软件开发人员的薪金Word格式.docx
《软件开发人员的薪金Word格式.docx》由会员分享,可在线阅读,更多相关《软件开发人员的薪金Word格式.docx(16页珍藏版)》请在冰豆网上搜索。
14975
12
861
16882
14
11417
4
15990
13
16
6330
17
12884
18
5685
15
19
7837
8838
21
12366
22
207
23
9346
20
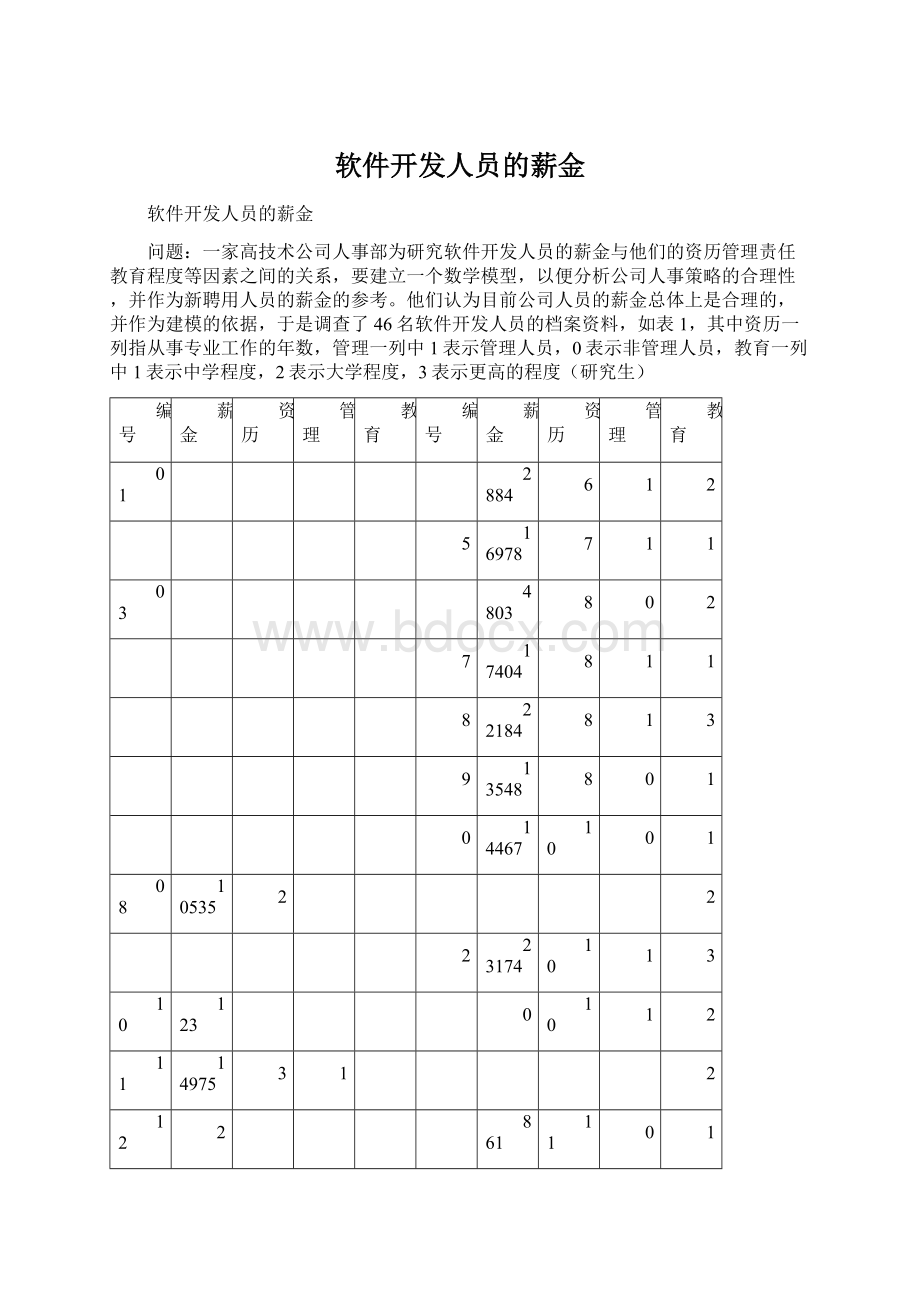
表1软件开发人员的薪金与他们的资历、管理责任、教育程度
分析与假设:
按照常识,薪金自然随着资历(年)的增长而增加,
管理人员的薪金应高于非管理人员,教育程度越高薪金也越高。
薪金记作y,资历(年)记作x1,为了表示是否管理人员,定义
为了表示三种教育程度,定义
这样,中学用x3=1,x4=0表示,大学用x3=0,x4=1表示,研究生则用x3=0,x4=0表示。
则表一的数据应变化为:
y
x1
x2
x3
x4
25
27
28
29
31
15942
32
4861
36
38
26330
25685
27837
18838
9207
19346
表2变换后软件开发人员的薪金与他们的资历、管理责任、教育程度
为了简单起见,我们假定资历(年)对薪金的作用是线性的,即资历每增加一年,薪金的增长是常数;
管理责任、教育程度、资历诸因素之间没有交互作用,建立线性回归模型。
基本模型:
薪金y与资历x1,管理责任x2,教育程度x3,x4之间的多元线性回归模型为
(1)
其中
是待估计的回归系数,
是随即误差。
利用SAS编程可以得到回归系数及置信区间(置信水平为0.05)检验统计量
,F,p的结果,见表3
参数
参数估计值
p值
a0
11033
<
.0001
a1
546
a2
6883
a3
-2994
a4
148
0.7053
R*R=0.957F=226p=0
表3模型
(1)的计算结果
结果分析:
从表3,
=0.957,即因变量(薪金)的95.7%可由模型确定,F值远远超过F检验的临界值,p远小于
,因而模型
(1)从整体来看是可用的。
比如,利用模型可以估计(或预测)一个大学毕业、有2年资历、非管理人员的薪金为
模型中各个回归系数的含义可初步解释如下:
x1的系数为546,说明资历每增加1年,薪金增长546;
x2的系数为6883,说明管理人员的薪金比非管理人员的多6883;
x3的系数为-2994,说明中学程度的薪金比研究生少2994;
x4的系数为148,说明大学程度的薪金比研究生多148,但是应注意到
对应的p值为0.7053,远大于0.05,所以这个系数的解释是不可靠的。
需要指出,以上解释是就平均值来说,并且,一个因素改变引起的因变量的变化量,都是在其它因素不变的条件下才成立的。
进一步的讨论:
对应的p值远大于0.05,说明模型
(1)存在缺点。
为寻找改进的方向,常用残差分析方法(残差
指薪金的实际值y与用模型估计的薪金
之差,是模型
(1)中随机误差
的估计值,这里用了同一个符号)。
我们将因影响因素分成资历与管理—教育组合两类,管理—教育组合的定义如表4。
组合
表4管理—教育组合
为了对残差进行分析,图1给出了管理—教育组合
与资历x1的关系,图2给出了
与管理x2—教育x3,x4组合间的关系。
图1模型
(1)
与x1的关系
图2模型
(1)
与x2—x3,x4组合间的关系
从图1看,残差大概分成三种水平,这是由于6种管理—教育组合混在一起,在模型中未被正确反映的结果;
从图2看,对于前4个管理—教育组合,残差或者全为正,或者全为负,也表明管理—教育组合在模型中处理不当。
在模型
(1)中管理责任和教育程度是分别起作用的,事实上,二者可能起着交互作用,如大学程度的管理人员的薪金会比二者分别的薪金之和高一点。
