我国城镇居民人均消费的SPSS统计分析报告.docx
《我国城镇居民人均消费的SPSS统计分析报告.docx》由会员分享,可在线阅读,更多相关《我国城镇居民人均消费的SPSS统计分析报告.docx(25页珍藏版)》请在冰豆网上搜索。
我国城镇居民人均消费的SPSS统计分析报告
2013年我国城镇居民人均消费的SPSS统计分析
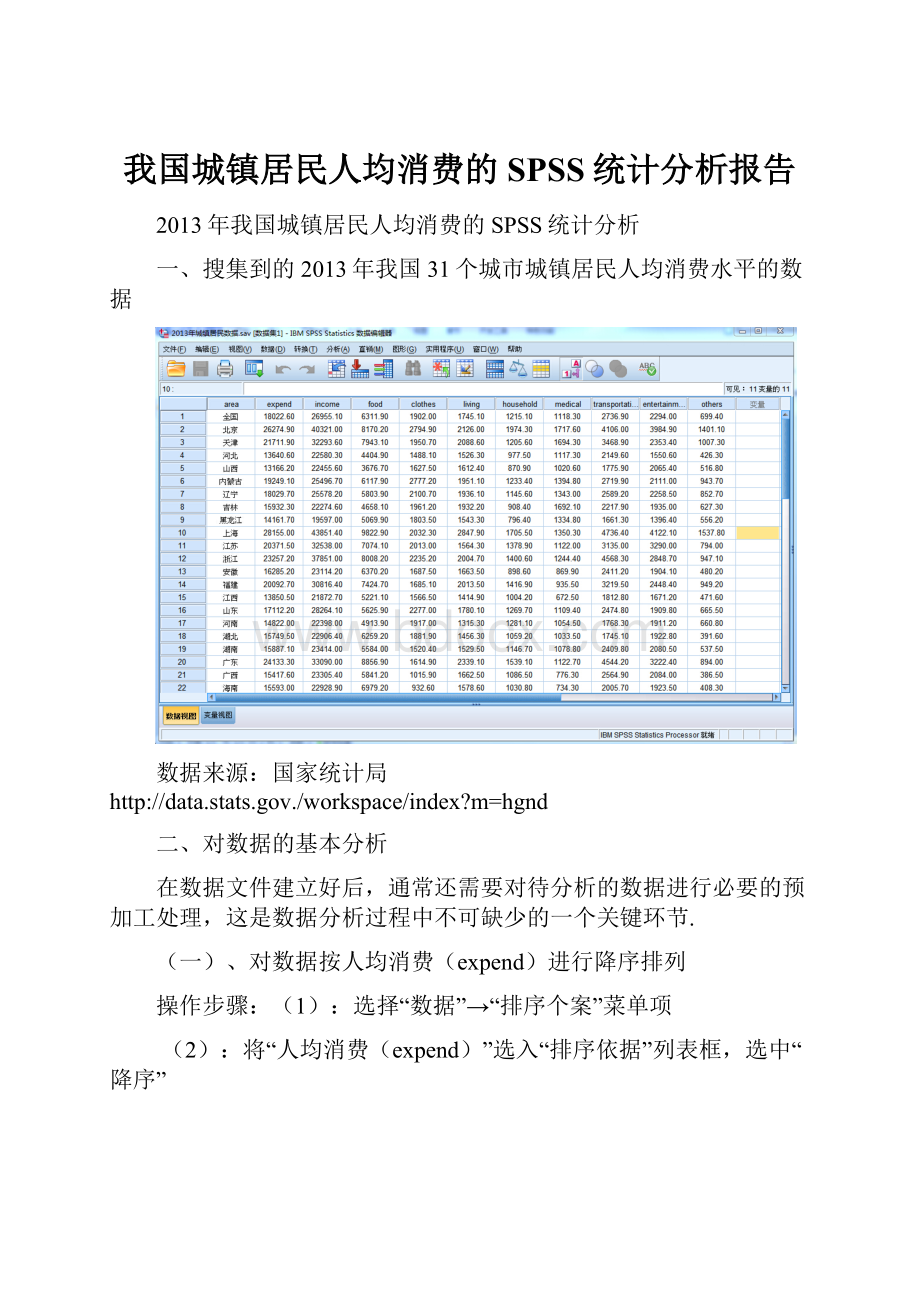
一、搜集到的2013年我国31个城市城镇居民人均消费水平的数据
数据来源:
国家统计局http:
//data.stats.gov./workspace/index?
