树和图.docx
《树和图.docx》由会员分享,可在线阅读,更多相关《树和图.docx(14页珍藏版)》请在冰豆网上搜索。
树和图
树和图
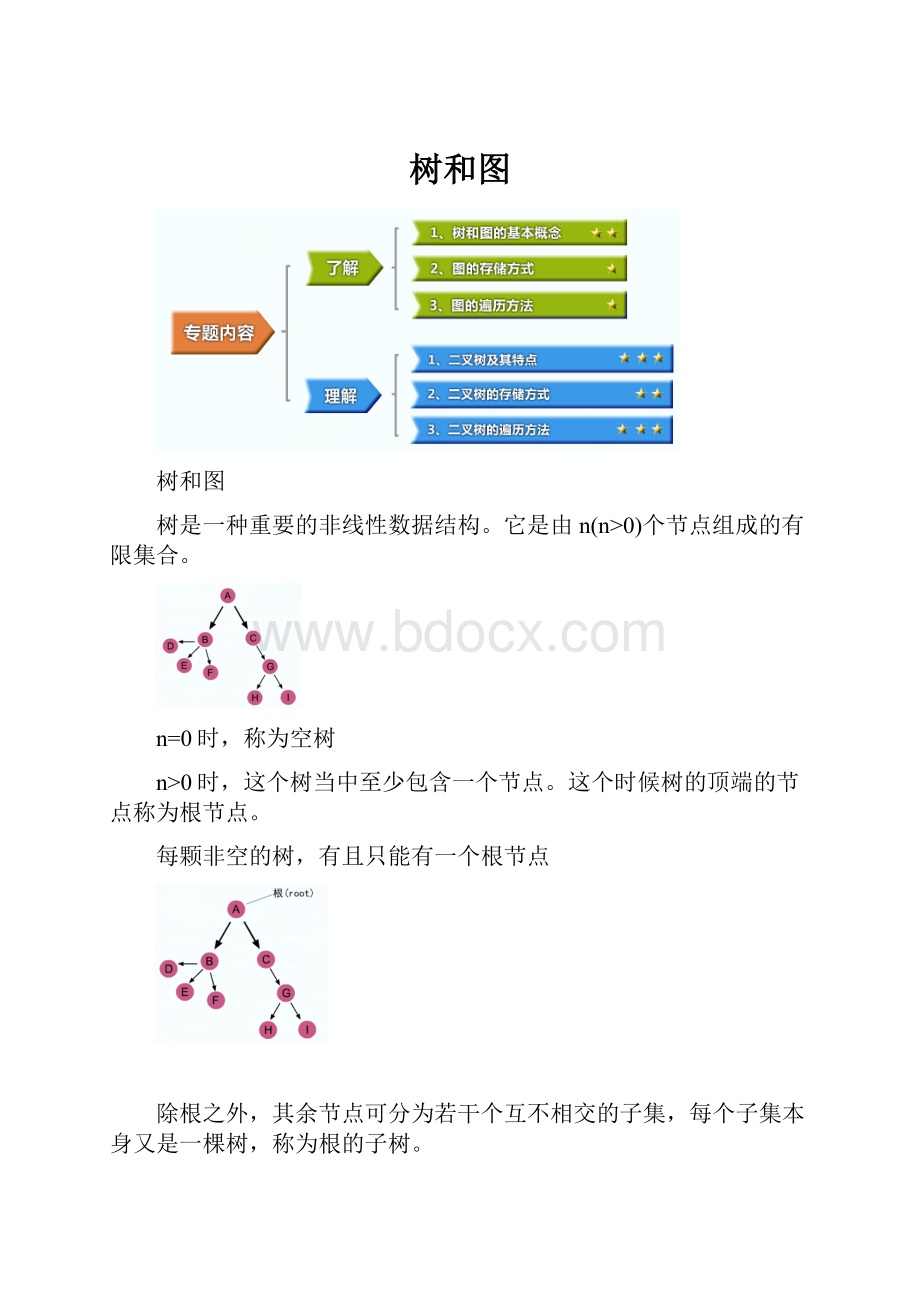
树是一种重要的非线性数据结构。
它是由n(n>0)个节点组成的有限集合。
n=0时,称为空树
n>0时,这个树当中至少包含一个节点。
这个时候树的顶端的节点称为根节点。
每颗非空的树,有且只能有一个根节点
除根之外,其余节点可分为若干个互不相交的子集,每个子集本身又是一棵树,称为根的子树。
我们把节点拥有子树的数量称为这个节点的度。
例如上图:
A有两棵子树,所以A的度数为2
B节点度数为3
度数为0的节点我们称为叶子节点(叶节点)
在树当中所有节点中的最大度数称为这颗树的度
上图所示最大度数是3
在一个树当中节点的数量之和总是等于节点的度数之和加上1
树中描述一个节点与根节点的距离:
层
节点的层反映该节点在树中的位置
在树中任意一个层数为k(k>0)的节点B都有一个层数为k-1的结点A与之对应,B称为A的子节点,A称为B的父节点。
同一个节点的孩子互称兄弟
如果两个节点的父节点不同,但是在同一层次上,那么他们互称堂兄弟
树中各个节点之间的连线称为边
在树中从一个节点移动到另一个节点,所经过的节点顺序称为路径
从一个树的根节点到树中任意的其他节点,总是存在唯一的路径
树的根节点到树中叶节点的最长路径的长度称为树的高
高度为3
在一棵树当中如果所有节点的子树从左到右都是有次序的,那么称这棵树为有序树。
度数为M的有序树,我们称为M叉树。
森林是指N(n为自然数)个互不相交的树的集合。
森林(Forest)是m(m≥0)棵互不相交的树的集合。
树和森林的概念相近。
删去一棵树的根,就得到一个森林;反之,加上一个结点作树根,森林就变为一棵树。
二叉树
每个节点的度数均不超过2的有序树称为二叉树。
不是二叉树,因为B节点度数为3,去掉其中任意一个就变为了二叉树。
二叉树的特点
●每个节点最多有两个子节点,度数最大为2
●节点的子树有左右之分,左边的称为左子树,右边的称为右子树。
●在第i层上,最多有2i个节点
二叉树当中叶子节点数量为n0(也就是说度数为0的节点的数量为n0)
度数为2的节点数量为n2
总结点数:
n
度数为1的节点数量:
n1
1、n=n0+n1+n22、n=1Xn1+2Xn2+1
●如果一个二叉树叶节点数量为n0,度数为2的节点数量为n2,则n0=n2+1
●高度为H(H>=0)的二叉树最多有2H+1-1个节点。
(满足这个条件的二叉树我们称为满二叉树)
完全二叉树
满二叉树一定是完全二叉树,完全二叉树不一定是满二叉树
完全二叉树就是:
如果我们在一个满二叉树的最下层,从右向左连续删除若干个叶子节点。
二叉树的存储结构
二叉树的存储结构分为:
●顺序存储
●链式存储
顺序存储:
只适合于满二叉树和完全二叉树
如果把完全二叉树的第i个节点存放在数组的第i个元素当中,那么他的父节点存储在第二分之i个位置。