以上分析提示我们,应在基本模型
(1)中增加管理x2与教育x3,x4的交互项,建立新的回归模型。
更好的模型增加x2与x3,x4的交互项后,模型记作
(2)
利用SAS得到以下结果如表5。
11204
497
7048
-1727
-348
0.0009
a5
-3071
a6
1836
R*R=0.9988F=5544.8p<
表5模型
(2)的计算结果
由表5可知,模型
(2)的
和F值都比模型
(1)有所改进,并且所有回归系数的p值都小于置信水平0.05,表明模型是完全可用的。
与模型
(1)类似,作模型
(2)的两个残差分析图(图3,图4),可以看出,已经消除了图1、图2中的不正常现象,这也说明了模型
(2)的适用性。
图3模型
(2)
图4模型
(2)
从图3、图4还可以发现一个异常点:
具有10年资历、大学程度的管理人员(从表1可以查出是33号),他的实际薪金明显低于模型的估计值,也明显低于与他有类似经历的其他人的薪金。
这可能是由于我们未知的原因造成的。
为了使个别的数据不致影响整个模型,应该将这个异常值去掉,对模型
(2)重新估计回归系数,得到的结果如表6,残差分析见图5,图6。
可以看出,去掉异常数据后结果又有改善。
11200
498
7041
-1737
-356
-3056
1997
R*R=0.9998F=36701p=0
表6模型
(2)去掉异常数据后的回归系数
图5模型
(2)去掉异常数据后的
图6模型
(2)去掉异常数据后的
模型应用对于回归模型
(2),用去掉异常数据(33号)后估计出的系数,得到的结果是满意的。
作为这个模型的应用之一,不妨用它来“制订”6种管理—教育组合人员的“基础”薪金(即资历为零的薪金,当然,这也是平均意义上的)。
利用模型
(2)和表6容易得到表7。
系数
"
基础"
a0+a3
9463
a0+a2+a3+a5
13448
a0+a4
10844
a0+a2+a4+a6
19882
a0+a2
18241
表76种管理—教育组合人员的“基础”薪金
可以看出,大学程度的管理人员的薪金比研究生程度的管理人员的薪金高,而大学程度的非管理人员的薪金比研究生程度的非管理人员的薪金略低。
当然,这是根据这家公司实际数据建立的模型得到的结果,并不具普遍性。
评注:
从建立回归模型的角度我们通过本例介绍了以下内容:
(1)对于影响因变量的定性因素(管理、教育),可以引入0—1变量来处理,0—1变量的个数可比定性因素的水平少(如教育程度有3个水平,引入2个0—1变量)。
(2)用残差分析方法可以发现模型的缺陷,引入交互作用项常常能够给予改善。
(3)若发现异常值应剔除,有助于结果的合理性。
在本例中我们由简到繁,先分别引进管理和教育因素,再进入交互项。
实际上,可以对6种管理—教育组合引入5个0—1变量,由于篇幅原因,这里不作讨论!
附录
输入数据的程序:
datayouya;
inputyx1x2x3x4x5;
cards;
1387611102
1160810005
1870111006
1128310013
1176710005
2087221014
1177220013
1053520101
1219520005
1231330013
1497531102
2137131014
1980031006
1141740101
2026341006
1323140005
1288440013
1324550013
1367750005
1596551102
1236660101
2135261006
1383960013
2288461014
1697871102
1480380013
1740481102
2218481006
1354880101
14467100101
15942100013
23174101006
23780101014
25410111014
14861110101
