BP算法程序实现Word文档格式.docx
《BP算法程序实现Word文档格式.docx》由会员分享,可在线阅读,更多相关《BP算法程序实现Word文档格式.docx(18页珍藏版)》请在冰豆网上搜索。
式中y“yoyy…yj…ym]T,护°
…打…、:
io]T
对于隐层
V=[3yXI
式中X“XoXg…Xj…Xn]T,沪二[C…打…-第]T
看出,BP算法中,各层权值调整公式形式上都是一样的,均由3个因素决定,学习率n,本层输出的误差信号3及本层输入信号丫(或X)。
其中输出层误差信号同网络的期望输出与实际输出之差有关,直接反映了输出误差,而各隐层的误差信号与前面各层的误差信号都有关,是从输出层开始逐层反传过来的。
反传过程可以简述为:
d与o比较得到输出层误差信号3°
—计算输出层权值调整量厶W3°
通过隐层各节点反传一计算各隐层权值的调整量厶V.
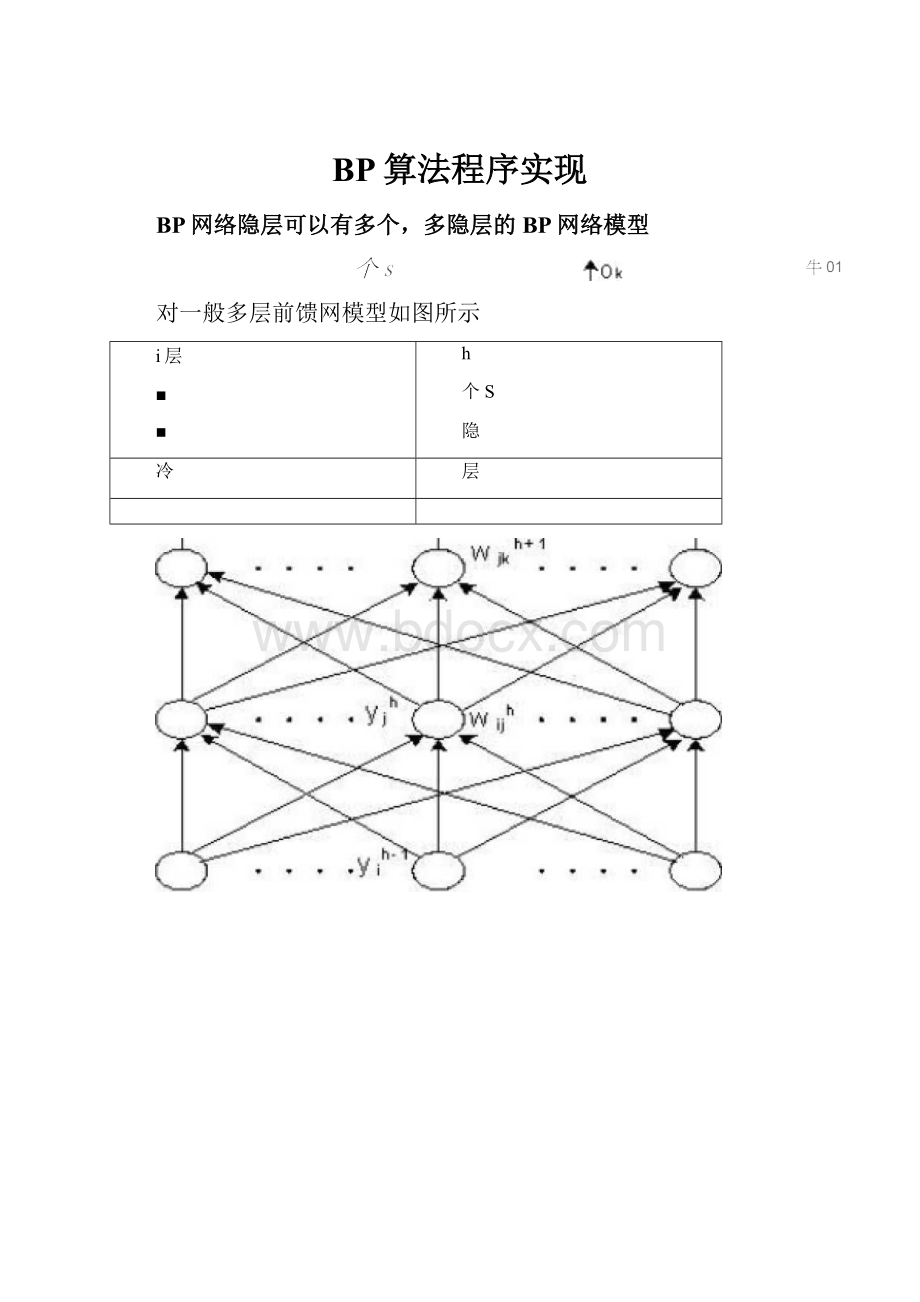
例采用BP网络映射下图曲线规律。
1
09
-/\
03
/\
07
V\
r
0.6
>
0.5
7
0.4
\
\\
/
/彳
-\
/-
02
—X
01
n
1II111\ii
///,
00.51I522533.5
设计BP网络结构如下:
单隐层1—4—1BP网络
权系数随机选取为:
W2=0.2,wi3=0.3,wi4=0.4,w15=0.5,
w26=0.5,W36=0.2,W46=0.1,W56=0.4o
取学习率n=1
按图中曲线确定学习样本数据如下表(每0.05取一学习数据,共80对)
x(输入信号)
y(教师信号)
••-
0.0000
0.5000
3.0000
•…
1.0000
4.0000
按表中数据开始进行学习:
第一次学习,输入x1=0.0000(1节点第1次学习),d;
=0.5000,计算2、3、4、5单
元状态netj:
net^w^xl=w1i*0.0000=0.0000i=2,3,4,5
计算2、3、4、5各隐层单元输出yi(i=2,3,4,5)
y1-f(netj=1心e』eti)=0.5
计算输出层单元6的状态值net;
及输出值y;
■0.51
net6二W;
TYi二0.50.20.1
10.5
0.4」=—0.6
0.5
y6-1/(1e"
t6)=1/(1e^6)=0.6457
反推确定第二层权系数变化:
酩=y1(d6—y1)(1—y6)=0.6457(0.5—0.6457)(1—0.6457)=-0.0333
Wi^w^「的1i=2,3,4,5
第一次反传修正的输出层权为:
0.50.50.4833
0.2
+1*(-0.0333)
0.1833
0.1
0.0833
0.4.