m=hgnd
二、对数据的基本分析
在数据文件建立好后,通常还需要对待分析的数据进行必要的预加工处理,这是数据分析过程中不可缺少的一个关键环节.
(一)、对数据按人均消费(expend)进行降序排列
操作步骤:
(1):
选择“数据”→“排序个案”菜单项
(2):
将“人均消费(expend)”选入“排序依据”列表框,选中“降序”
(3):
点击“确认”按钮,生成如下降序排列的数据集
由数据的降序排列可以看出,全国只有上海、北京、等九个城市的城镇人均消费在全国城镇人均消费水平以上.
(二)、作出人均收入和人均消费的直方图
操作步骤:
(1):
选择“图形”,打开“图表构建程序”菜单项
(2):
从“库”中选择“直方图”将其拉入“图表预览使用数据实例”
(3):
将变量“地区”设置为x轴,将“人均收入”和“人均消费”设置为y轴
(4):
点击“确认”按钮,即生成如下直方图
通过一个复合条形图,可以很明确的发现我国城镇居民生活水平存在很大的地区差异,地区发展很不平衡,从图中的生活消费支出和人均收入来看,北京,上海,这些省市城镇居民消费水平最高,人均收入也是最高的,各省市的城镇居民消费水平差异较大,大多数省份城镇居民人均消费集中在15000元左右.
(三)、对数据按照人均消费作出直方图,以统计我国农村人均消费的水平
1、首先对数据分组,分组数目的确定.
按照Sturges提出的经验公式来确定组数K,K=1+
,计算得组数为6.
2、确定组距组距=(最大值-最小值)/组数=(28155.00-12231.90)/6=2653.85,可近似取值为3000.00元.
操作步骤:
(1):
选择“转换”→“可视离散化”菜单项,将“人均消费”选入“要离散的变量”列表框中,单击“继续”按钮进入主对话框.
(2):
单击“生成分割点”按钮,设定分割点数量为6,宽度为3000.00,可见系统会自动会填充第一个分割点的位置为12231.90,单击“应用”返回到主对话框.
(3):
此时可以看到下部数值标签网格里的“值”列已被自动填充,单击“生成标签”按钮,是标签列也得到自动填充.
(4):
将离散的变量名设定为expendNew.
(5):
单击“确定”按钮.
3、频数分析
操作步骤:
(1):
选择“分析”→“描述统计”→“频率”,打开频率对话框.
(2):
选定“expendNew”,点击“图表”,选择“条形图”点击继续.
(3):
点击“确认”,生成如下三表.
Statistics
人均消费(已离散化)
N
Valid
32
Missing
0
Mean
3.13
Median
3.00
Std.Deviation
1.314
Minimum
1
Maximum
7
Percentiles
25
2.00
50
3.00
75
3.75
人均消费(已离散化)
Frequency
Percent
ValidPercent
CumulativePercent
Valid
<=12231.90
1
3.1
3.1
3.1
12231.91-15231.90
10
31.3
31.3
34.4
15231.91-18231.90
13
40.6
40.6
75.0
18231.91-21231.90
3
9.4
9.4
84.4
21231.91-24231.90
3
9.4
9.4
93.8
24231.91-27231.90
1
3.1
3.1
96.9
27231.91+
1
3.1
3.1
100.0
Total
32
100.0
100.0
由上图的频数分析可以看出,我国2013年城镇居民人均消费支出集中在第二组和第三组,大约占到百分之七十.由于在表格中不存在缺失值,因此频数分布表中的百分比和有效百分比相同.从此次分析中可以看出,我国城镇家庭居民人均消费的总体水平比较集中,大约在12000元--18000元之间,还有少数省市的消费水平处在中等阶段,而有上海、北京、等一些经济较发达的地区的城镇家庭居民人均消费达到了21000元以上.
