SPSS学习资料.docx
《SPSS学习资料.docx》由会员分享,可在线阅读,更多相关《SPSS学习资料.docx(18页珍藏版)》请在冰豆网上搜索。
SPSS学习资料
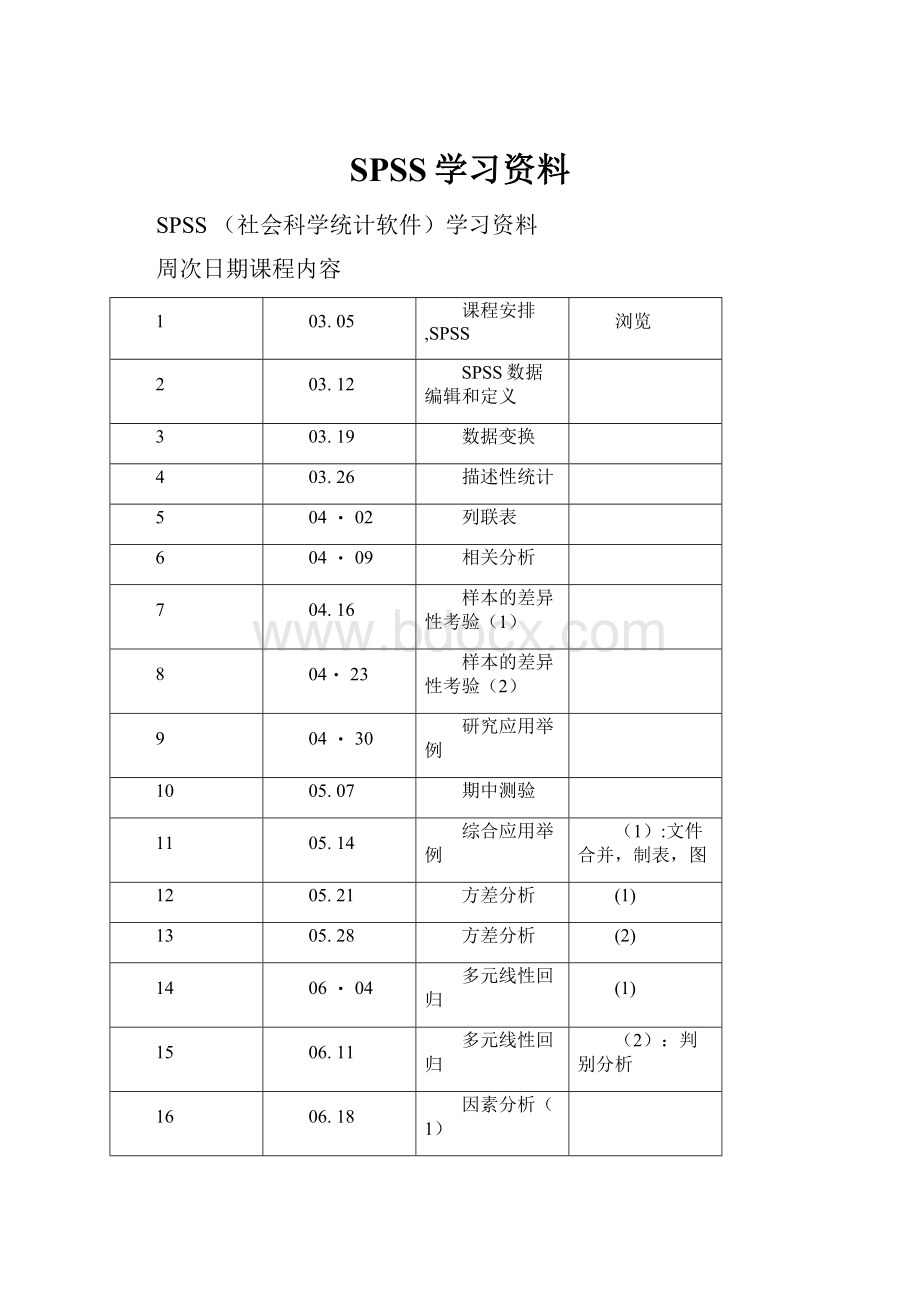
SPSS(社会科学统计软件)学习资料
周次日期课程内容
1
03.05
课程安排,SPSS
浏览
2
03.12
SPSS数据编辑和定义
3
03.19
数据变换
4
03.26
描述性统计
5
04・02
列联表
6
04・09
相关分析
7
04.16
样本的差异性考验
(1)
8
04・23
样本的差异性考验
(2)
9
04・30
研究应用举例
10
05.07
期中测验
11
05.14
综合应用举例
(1):
文件合并,制表,图
12
05.21
方差分析
(1)
13
05.28
方差分析
(2)
14
06・04
多元线性回归
(1)
15
06.11
多元线性回归
(2):
判别分析
16
06.18
因素分析
(1)
17
06.25
因素分析
(2):
聚类分析
18
07.02
综合应用举例
(2)
参考书:
SPSSforWindov/s:
BaseSystemUser*sGuide・Marija丄Norusis・SPSSInc.卢纹岱等编箸:
SPSSforWindows从入门到精通。
电子工业出版社,1996年・
SPSSforWindov/smadeSimple.3rded.PaulR.Kinnear&ColinD.GrayPsychologicalPress,Ltd.,1999
ElectronicStatisticalTextbook(fromStatSoft)・StatSoft./textbook/stathome.html作业:
必须在次周周一前用电子邮件,磁盘或打印形式交给主讲教师和辅导上机的助教。
讲义:
课前在网上下载或接收电子邮件。
成绩评定方法:
期末考试,期中考试,和作业,出勤。
期末考试
40%
期中考试
30%
作业,出勤
30%
总成绩
100
SPSS软件简介
w.
SPSS是StatisticsPackageforSocialSciences(社会科学统计软件包)的缩写,是社会科学研究人员首选的统计软件,也是目前世界上最流行的统计软件(SPSS、SAS)之一。
自1985年以来,SPSS公司推出了一系列不同版本的SPSS软件。
我们这里主要简介SPSS10.0版本。
第一章数据和文件
1准备分析用数据
1.1数据收集
