float.POSITIVE_INFINITY));//output:
true
12.(int)(char)(byte)-1=65535
publicclassT{
publicstaticvoidmain(Stringargs[]){
newT().toInt(-1);
newT().toByte((byte)-1);
newT().toChar((char)(byte)-1);
newT().toInt((int)(char)(byte)-1);
}
voidtoByte(byteb){
for(inti=7;i>=0;i--){
System.out.print((b>>i)&0x01);
}
System.out.println();
}
voidtoInt(intb){
for(inti=31;i>=0;i--){
System.out.print((b>>i)&0x01);
}
System.out.println();
}
voidtoChar(charb){
for(inti=15;i>=0;i--){
System.out.print((b>>i)&0x01);
}
System.out.println();
}
}
111111*********11111111111111111
11111111
111111*********1
00000000000000001111111111111111
13.Sparkshuffle时是否会在磁盘存储
会
14.Hive的函数
例如casewhen
15.Hadoop的shuffle会进行几次排序
16.Shuffle发生在哪里
hadoop的核心思想是MapReduce,但shuffle又是MapReduce的核心。
shuffle的主要工作是从Map结束到Reduce开始之间的过程。
首先看下这张图,就能了解shuffle所处的位置。
图中的partitions、copyphase、sortphase所代表的就是shuffle的不同阶段。
17.spark怎么杀死已经提交的任务
18.提交spark任务可以设置哪些参数
19.Zookeeper有3个进程都是做什么的
Zookeeper主要可以干哪些事情:
配置管理,名字服务,提供分布式同步以及集群管理。
20.Kafka的三种传数据的方式,各有什么优缺点
1.最多一次(At-most-once):
客户端收到消息后,在处理消息前自动提交,这样kafka就认为consumer已经消费过了,偏移量增加。
2.最少一次(At-least-once):
客户端收到消息,处理消息,再提交反馈。
这样就可能出现消息处理完了,在提交反馈前,网络中断或者程序挂了,那么kafka认为这个消息还没有被consumer消费,产生重复消息推送。
3.正好一次(Exaxtly-once):
保证消息处理和提交反馈在同一个事务中,即有原子性。
本文从这几个点出发,详细阐述了如何实现以上三种方式。
21.Flume的拦截插件怎么编写
建一个maven工程,导入flume-core包,然后实现interceptor接口
22.Hadoop的小文件聚合怎么实现
Hadoop自身提供了几种机制来解决相关的问题,包括HAR,SequeueFile和CombineFileInputFormat。
23.Sparkrdd存储数据吗?
RDD其实是不存储真实数据的,存储的的只是真实数据的分区信息getPartitions,还有就是针对单个分区的读取方法 compute
24.实现map的线程同步方法
实现同步机制有两个方法:
1、同步代码块:
synchronized(同一个数据){}同一个数据:
就是N条线程同时访问一个数据。
2、同步方法:
publicsynchronized数据返回类型方法名(){}
就是使用synchronized来修饰某个方法,则该方法称为同步方法。
对于同步方法而言,无需显示指定同步监视器,同步方法的同步监视器是this也就是该对象的本身(这里指的对象本身有点含糊,其实就是调用该同步方法的对象)通过使用同步方法,可非常方便的将某类变成线程安全的类,具有如下特征:
1,该类的对象可以被多个线程安全的访问。
2,每个线程调用该对象的任意方法之后,都将得到正确的结果。
3,每个线程调用该对象的任意方法之后,该对象状态依然保持合理状态。
注:
synchronized关键字可以修饰方法,也可以修饰代码块,但不能修饰构造器,属性等。
实现同步机制注意以下几点:
安全性高,性能低,在多线程用。
性能高,安全性低,在单线程用。
1,不要对线程安全类的所有方法都进行同步,只对那些会改变共享资源方法的进行同步。
2,如果可变类有两种运行环境,当线程环境和多线程环境则应该为该可变类提供两种版本:
线程安全版本和线程不安全版本(没有同步方法和同步块)。
在单线程中环境中,使用线程不安全版本以保证性能,在多线程中使用线程安全版本.