三、对数据的回归分析
(一)、作出人均收入与消费支出散点图,以观察他们的线性关系如何
操作步骤:
(1):
选择“图形”,打开“图表构建程序”菜单项
(2):
从“库”中选择“散点图”将其拖入“图表预览使用数据实例”
(3):
将“人均收入”选定为x轴,将“人均消费”选定为y轴
(4):
点击“确认”生成如下散点图
由散点图可以看出,人均消费Y和人均收入X大概呈一元线性关系,因此可以建立一元线性模型进行回归分析.
(二)假设回归模型为Y=a+bX,其中,Y表示城镇人均消费支出,为被解释变量,X表示人均收入,为解释变量,b为回归系数.
操作步骤:
(1)选择“分析”→“回归”→“线性”菜单项,打开“线性回归”对话框.
(2)将“人均消费”选入“因变量”列表框,将“人均收入”选入“自变量”列表框.
(3)单击“确定”按钮.
得到如下
(1)、
(2)、(3)、(4)四表格,依次分析如下:
表
(1):
移入/移出的变量
VariablesEntered/Removedb
Model
VariablesEntered
VariablesRemoved
Method
1
人均收入a
.
Enter
a.Allrequestedvariablesentered.
b.DependentVariable:
人均消费
从上表可以看出,放入模型的变量只有一个即“人均收入”,选择变量的方法为强行进入法,也就是说将所有的自变量都放入模型中,模型的因变量为“人均消费”.
表
(2):
模型汇总
ModelSummary
Model
R
RSquare
AdjustedRSquare
Std.ErroroftheEstimate
1
.960a
.922
.920
1106.90715
a.Predictors:
(Constant),人均收入
上表是对模型的简单汇总,其实就是对回归方程拟合情况的描述,通过这表可以知道相关系数R=0.960,决定系数
=0.922,调整决定系数
=0.920,和回归系数的标准误=31106.90715.由于决定系数接近于1,说明模型的拟合程度较好.
表(3):
方差分析表
ANOVAb
Model
SumofSquares
df
MeanSquare
F
Sig.
1
Regression
4.353E8
1
4.353E8
355.256
.000a
Residual
36757303.474
30
1225243.449
Total
4.720E8
31
a.Predictors:
(Constant),人均收入
b.DependentVariable:
人均消费
F=355.256,P=0.000<0.05,表明回归方程高度显著,即农民人均收入对消费有高度影响.
表(4):
系数
Coefficientsa
Model
UnstandardizedCoefficients
StandardizedCoefficients
t
Sig.
B
Std.Error
Beta
1
(Constant)
1897.504
835.983
2.270
.
人均收入
.599
.032
.960
18.848
.000
a.DependentVariable:
人均消费
由上表知a=1897.504,b=0.599,由此可以得出以下回归方程:
人均消费Y=1897.504+0.599人均收入X
上述回归方程给出了如下信息:
2013年中国城镇居民人均可支配收入增加1元,人均消费支出增加0.599元.