主要是通过测量方法收集必需的数据。
测量方法可以是实验、测验、问卷调查等等。
应尽可能包括自己所需要的所有变量,因为从分析中排除不必要的变量比收集附加变量要容易得多。
1・2数据编码
当我们通过问卷或测验收集了很多的数据回来后,接下来的工作就是把这些数据录入到讣算机里。
为了输入数据简单,一种方法是在录入前用数据或符号表述被试的回答,这就是数据编码。
下面是一个编码表:
变量名
代号
位数
位置
备注
编号
Num
3
1—3
学校
Sch
1
4
1•南武2-晓园3-97中
性别
Sex
1
5
仁男子2•女
设置一个能唯一标记Case的变量是很有用的,它可以帮助人们很容易找到某些特殊信息的Case。
(编码示例)
不管你自己对SPSS使用多么熟悉,在数据录入前对数据进行系统的编码是非常必要的,它可以使你避免混乱,清楚了解数据的意义。
1・3数据文件
SPSS有三种文件:
SYNTAX文件(文本文件,以・sps为后缀)、DMA文件(数据文件,以・sav为后缀)、OUTPUT文件(结果文件,以・sp。
为后缀)。
SYNTAX文件主要是保存命令及相关的文本资料;DATA文件则是保存供SPSS统计的数据,只有这种文件里的数据才可以直接进行统计使用;OUTPUT文件保存统计的结果。
SPSS所用的数据文件有很多种,主要是根据自己分析数据的量及每一Case包括变量多少来选择适当的文件形式。
当数据较少及Case不多时,可以直接在SPSS的数据文件里加入数据。
(录入数据示例)
当数据较多时,一般习惯用一编辑系统来录入数据(如SPSS中的SYN口X文件),然后再通过定义命令把数据读入统计用的数据文件里。
这样录入的速度较快,不过可能不容易查找在录入过程中的错误。
这里只介绍用SPSS中的SYNTAX文件录入数据的方法,并且在以下的其它内容中,也相应只介绍一些习惯的方法。
(录入数据示例)
2数据定义与转换
2.1数据定义(DATMIST)
在用SPSS中的SYNTAX文件录入的数据文件中,每一个人的资料都排在一行上(可以多行)。
这样任何一个变量的数据都在相同的列里。
SPSS在使用这些数据时,必须对这些数据进行定义。
即告诉计算机各列数据代表什么。
DA口LIST命令用以给变量命名,并定义它们在Case中的位置和属性,把数据变成能被SPSS命令或过程使用的现用文件。
下面只介绍用固定格式引用外部数据文件的命令:
DATALISTFILE='C:
\YLX\STRESS.SPS,/num1-3sch4sex5chi6-7
a1toa108-17.