25.Combiner的组件需要注意什么
因为combiner在mapreduce过程中可能调用也肯能不调用,可能调一次也可能调多次,无法确定和控制
所以,combiner使用的原则是:
有或没有都不能影响业务逻辑,使不使用combiner都不能影响最终reducer的结果。
而且,combiner的输出kv应该跟reducer的输入kv类型要对应起来。
因为有时使用combiner不当的话会对统计结果造成错误的结局,还不如不用。
比如对所有数求平均数:
Mapper端使用combiner
357->(3+5+7)/3=5
26->(2+6)/2=4
Reducer
(5+4)/2=9/2 不等于(3+5+7+2+6)/5=23/5
26.Storm和sparkstreaming之间的对比
Storm
1)真正意义上的实时处理。
(实时性)
2)想实现一些复杂的功能,比较麻烦,比如:
实现滑动窗口 (易用性)
原生的API:
spoutboltbolt
Trident框架:
使用起来难度还是有一些。
3)没有一个完整的生态
SparkStreaming
1)有批处理的感觉,一次处理的数据量较小,然后基于内存很快就可以运行完成。
相当于是准实时。
(实时性)
2)封装了很多高级的API,在用户去实现一个复杂的功能的时候,很容易就可以实现。
(易用性)
3)有完整的生态系统。
同时可以配置SparkCore,SparkSQL,Mlib,GraphX等,他们之间可以实现无缝的切换。
做一个比喻来说明这两个的区别:
Storm就像是超市里面的电动扶梯,实时的都在运行;
SparkStreaming就像是超市里面的电梯,每次载一批人。
27.Hdp在进行容灾性测试时,会出现什么问题吗
AmbariServer是存在单点问题的,如果Server机器宕机了,就无法恢复整个AmbariServer的数据,也就是说无法再通过Ambari管理集群。
28.Kafka的数据流读取速度快的原因是什么,为什么选择kafka,而不是别的消息中间件
生产者(写入数据)
生产者(producer)是负责向Kafka提交数据的,我们先分析这一部分。
Kafka会把收到的消息都写入到硬盘中,它绝对不会丢失数据。
为了优化写入速度Kafak采用了两个技术,顺序写入和MMFile。
顺序写入
因为硬盘是机械结构,每次读写都会寻址->写入,其中寻址是一个“机械动作”,它是最耗时的。
所以硬盘最“讨厌”随机I/O,最喜欢顺序I/O。
为了提高读写硬盘的速度,Kafka就是使用顺序I/O。
29.Spark与hadoop对比,有哪些优势
1)Spark相比Hadoop在处理模型上的优势
首先,Spark摒弃了MapReduce先map再reduce这样的严格方式,Spark引擎执行更通用的有向无环图(DAG)算子。
另外,基于MR的计算引擎在shuffle过程中会将中间结果输出到磁盘上,进行存储和容错,而且HDFS的可靠机制是将文件存为3份。
Spark是将执行模型抽象为通用的有向无环图执行计划(DAG),当到最后一步时才会进行计算,这样可以将多stage的任务串联或者并行执行,而无须将stage中间结果输出到HDFS。
磁盘IO的性能明显低于内存,所以Hadoop的运行效率低于spark。
2)数据格式和内存布局
MR在读的模型处理方式上会引起较大的处理开销,spark抽象出弹性分布式数据集RDD,进行数据的存储。
RDD能支持粗粒度写操作,但对于读取操作,RDD可以精确到每条记录,这使得RDD可以用来作为分布式索引。
Spark的这些特性使得开发人员能够控制数据在不同节点上的不同分区,用户可以自定义分区策略,如hash分区等。
3)执行策略
MR在数据shuffle之前花费了大量的时间来排序,spark可减轻这个开销。
因为spark任务在shuffle中不是所有的场合都需要排序,所以支持基于hash的分布式聚合,调度中采用更为通用的任务执行计划图(DAG),每一轮次的输出结果都在内存中缓存。
4)任务调度的开销
传统的MR系统,是为了运行长达数小时的批量作业而设计的,在某些极端情况下,提交一个任务的延迟非常高。
Spark采用了时间驱动的类库AKKA来启动任务,通过线程池复用线程来避免进程或线程启动和切换开销。
5)内存计算能力的扩展
spark的弹性分布式数据集(RDD)抽象使开发人员可以将处理流水线上的任何点持久化存储在跨越集群节点的内存中,来保证后续步骤需要相同数据集时就不必重新计算或从磁盘加载,大大提高了性能。
这个特性使Spark非常适合涉及大量迭代的算法,这些算法需要多次遍历相同数据集,也适用于反应式(reactive)应用,这些应用需要扫描大量内存数据并快速响应用户的查询。
6)开发速度的提升
构建数据应用的最大瓶颈不是CPU、磁盘或者网络,而是分析人员的生产率。
所以spark通过将预处理到模型评价的整个流水线整合在一个编程环境中,大大加速了开发过程。
Spark编程模型富有表达力,在REPL下包装了一组分析库,省去了多次往返IDE的开销。
而这些开销对诸如MapReduce等框架来说是无法避免的。
Spark还避免了采样和从HDFS来回倒腾数据所带来的问题,这些问题是R之类的框架经常遇到的。
分析人员在数据上做实验的速度越快,他们能从数据中挖掘出价值的可能性就越大。
7)功能强大
作为一个通用的计算引擎,spark的核心API为数据转换提供了强大的基础,它独立于统计学、机器学习或矩阵代数的任何功能。
而且它的Scala和PythonAPI让我们可以用表达力极强的通用编程语言编写程序,还可以访问已有的库。
Spark的内存缓存使它适应于微观和宏观两个层面的迭代计算。
机器学习算法需要多次遍历训练集,可以将训练集缓存在内存里。
在对数据集进行探索和初步了解时,数据科学家可以在运行查询的时候将数据集放在内存,也很容易将转换后的版本缓存起来,这样可以节省访问磁盘的开销。
30.Javahash冲突怎么解决
1)开放定址法:
2)链地址法3、4)再哈希、建立公共溢出区
 升级会员
升级会员 