四、单样本的T检验
(一):
由频数分析可知,分组后,全国31个省市的城镇家庭居民平均每人生活消费支出合计,大约有23个城市都集中在第一组,数额主要12231.91——18231.90元之间,其中在15231.91-18231.90之间的占到了百分之四十,因此可推断,全国农村家庭居民平均每人生活消费支出的平均数应该在15000--20000元之间,假设为18000元,由于该问题涉及的是单个总体,且要进行总体均值检验,同时农村家庭居民平均每人消费的总体可近似认为服从正态分布,因此,应采用单样本t检验来分析推断全国农村家庭居民人均消费的平均值是否为18000元.分析结果如下:
(二):
操作步骤:
1、选择“分析”→“比较均值”→“单样本天t检验”菜单项,打开“单样本t检验”对话框如下图所示:
2、单击“确定”按钮.
生成如下两图表:
表
(1):
One-SampleStatistics
N
Mean
Std.Deviation
Std.ErrorMean
人均消费
32
17216.6031
3902.16064
689.81106
表
(2):
One-SampleTest
TestValue=00
t
df
Sig.(2-tailed)
MeanDifference
95%ConfidenceIntervaloftheDifference
Lower
Upper
人均消费
-1.136
31
0.265
-783.39688
-2190.2758
623.4821
由表
(1)可知样本均值为17216.6031,低于基准线18000.00,标准差3902.16064,均值标准差689.81106.
由表
(2)为单样本t检验的分析结果,第一行注明了用于比较的假设总体均数为18000,下面从左到右依次为t值、自由度、p值、两均数的差值、差值.根据上面的检测结果t=-1.136,p=0.256,由于p>0.05,所以不能拒绝原假设,可以认为人均消费水平在18000元.同时,可知全国城镇居民2013年人均消费在95%的置信水平下的置信区间为:
(15809.7242,18623.4821).
五、非参数检验——多配比样本分参数检验
数据中我国城镇家庭居民人均消费包括食品、衣着、居住、家庭设备、交通及通讯、文教娱乐、医疗保健、和其他8个指标,为了比较清楚的了解这8项指标对我国城镇居民人均消费总体的影响,以及其大概的消费动向,可以利用多配比样本的非参数检验Friedman检验对各个指标进行检验.
(一):
操作步骤:
(1)选择“分析”→“非参数检验”→“旧对话框”→“k个相关样本”菜单项,打开如下对话框:
(2):
单击“确定”按钮,得到如下两表格:
表
(1):
Ranks
MeanRank
食物消费
8.00
衣物消费
5.09
居住消费
4.50
家居设备
2.66
交通通讯
6.38
医疗保健
2.34
文教娱乐
5.88
其它
1.16
表
(2):
TestStatisticsa
N
32
Chi-Square
198.604
df
7
Asymp.Sig.
.000
a.FriedmanTest
(二)、结果分析
检验结果中的p值小于给定水平0.05,故拒绝原假设,认为八个指标对我国城镇居民人均消费的影响是有显著差异的.由表
(1)知食物消费对人均消费的影响最大,其次是交通通讯和衣物消费,而影响最小的是其它.
六、因子分析
在研究我国城镇居民的消费情况时收集了食物、衣物、居住等八个影响居民消费情况的因素,以期对问题能够有比较全面、完整的把握和认识.由于数据过多,在实际建模时,这些变量未必能真正发挥预期的作用,会给统计分析带来许多问题,可以表现在:
计算量的问题和变量间的相关性问题.为了解决这些问题,最简单和最直接的解决方案是削减变量个数,但这又必然会导致信息丢失和信息不完整等问题的产生.为此,人们希望探索一种更有效的解决方法,它既能大大减少参与数据建模的变量个数,同时也不会造成信息的大量丢失.因子分析正是解决这种问题的方法.