他的左孩子存放在第2i个位置,右孩子存储在第2i+1个位置。
如果i是奇数,就直接取整。
在存储的非完全二叉树的时候,给他补齐空节点形成一个完全的二叉树,再根据我们的规律对实际节点进行存储,但是这样会造成资源的浪费。
这也是顺序存储的缺点。
链式存储:
例如:
二叉链表
遍历二叉树
什么叫二叉树的遍历?
二叉树的遍历是指以某种次序访问二叉树中的所有节点,并且使每个节点恰好只被访问一次。
(讨论的遍历方法都是二叉树不为空的情况)
二叉树的遍历分为:
●先序遍历
●中序遍历
●后序遍历
这三种遍历都是针对根节点来说的,也就是说先、中、后的顺序访问根节点。
先序遍历:
在遍历的过程当中,遵循三个步骤:
访问根节点
先序访问左子树(在访问左子树也要遵循先序的原则)
先序访问右子树(在访问右子树也要遵循先序的原则)
中序遍历:
在遍历的过程当中,遵循三个步骤:
中序访问左子树
访问根节点
中序访问右子树
后序遍历:
在遍历的过程当中,遵循三个步骤:
后序访问左子树
后序访问右子树
访问根节点
二叉树的遍历视频演示
图
定义:
图是一种重要的非线性数据结构,它由非空的顶点集合和一个描述顶点之间相互关系(边)的有限集合组成。
图可以用二元组定义为:
G=(V,E)
其中:
G表示一个图,V表示图中顶点的集合,E表示图中边的集合。
顶点的度是指起源于该顶点的边数。
路径
路径:
从顶点A出发经过图中其他的顶点,以及边。
到达顶点D的一个顶点序列。
并且在这个顶点序列当中,任何相邻的两个顶点之间都要有边相连。
路径上边的数量称为路径的长度
顶点V1到Vn的路径是指顶点序列V1,V2,V3….Vn,其中(V1,V2),(V2,V3)….(Vn-1,Vn)均为图中的边
在图当中我们截取图的一部分,就构成了图的子图:
在子图当中顶点的集合是原图当中顶点集合的子集。
子图边的集合也是原图边集合的子集。
在图中从一个顶点到另外一个顶点他们之间有路径,就说这个两个顶点是连通的。
在图中任意的两个顶点都是连通的图称为连通图。
权:
有些图的边附带有数据信息,这些附带的数据信息称为权。
带权的图也称为网络或网就是带权图。
图常用的存储结构有:
●邻接矩阵
●邻接表
●十字链表
●邻接多重表
邻接矩阵:
也叫数组表示法,它用来表示图中顶点之间的邻接关系。
无权图的邻接矩阵
用矩阵表示过后就是这样
无权图中只包含两种数字0和1,0表示没有边邻接的,1表示有边将两个顶点相邻接的
有权图的邻接矩阵
图的邻接矩阵视频演示
图的遍历
图的遍历也称搜索,是指从图的某个顶点出发,按照某种方法对图中的所有其他顶点进行访问,且使每个顶点仅被访问一次。
深度优先搜索
基本思想:
从某一顶点出发,沿着一条路一直搜索下去,直到不能在前进为止。
这个时候,我们再从原来的这个顶点出发,沿着另外一条路径继续搜索下去,直到在不能前进为止。
广度优先搜索
必须要遵循的一个原则:
要使先被访问的顶点的邻接点先于后被访问的顶点的邻接点被访问
总结
 升级会员
升级会员 