FILE子命令指定从外部文件C:
\YLX\STRESS.SPS读入数据。
接着是各个变量的名称及所在位置(字符宽)。
(1)当数据里有小数应该怎么表示?
如,语文成绩里有85.3分,小数点不用录入,我们只要在程式里告诉电脑哪位是小数就可以了。
如:
DATALISTFILE='C:
\YLX\STRESS・SPS'/num1-3sch4sex5chi6-8
(1)a1toa109-18....
chi6-8
(1)中括号里的1表示有一位小数。
如果是两位小数就用
(2)o
(2)当你的数据中每个被试的数据有两行或者多行时应该怎么办?
下面的例子是一个case有三行数据的情况:
datalistfile='d:
\data\2002\study.sps'records=3/1school1numb2・3sex4grade5Chinese6-7math8-9english10-11s1tos6012-71
/2s61tos901-30b1tob4431-74
/3a1toa411-41d1tod4242-83.
用records=3指明每个被试有三行数据,在定义的时候,用门/2/3指明是第儿行的数据。
(结合学生前面录入的数据示例)
2.2变量值的重编码(RECODE)
在统讣数据处理时,经常需要对数据进行某些变换以适应不同处理的要求。
所谓数据变换是利用现存变量,或改变它们的值,或利用它们产生新的变量。
RECODE可以对现存变量的值作指定的变换。
如我们有一个题LI是:
“我不能满足学生的期待。
”要求老师在下面五个选择中选一个“1从来没有、2很少、3有时、4经常、5总是”。
我们在录入数据时只是按老师选择的数字录入。
但现在我们想统计“有时+经常+总是”和“从来没有+很少”的人数及比例。
这时我们可以用RECODE命令进行变换。
RECODEITEM1(1,2=1)(3,4,5=2)・
这样我们就用1代表“从来没有+很少”,用2代表“有时+经常+总是”。
另,如年龄这一变量,我们可能在录入时是按实际年龄的数字录入,但如果我们想把它们分老、中、青三组以比较三种年龄的人的差异时,就可以用RECODE命令对原数据中的年龄变量进行变换。
RECODEAGE(LOTHRU35=1)(36THRU45=2)(46THRUHl=3)・
把最小到35岁为青年组,用1表示;36到45岁为中年组,用2表示;46到最老为老年组,用3表示;这样就对原来变量的值重新进行了编码。
这里大家应该记住:
THRU表示“至”。
第一个命令里是确定的值“(1,2=1)",而第二个命令是一个范围a(LOWESTTHRU35=1)”。
(结合学生前面录入的数据示例)
2.3计算变量(COMPUTE)
有时我们想对数据进行组合,形成一个新的变量。
如我们用10道题来测量学
生对学校的态度,但我们并不想对这10道题进行一一的分析,我们想对它们进行合并来说明该学生对学校的态度惜况。
这时我们可以用COMPUTE命令来组合成新的变量。
COMPUTEATTITUDE=(ITEM1+ITEM2+ITEM3+ITEM4+...+ITEM10)门0・
把十个项目的分析的相加的平均分成一个新的变量ATTITUDE.也可以是其它的运算关系,如减、乘、除、平方、开方等。
当然你可以不除以10,这样得到的是10道题的总分,除以10是项目平均分。
但有时因为可能有儿个维度,而这儿个维度的项LI数不一样多,我们乂想比较各维度的水平,这时我们除以项口数,得到项U平均分以利于比较。
乂如你用学生的语文、数学、英语三科的总成绩作为学生的学业成绩。
computetotal=chinese+math+english.
