eviews图像及结果分析.docx
《eviews图像及结果分析.docx》由会员分享,可在线阅读,更多相关《eviews图像及结果分析.docx(18页珍藏版)》请在冰豆网上搜索。
eviews图像及结果分析
第4章图形和统计量分析
EViews软件提供了序列(Series)和序列组(Group)等对象的各种视图、统计分析方法和过程。
当序列对象中输入数据后,就可对序列对象中输入的数据进行统计分析,并且可以通过图、表等形式进行描述。
本章将介绍序列和序列组对象图形的生成和描述性统计量及其检验。
4.1图形对象
图形(Graph)对象可以形成序列和序列组等对象的各种视图,如线图(Line)、散点图(Scatter)以及饼图(Pie)等。
通过图形可以进一步观察和分析数据的变化趋势和规律。
下面介绍图形对象的基本操作。
4.1.1图形(Graph)对象的生成
图形对象也是工作文件中的基本对象之一。
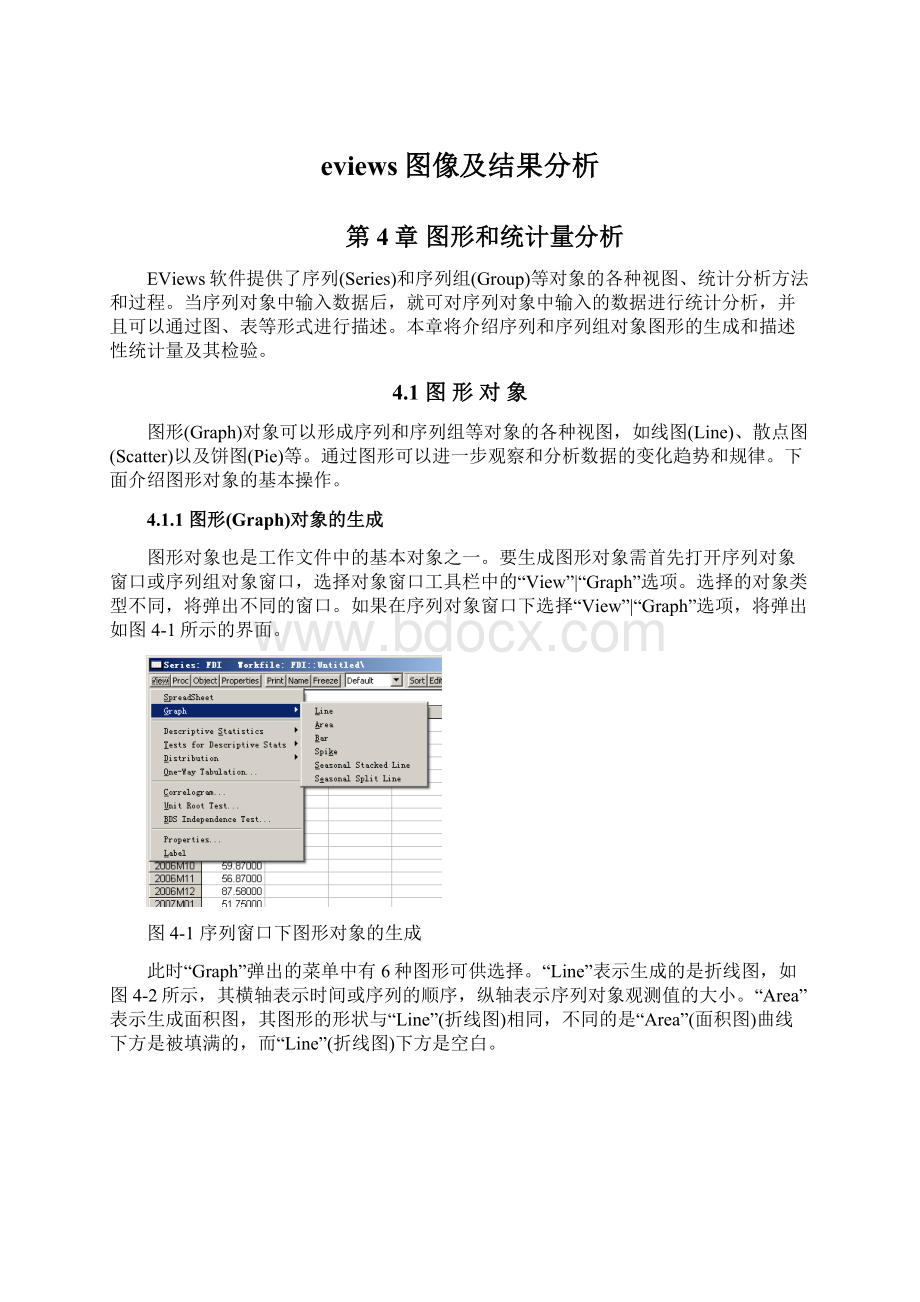
要生成图形对象需首先打开序列对象窗口或序列组对象窗口,选择对象窗口工具栏中的“View”|“Graph”选项。
选择的对象类型不同,将弹出不同的窗口。
如果在序列对象窗口下选择“View”|“Graph”选项,将弹出如图4-1所示的界面。
图4-1序列窗口下图形对象的生成
此时“Graph”弹出的菜单中有6种图形可供选择。
“Line”表示生成的是折线图,如图4-2所示,其横轴表示时间或序列的顺序,纵轴表示序列对象观测值的大小。
“Area”表示生成面积图,其图形的形状与“Line”(折线图)相同,不同的是“Area”(面积图)曲线下方是被填满的,而“Line”(折线图)下方是空白。
图4-2“Line”折线图
“Bar”表示为条形图,用条状的高度表示观测值的大小。
“Spike”表示尖峰图,由竖线组成,每根竖线的高度代表观测值的大小。
“SeasonalStackedLine”表示生成的是季节性堆叠图,“SeasonalSplitLine”表示生成的是季节性分割线。
如果在序列组(群)对象窗口下选择“View”|“Graph”选项,将弹出如图4-3所示的界面。
这里有9种图形可供选择。
其前4种与上面讲述的相同。
图4-3序列组(群)窗口下图对象的生成
其中,“Scatter”表示生成散点图。
在“Scatter”弹出的菜单中有5个选项,分别是“SimpleScatter”(简单散点图)、“ScatterwithRegression”(带有回归线的散点图)、“ScatterwithNearestNeighborFit”(近邻匹配散点图)、“ScatterwithKernelFit”(核心匹配散点图)、“XYPairs”(XY成对散点图)。
当序列组中包含两个序列对象时,第一个序列对象的观测值构成散点图的横坐标,第二个序列对象的观测值构成散点图的纵坐标,如图4-4所示。
当序列组中有三个以上的序列对象时,第一个序列对象构成散点图的横坐标,其余序列对象构成散点图的纵坐标。
图4-4简单散点图(“SimpleScatter”)
“XYline”表示X与Y的折线图,横纵坐标分别表示两个序列对象的观测值。
“ErrorBar”表示误差长条图,“High-Low”表示高低图,“Pie”表示饼图。
另外,在序列组(群)对象窗口下还可通过选择“View”|“MultipleGraphs”选项来生成图形。
此时图形显示在不同的坐标系中,即每个序列对象各形成一个图形,并显示在同一个窗口中。
除上面介绍的在序列对象窗口中生成图对象外,还可以通过选择EViews主菜单中的“Quick”|“Graph”选项来生成。
在“Graph”的菜单中选择图的类型,将弹出图4-5所示的文本框。
在文本框内输入序列或序列组的名称,例如“fdi”,然后单击“OK”按钮,即可打开相应的图。
此时所生成的图对象未被命名,单击图对象窗口中的“Name”按钮即可命名。