(一)操作步骤
(1)、选择菜单“分析”→“降维”→“因子分析”,出现因子分析对话框;
(2)、把参与因子分析的样本选到变量对话框中,如下图:
(3)单击“确定”按钮,得到如下11图:
图
(1)原有变量的相关系数矩阵:
CorrelationMatrix
食物消费
衣物消费
居住消费
家居设备
医疗保健
交通通讯
文教娱乐
其它
Correlation
食物消费
1.000
.288
.656
.744
.295
.787
.782
.732
衣物消费
.288
1.000
.337
.517
.694
.368
.374
.634
居住消费
.656
.337
1.000
.676
.505
.849
.750
.771
家居设备
.744
.517
.676
1.000
.441
.830
.853
.767
医疗保健
.295
.694
.505
.441
1.000
.479
.414
.600
交通通讯
.787
.368
.849
.830
.479
1.000
.860
.782
文教娱乐
.782
.374
.750
.853
.414
.860
1.000
.831
其它
.732
.634
.771
.767
.600
.782
.831
1.000
从上图可以看到,大部分的相关系数都较高,各变量呈较强的线性关系,能够从中提取公共因子,适合进行因子分析.
图
(2)巴特利特球度检验和KMO检验
KMOandBartlett'sTest
Kaiser-Meyer-OlkinMeasureofSamplingAdequacy.
.833
Bartlett'sTestofSphericity
Approx.Chi-Square
233.009
df
28
Sig.
.000
由上图知,巴特利特球度检验统计量的观测值为233.009,相应的概率p为0.如果给出的显著性水平为0.05,由于概率p小于显著性水平,应拒绝零假设,认为相关系数矩阵与单位阵有显著地差异.同时,KMO值为0.833,根据Kaiser给出了KMO度量标准可知原有变量适合进行因子分析.
图(3)因子分析的初始解
Communalities
Initial
Extraction
食物消费
1.000
.798
衣物消费
1.000
.862
居住消费
1.000
.750
家居设备
1.000
.812
医疗保健
1.000
.821
交通通讯
1.000
.897
文教娱乐
1.000
.885
其它
1.000
.872
ExtractionMethod:
PrincipalComponentAnalysis.
由上图第二列可知,所有变量的共同度均较高,各个变量的信息丢失较少.因此,本次因子提取的总体效果较理想.
图(4)因子解释原有变量总方差的情况:
TotalVarianceExplained
Component
InitialEigenvalues
ExtractionSumsofSquaredLoadings
RotationSumsofSquaredLoadings
Total
%ofVariance
Cumulative%
Total
%ofVariance
Cumulative%
Total
%ofVariance
Cumulative%
1
5.504
68.794
68.794
5.504
68.794
68.794
4.524
56.545
56.545
2
1.192
14.898
83.692
1.192
14.898
83.692
2.172
27.147
83.692
3
.473
5.910
89.602
4
.258
3.222
92.824
5
.237
2.961
95.785
6
.178
2.227
98.012
7
.
1.136
99.147
8
.068
.853
100.000
ExtractionMethod:
PrincipalComponentAnalysis.
上图◎第一组数据项描述了初始因子解的情况.可以看到,第一个因子解的特征根值为5.504,解释原有八个变量总方差的68.794%,累计方差贡献率为68.794%.其余数据含义类似.在初始解中由于提取了八个因子,因此原有变量的总方差均被解释掉.
◎第二组数据项描述了因子解的情况.可以看到,由于指定提取两个因子,两个因子共解释了原有变量总方差的83.692%.总体上,原有变量的信息丢失较少,因子分析效果较理想.
◎第三组数据项描述了最终因子解的情况.可见,因子旋转后,累计方差比没有改变,也就是没有影响原有变量的共同度,但却重新分配了各个因子解释原有变量的方差,改变了各因子的方差贡献,使得因子更容易解释.
图(5)因子的碎石图:
上图横坐标为因子数目,纵坐标为特征根.可以看到,第一个因子的特征根值很高,对原有变量的贡献最大;第3个以后的因子特征根都较小,对解释原有变量的贡献很小,已经成为可被忽略的“高山脚下的碎石”,因此提取两个因子是合适的.
图(6)因子载荷矩阵:
ComponentMatrixa
Component
1
2
其它
.929
.