除以3就可以得到平均每科的成绩。
写成:
computetotal=(chinese+math+english)/3.
(结合学生前面录入的数据示例)
2・4条件变换(IF)
if命令根据逻辑条件执行类似于recode的变换。
如当我们想把男生且考试分数不合格的作一组,男生且考试分数合格至良好的作一组,男生且考试分数优秀的作一组,以比较三组学生在某一方面的差异时,我们可以用if命令来形成一个新的变量。
IF(SEX=1ANDSCORE<=60)SEXSC=1.
IF(SEX=1ANDSCORE>60ANDSCORE<=80)SEXSC=2.
IF(SEX=1ANDSCORE>80)SEXSC=3.
这样我们就变换成一个新的变量SEXSC,进而比较SEXSC在某一方面的差异,即上述三组学生的差异。
(结合学生前面录入的数据示例)
当然,我们可以IF命令来获得很多种我们想要的变换。
注意和RECODE的差异。
其实RECODEAGE(LOTHRU35=1)(36THRU45=2)(46THRUHl=3).也可以用IF来实现:
IF(AGE<=35)AGE1=1・
IF(AGE>35ANDAGE<=45)AGE1=2・
IF(AGE>45)AGE1=3・
不过,这样就会产生了一个新的变量“AGE1”,当然原来的变量“AGE”也保持不变。
(结合学生前面录入的数据示例)
2・5缺失数据的定义(MISSING)
我们在做调查时,经常遇到一些被试对某一问题漏答的情况。
但山于该被试的其他资料还是可以用的,不想把他剔除。
在编码时,我们用一个答案上没有的数字表示缺失。
一般习惯是用“0”、“9”或“00”、“99”等,但注意这些数字必须是答案中没有的,否则重复了会把原来具有其它意义的变成了缺失。
在用SPSS进行统计,我们就必须告诉计算机,某一变量如果数值是“0”、“9”或“00”、“99”时,就表示缺失。
如某些学生忘记填写性别,我们用9来表示缺失。
MISSINGVALUESEX(9)・
告诉计算机,当SEX是9时,表明该学生没有填写性别。
在做涉及到该变量的某些计算时,如比较男女学生的差异,可以考虑剔除丢失该变量资料的人。
第二章描述统计过程
1频数
这是对数据的一般整理,了解样本的分布:
离散性、变异性和规律性。
统计学中的分布是指一个变量的各种情况或取值出现的次数或频数,所以乂叫做频数分布。
如家长的职业,我们可以用变量名“JOB”,不同的职业我们给予不同的数字表示:
仁干部、2•教师、3•研究员等,分布是指被调查的学生中各种职业的家长数。
频数分布反映出落入每一组的观察值个数。
还可以用分数、小数或白分数表示。
1.1命令FREQUENCES
FREQUENCES计算单个变量值的频数、白分数和各种描述统计量。
如上述,我们要计算各种职业的父母的人数。
FREQUENCESVARIABLES=JOB.(可以简写成:
FREVAR=JOB.)
输出结果的解释:
DescriptiveStatistics
N
Minimum
Maximum
Moan
Std.
Deviation
CHINESE
534
43
94
77.41
8.48
ValidN(listwise)
534
如果我们想还同时知道数学、英语等科的平均数分与标准差,可以把该命令写成:
DESCRIPITVESVARIABLES二CHINESEMATHENGLISH.
计算机就会同时告诉我们这三门学科学生的平均等分、标准差、最大/最小值、有效Case数等。
输岀结果的解释:
DescriptiveStatistics
N
Minimum
Maximum
Moan
Std.
Deviation
CHINESE
534
43
94
77.41
8.48
MATH
534
31
99
82.15
14.47
ENGLISH
534
16
99
76.14
13.52
ValidN(listwise)
534
2.2命令MEANS
MEAANS与DESCRIPITVES不同,MEANS是计算由一个或多个独立变量定义的分组内,因变量的平均数、标准差和组数。
如我们要了解男女学生的语文、数学和英语的平均数、标准差等,就可以用
MEANS计算。
MEANSIABLES=CHINESEMATHENGLISHBYSEX.