图4-5生成图对象的文本框
4.1.2图形的冻结
在上面所介绍的两种图对象生成方法中,通过“Quick”|“Graph”选项生成图形对象,单击图对象窗口工具栏中的“Name”选项,在弹出的对话框中输入该对象的名称,单击“OK”按钮后该对象即可被保存,并在工作文件窗口中显示图对象的图标。
但直接在序列对象窗口中形成的图形未被保存,当序列对象中的观测值发生改变时,或当前工作文件的样本范围发生变化时,图形也将随之改变。
如果要保留所建立的图形,使之不随样本及观测值的改变而发生变化,则可以通过序列对象窗口中的“Freeze”键来冻结图形。
EViews软件将被冻结的图形以一个图(Graph)对象的形式保存在工作文件中。
当选择序列对象窗口中的“Freeze”键时,会弹出图对象窗口。
其中有几个键值得关注,一个是“AddText”功能键,通过它可以将文字显示在图形中,并且可以选择显示的位置。
一个是“Line/Shade”功能键,通过它可以改变图形的背景颜色,横纵坐标轴的线条类型和颜色等。
还有一个是“Remove”功能键,可以用来删除图形中的一些附加要素。
例如,将在图形中所建立的文字删除,应首先用鼠标单击所需删除的内容,使其被选中,然后单击“Remove”键,则文字即被删除。
用同样的方法也可以删除为图形所设置的颜色等。
4.1.3图形的复制
如果需要将图形保存到其他文件中,例如放在Word文档中,则选择图对象窗口中的“Proc”|“Copy”选项,然后在弹出的对话框中单击“OK”按钮。
或者将鼠标移动到图形上,右击,在弹出的快捷菜单中选择“Copy”命令。
再打开需要粘贴的文件,进行粘贴即可。
4.2描述性统计量
EViews软件中包含一些基本的描述性统计量,有直方图、均值、方差、协方差、自相关等。
本节主要介绍序列和序列组对象窗口下的描述性统计量及其检验。
4.2.1描述性统计量概述
序列窗口下的描述性统计量和序列组窗口下的描述性统计量有所不同。
在序列窗口下有4种描述性统计量,分别是“HistogramandStats”(直方图和统计量)、“StatsTable”(统计表)、“StatsbyClassification”(分类统计量)和“BoxplotsbyClassification”(箱线图/箱尾图分类)。
序列组窗口下有3种描述性统计量,分别是“CommonSample”(普通样本)、“IndividualSamples”(个体样本)和“Boxplots”(箱线图/箱尾图)。
下面分别进行详细介绍。
(1)序列窗口下的描述性统计量
在序列(Series)对象窗口下选择工具栏中的“View”|“DescriptiveStatistics”(描述性统计量)选项,将出现4个选项。
第一个选项是“HistogramandStats”(直方图和统计量),能显示序列对象的直方图和描述性统计量的值。
下面以建立好的序列对象“fdi”为例来进行说明。
如图4-6所示,图的左侧显示的是该序列对象的直方图,为观测值的频率分布。
右侧分三个部分,最上面显示的是序列对象的名称、样本的范围和样本数量。
中间部分显示的是各统计量的值。
其中,“Mean”表示均值,即序列对象观测值的平均值;“Median”表示中位数,即从小到大排列的序列对象观测值的中间值,是对序列分布中心的一个大致估计;“Maximum”和“Minimum”表示的是该序列观测值中的最大值和最小值;“Std.Dev”表示标准差,用来衡量序列观测值的离散程度。
其计算公式为
(4-1)
式中,σ为标准差,N为样本观测值个数,xi是样本观测值,为样本均值。
图4-6序列对象“fdi”的直方图分布形状和相关统计量的描述
“Skewness”表示偏度,用来衡量观测值分布偏离均值的状况。
其计算公式为
(4-2)
式中,是变量方差的有偏估计。
当S=0时,序列的分布是对称的,如正态分布;当S>0时,序列分布为右偏;当S<0时,序列分布为左偏。