16882120013
24170121006
15990130101
26330131014
17949140013
25685151006
27837161014
18838160013
17483160101
19207170013
19346200101
run;
procprintdata=youya;
模型
(1)的程序:
procregdata=youya;
varyx1-x5;
modely=x1-x4;
plotresidual.*x1;
plotresidual.*x5;
模型
(2)的程序:
datayouya;
setyouya;
x2x3=x2*x3;
x2x4=x2*x4;
varyx1x2x3x4x5x2x3x2x4;
modely=x1x2x3x4x2x3x2x4;
模型
(2)去掉异常数据的程序:
setyouya(dropobs=33);
模型
(1)的运行结果
TheREGProcedure
AnalysisofVariance
SumofMean
SourceDFSquaresSquareFValuePr>
F
Model4957459467239364867226.43<
Error41
CorrectedTotal451000802406
RootMSE1028.17549R-Square0.9567
DependentMean17271AdjR-Sq0.9525
CoeffVar5.95324
ParameterEstimates
ParameterStandard
VariableDFEstimateErrortValuePr>
|t|
Intercept111033383.4924828.77<
x11546.1276530.5411217.88<
x216882.53292314.1445421.91<
x31-2994.17834412.04857-7.27<
x41147.73798387.937860.380.7053
模型
(2)的运行结果
SumofMean
SourceDFSquaresSquareFValuePr>
Model69996305691666050955544.80<
Error3930047
RootMSE173.34097R-Square0.9988
DependentMean17271AdjR-Sq0.9986
CoeffVar1.00366
Intercept11120478.85272142.08<
x11496.863935.5514489.50<
x217047.99973102.3131868.89<
x31-1726.50419105.05048-16.43<
x41-348.3925497.30539-3.580.0009
x2x31-3070.59619148.92867-20.62<
x2x411835.96764130.8144514.03<
模型
(2)去掉异常数据的运行结果
Model695732660915955443536701.3<
Error381652004347.37507
CorrectedTotal44957491809
RootMSE65.93463R-Square0.9998
DependentMean17126AdjR-Sq0.9998
CoeffVar0.38499
Intercept11120029.99462373.40<
x11498.294452.11372235.74<
x217041.1690238.91999180.91<
x31-1737.0900139.96467-43.47<
x41-356.3557537.01627-9.63<
x2x31-3056.3267956.65655-53.94<
x2x411996.9828350.8712539.26<
 升级会员
升级会员 