执行这一命令,会给出男女学生的语文、数学和英语的平均分、标准差等。
MEANS命令还可以计算更多的变量的分组。
如不同性别、不同年级学生的语文成绩平均数与标准差等。
命令可写成:
MEANS口BLES二CHINESEBYSEXBYGRADE・
输出结果的解释:
CaseProcessingSummary
Cases
Included
Excluded
Total
NPercent
NPercent
NPercent
CHINESE*SEX*
534
98.0%
11
2.0%
545
100.0%
GRADE
Report
CHINESE
GRADE
SEX
Moan
N
Std.
Deviation
1
1
83.59
41
5.73
2
85.30
63
4.45
Total
84.62
104
5.04
2
1
77.32
50
8.07
2
80.37
68
7.04
Total
79.08
118
7.61
3
1
76.31
48
8.37
2
79.76
68
5.79
Total
7&34
116
7.15
4
1
71.35
49
5.15
2
73.96
51
5.99
Total
72.68
100
5.72
5
1
6&50
44
10.14
2
73.75
52
7.85
Total
71.34
96
9.30
Total
1
75.28
232
9.15
2
79.04
302
7.54
Total
77.41
534
8.48
第三章相关分析和回归分析
1相关
相关分析的意义
我们常用相关系数来表示两变量的关系程度。
当然我们在计算相关,应该考虑这两个变量之间的关系是否线性。
如果不是线性的关系,而使用相关系数来表示两变量间的关系的话,就会错误估计它们的关系。
如生活压力与心理健康之间的关系,很多研究结果都表明,它们之间关系应该是一倒U型的曲线,也就是非线性的关系。
因此,我们就不能用相关系数来表示它们之间关系的量。
但很多变量之间关系是线性的,如学习的努力程度与学习成绩的关系,我们可以用相关系数来说明它们之间关系的程度。
当然,计算相关有很多种公式,对公式的选择与变量的性质有关:
是连续变量还是二分变量或是等级变量等等。
一般没有注明的时候是用皮尔逊积差相关。
1・2命令CORRELATION
如我们要计算学生的语文成绩(CHINESE)与英语成绩(ENGLISH)之间的关系,可以用以下命令:
CORRELATIONVARIABLES二CHINESEWITHENGLISH・
输出结果的解释:
Correlations
ENGLISH
CHINESE
PearsonCorrelation
.502
Sig.(2-tailed)
.000
N
534
这一命令还可以同时计算多个变量与多个变量两两之间的相关。
如语文成绩、数学成绩、英语成绩之间的两两相关,可以用如下命令:
CORRELATIONVARIABLES=CHINESEMATHENGLISHWITHCHINESEMATHENGLISH・
或:
CORRELATIONVARIABLES=CHINESEMATHENGLISH.
输出结果的解释:
Correlations
CHINESE
MATH
ENGLISH
CHINESE
PearsonCorrelation
1.000
•515
.502
Sig.(2tailed)
•
.000
.000
N
534
534
534
MATH
PearsonCorrelation
.515
1.000
.566
Sig.(2tailed)
.000
•
.000
N
534
534
534
ENGLISH
PearsonCorrelation
.502
.566
1.000
Sig.(2tailed)
.000
.000
•
N
534
534
534
Correlationissignificantatthe0.01level(2-tailed)・
结果除给出两两相关系数(相关矩阵)夕卜,还显示出双尾显著性检测的结果。
SPSS可以指定所用的相关公式,如果没有指定,一般默认为皮尔逊积差相关。
用什么公式,应该要根据数据来决定。
2回归分析
回归分析的訂的是建立两列或多列变量之间的数量关系模型(即回归方程)。
也就是确定了自变量与因变量的关系模型,利用这个数学模型,我们可以从一个变量或多个变量来预测或估计另一个变量的变化。
例如,我们知道学习基础(X)对成绩(Y)有密切关系,我们想建立一个回归方程,根据学生原来的学习水平高低来估计淇未来成绩:
Y=a+bXo这里所提到的是指线性关系的,而对于非线性关系的回归,则是另一回事。
2.2命令REGRESSION
REGRESSION是计算多元回归的命令。
提供五种建立回归方程的方法:
向前选择(Rorward)、向后剔除(Backward)、逐步选择(Stepwise)、强制进入(Enter)和强制剔除(Remove)o假如我们用逐步选择方法进行回归分析,命令格式如下:
REGRESSIONVARIABLES={varlist}/dependent=varlist/method=stepwise.或:
REGRESSION
/DEPENDENTvarlist/METHOD二STEPWISEvarlist.