例如图4-6中的偏度为1.422500>0,所以我国的外商直接投资(fdi)的分布是不对称的,为右偏分布形态。
“Kurtosis”表示峰度,用来衡量序列分布的凸起状况。
其计算公式为
(4-3)
正态分布的K值为3,当K>3时,序列对象的分布凸起程度大于正态分布的凸起程度;当K<3时,序列对象的分布凸起程度要比正态分布小。
例如,图4-6中的峰度为4.898917>3,外商直接投资(fdi)的分布呈尖峰状态。
最下方是JB(Jarque-Bera)统计量及其相应的概率(Probability)。
JB统计量用来检验序列观测值是否服从正态分布,该检验的零假设为样本服从正态分布。
在零假设下,JB统计量服从χ2
(2)分布。
根据第1章所介绍的假设检验,P(Probability)值为拒绝原假设所犯第Ⅰ类错误的概率。
在本例中P值接近于0,因而可在1%的显著性水平下拒绝零假设,即序列不服从正态分布。
第二个选项是“StatsTable”(统计表),它将描述性统计量值通过电子表格的形式显示在对象窗口中。
第三个选项是“StatsbyClassification”(分类统计量),它将样本分为若干组后再对各组观测值分别进行描述统计。
选择此项后将弹出如图4-7所示的对话框,其中包括三部分内容。
在左边“Statistics”选项中勾选需要显示的统计量,其中“#ofNAs”为无观测个数,“Observations”为观测值个数。
在“Series/Groupforclassify”中输入需分类的序列或序列组对象名称,右侧“OutputLayout”为输出结果的显示形式。
选择好后单击“OK”按钮即可。
图4-7“StatsbyClassification”(分类统计量)对话框
第四个选项是“BoxplotsbyClassification”(分类箱线图/箱尾图),将序列分布按照箱线图/箱尾图进行分类。
箱线图(Boxplot)也称为箱尾图,是利用数据统计量来描述数据的一种方法,它可以粗略地看出数据是否具有对称性,分布的分散程度等。
图4-8所示为fdi序列的分类箱线图。
图4-8fdi序列对象的分类箱线图(“BoxplotsbyClassification”)
(2)序列组窗口下的描述性统计量
在序列组(Group)对象窗口下选择工具栏中的“View”|“DescriptiveStatistics”(描述性统计量)选项,将弹出3个选项。
第一个选项是“CommonSample”(普通样本),选择该项将得到含有均值、中位数、最大/小值等统计量的一张电子表格。
“CommonSample”要求各序列对象的样本范围相同,不能含有NA符(空值)。
第二个选项是“IndividualSamples”(个体样本),选择该项后弹出的界面也是含有均值、中位数、最大/小值等统计量的一张电子表格。
与“CommonSample”不同的是,该选项中序列对象所包含的观测值个数可以不同。
第三个选项是“Boxplots”(箱线图/箱尾图),其生成的图形与图4-8相似。
不同的是横坐标轴为序列名称。
其实,序列对象和序列组对象的描述统计量相同,只是在窗口中显示的形式不同。
序列组对象窗口中的描述性统计量是各个序列对象统计量的组合。
4.2.2描述性统计量检验
在序列对象窗口“View”|“TestsforDescriptiveStats”中有两个关于描述性统计量的检验,一个是“SimpleHypothesisTests”(简单假设检验),另一个是“EqualityTestsbyClassification”(分组齐性检验)。
简单假设检验(“SimpleHypothesisTests”)包括序列对象的均值(Mean)检验、方差(Variance)检验和中位数(Median)检验。
选择“View”|“TestsforDescriptiveStats”|“SimpleHypo
 升级会员
升级会员 