交通通讯
.921
-.222
文教娱乐
.909
-.241
家居设备
.895
-.103
居住消费
.854
-.143
食物消费
.822
-.350
衣物消费
.599
.710
医疗保健
.635
.646
a.2componentsextracted.
上图因子载荷矩阵是因子分析的核心容.根据该表可以写出本案例的因子分析模型:
其它=0.929
+0.
交通通讯=0.921
-0.222
文教娱乐=0.909
-0.241
家居设备=0.895
-0.103
居住消费=0.854
-0.143
食物消费=0.822
-0.350
衣物消费=0.599
+0.710
医疗保健=0.635
+0.646
由上表知,八个变量在第一个因子上的载荷都很高,意味着他们与第一个因子的相关度高,第一个因子很重要.
图(7)旋转后的因子载荷矩阵:
RotatedComponentMatrixa
Component
1
2
交通通讯
.915
.244
文教娱乐
.914
.222
食物消费
.889
.084
家居设备
.836
.336
居住消费
.819
.281
其它
.770
.528
衣物消费
.188
.909
医疗保健
.250
.871
a.Rotationconvergedin3iterations.
由上图知,交通通讯、文教娱乐、食物消费、家居设备、居住消费、其它在第一个因子上有较高的载荷,第一个因子主要解释了这几个变量;衣物消费、医疗保健在第二个因子上的载荷较高,第二个因子主要解释了这几个变量.
图(8)因子旋转中的正交矩阵
ComponentTransformationMatrix
Component
1
2
1
.879
.477
2
-.477
.879
图(9)因子协方差矩阵:
ComponentScoreCovarianceMatrix
Component
1
2
1
1.000
.000
2
.000
1.000
从上表可以看出,两因子没有线性相关性,实现了因子分析的设计目标.
图(10)旋转后的因子载荷图:
由上图可以直观的看出,衣物消费和食物消费比较靠近两个因子坐标轴,表明如果分别用第一个因子刻画食物消费,用第二个因子刻画衣物消费,信息丢失较少,效果较好.
图(11)因子得分系数矩阵:
ComponentScoreCoefficientMatrix
Component
1
2
食物消费
.271
-.187
衣物消费
-.188
.576
居住消费
.194
-.032
家居设备
.184
.001
医疗保健
-.157
.532
交通通讯
.236
-.084
文教娱乐
.241
-.
其它
.110
.152
根据上表可以得到以下因子得分函数:
=0.271食物消费-0.188衣物消费+0.194居住消费+0.184家居设备-0.157医疗设备+0.236交通通讯+0.241文教娱乐+0.110其它
=-0.187食物消费+0.576衣物消费-0.032居住消费+0.001家居设备+0.532医疗设备-0.084交通通讯-0.099文教娱乐+0.152其它
可见计算两个因子得分变量的变量值时,食物消费和衣物消费的权重较高,但方向恰好相反,这与因子的实际含义是相吻合的.
七、实验心得
本科的时候有概率统计和数理分析的基础,但是从来没有接触过应用统计分析的东西,SPSS也只是听说过,从来没有学过.一直以为这一块儿会比较难,这学期最初学的时候,因为没有认真看教材,课下也没有认真搜集相关资料,所以学起来有些吃力,总感觉听起来一头雾水.老师说最后的考核是通过提交学习报告,然后我从图书馆里借了些教材查了些资料,发现很多问题都弄清楚了.结合软件和书上的例子,实战一下,发现SPSS的功能相当强大.这门课要学习完了,整个学习的过程是充满曲折和挑战的,我见证了自己从一无所知到困惑迷茫再到略懂再到会用的过程.甚至学完之后有些问题还没有彻底搞清楚,自己接下来还会不断的探索的.SPSS是个很神奇的工具,结合AMOS和EXCEL更是如虎添翼,相信学习了SPSS在以后的论文和数据分析中很有用.这门课给我的感觉是
 升级会员
升级会员 