DEPENDENT里的变量名必须在前面的变量名里。
一般如果不指定方法,即为默认的逐步选择方法。
2.3输出结果的解释
第四章差异检验
1两组平均数的差异检验
1.1平均数的差异检验的意义
当我们想检验两样本之间是否存在差异,可以使用平均数的差异检验。
例如比较男女学生在数学学习上是否存在差异。
一般我们可以用T检验来证明两组是否差异显著。
1.2命令T-TEST
T-TEST用以检验独立样本或配对样本的平均数差异显著性。
当两列变量的样本不一样时,统计是不同的。
1.3独立样本
例如:
比较男女学生在学习上(包括数学、语文、英语成绩)是否存在差异。
T-TESTGROUPS=SEX(1,2)/VARIABLES=AAATHCHINESEENGLISH・
结果会告诉我们男女学生在数学、语文、英语三门学科的平均数、标准差、T值、显著水平。
1.4相关样本:
例如:
为了比较单眼与双眼对深度知觉的影响,50名学生分别用单眼与双眼进行了实验,等到单眼观察的一列数(A)双眼观察的一列数(B)•我们比较这两列数的差异是否显著,以了解单、双眼对深度知觉的差异。
T-TESTPAIRS=AWITHB.
结果会给出两列数的平均数、标准差、T值、显著水平等。
1.5输出结果的解释
2单因素方差分析
2.1单因素方差分析的意义
但大多数时,我们要比较不止两组平均数的差异,而可能是两个以上的样本平均数。
这种多个样本平均数差异的检验需要通过方差分析进行。
在这种意义上,可以把方差分析看作T检验扩展。
有很多也用T检验来两两样本进行差异检验,但这是不对的。
2.2命令ONEWAY
ONEWAY命令用以检验单因素的儿个组间的差异。
例如,要比较初一、初二、初三学生心理健康(SCL)是否存在差异,可用如下命令格式:
ONEWAYVARIABLES二SCLBYGRADE(1,3)・
执行这一命令后,计算机会告诉我们三个年级学生在心理健康上的是否存在差异,即给出F值、显著性水平等。
2.3输出结果的解释
2.4多重比较
但当三个年级之间存在显著差异时,我们并不知道哪两个年级之间差异显著或差异不显著。
这就需要进行多重比较。
命令格式为:
ONEWAYVARIABLES=SCLBYGRADE(1,3)/RANGE二SCHEEFE.
多重比较的方法有好儿种,可以根据需要选择。
我们一般用费舍法或涂凯法。
以上是用费舍法。
执行以上命令,会告诉我们F值、显著性水平,如果差异显著,还会告诉我们各组的平均及哪两组之间差异显著。
3多因素方差分析
3.1多因素方差分析的意义
前面介绍的方差点分析是属于单因素实验设计,即实验中只有一个自变量。
但心理的影响因素是多种的,单因素设计•只是人为地只取一个因素作为自变量。
大多数悄况下,是多因素的设计。
例如:
不同的教学方法(因素A)和不同的教学态度(因素B)对学生的学习成绩(因变量)的影响。
这种情况下,我们必须使用多因素方差分析方法对自变量的影响进行检验。
3.2命令ANOW
ANOVA执行多因素实验设计的方差分析,一个ANOVA可以分析多个因素(多个自变量)和儿个因变量。
例如:
我们考察不同年级(初一、初二、初三)、不同性别(男、女)学生心理健康悄况的差异,可用以下命令格式工:
ANOVAVARLABLES=SCLBYGRADE(1,3)SEX(1,
 升级会员
升级会员 