11
一0.5一
0.3833一
反推第一层权系数修正:
&
二色脑側“1-y;
)i=2,3,4,5
W1i=w°
■^1x1
Wi二0.20.30.40.5T
第二次学习,x2=0.0500,0.5250
2
neti二⑷和治i=2,3,4,5
£
=1/[1飞如2*)]=1/[1e40'
20.0500)]=0.5025
住=1/[1飞汕13小]=1/[1e40-30.0500)]=0.5037
y=1/[1e”.40.0500)]=0.5050
y=0.5062
计算6单元状态net6:
"
0.5025_
t匸t0.5037
net6=W6tY=0.48330.18330.08330.3833】=0.5713
0.5050
.0.5062一
代二f(net6)=1/(1e^5713)=0.6390
按表中数据依次训练学习,学习次数足够高时,可能达到学习目的,实现
权值成熟。
一般网络学习训练次数很高,采用手工计算是不可能的,需要用计算机程序求解。
BP算法的编程步骤:
图3.2三层BP网络结构
343BP算法的程序实现
前面推导的BP网络算法是BP算法基础,称标准BP算法。
目前神经网络的实现仍以软件
编程为主。
现以如图的三层BP网络为例,说明标准
O二[。
1。
2…Ok…0『输出层输出向量;
V珂V$2…Vj…Vm]――输入层到隐层间的权值矩阵;
Vj――隐层第j个神经元对应的权列向量;
W二[W1W2…Wk…W1]——隐层到输出层间的权值矩阵;
Wk——输出层第k个神经元对应的权列向量;
d=©
d2…dk…dJT――网络期望输出向量。
标准BP算法的程序实现
网络止向传播阶段
计算谋差
初始化V.W
计数器q=1^=1
误差反向传播阶段
计算各层误差信号
琨=-0*)(1-=1,2’…昇
I
V=(工弗少)(1-.=1z
调粮各层权值:
E户=J岸(或F
(以木节三层BP网络为例)
N
Y
结束
E=0,/>
=I
mF+祸昭=…
x=0,1,,it
增
耳―学习率,0〜1小数;
E-误差变量”初值取0;
对向瞳数组X、订賦伉,计算Y、Q申各分血
计算网络输出误差,设有P对训练样本,网络对应不同样本的误差酊
让算各层误差信号
炭=(dk一s)(l—ok)ok=1*2*…昇
i
晡二(A员)(1-yt)yiJ=1…,加
k-1
检查是否对所仔样本一次轮训
检查网络总误差是否达到精度
总误差E可取E?
中最大者,或小的均方根£
邸圧
•目前实际应用屮有两种权值调整方法。
上述标准BP算法屮,每输入一个样本,都要回传误差并调整权值,亦称单样木训练,只针对每个样本产生的误差进行调整,难免顾此失彼,实践表明,使整个训练次数增加,导致收敛速度过慢。
•另…种方法是在所有样本输入后,计算网络的总误差忙总:
Ipj…
E萨詔耳歼
然后根据总误差E单计算各层的误差信号并调整权值,这种累积误差的批处理方式称%批(b"
di)训练或周期(epoch)ifll练。
批训练遵循了以减小全局误差为目标的原则,因而可以保证误差向减小方向变化.在样木数较多时,批训练比单样本训练时的收
敛速度快。
EP—不同样本的训练误差(共有F对样本)
检查训练精度可用E=E总,也可用Erme:
批训练BPM法流程
计算全部训练样本对的网络的总误差
用E计算各层误差信号
调整各层权值
E<
Emm
所有样本对输入后,用网络的总误差调整权值,记作一次权训练。
——训练次数
程序可用一般咼级语言编写,如C等,但考虑方便,最好米用MATLA
E语言,特别是MATLAE环境中开发了工具箱(Toolboxes),其中神经网络开发工具(NeuralNetwork)提供很丰富的手段来完成EP等ANN设计与分析。
NeuralNetwork中提供了网络初始化函数用语构建基本网络,可自动生成权值,提供各种转移函数,提供各种训练或学习方法与手段,并实现仿真运算,监视网络训练误差等。
BP网络的训练,可概括归纳为输入已知数据,权值初始化,训练网络三大步。
用神经网络工具箱训练BP网络,权值初始化和训练网络都可调用BP网络
的相应工具函数。
调用时,用户只需要将这些工具函数视为黑箱,知道输入什么得到什么即可,不必考虑工具函数内部究竟如何。
EP网络的一些重要函数和功能(与版本有关)如表3.1o
表3.1BP网络的一些函数及功能
函数
功能
newff
创建一前馈EP网络(网络初始化函数)
Initff
前馈网络初始化(不超3层初始化函数)
purelin
线性传递(转移)函数
tansig
正切S型传递函数(双极性S函数)
logsig
对数正切S型传递函数(单极性S函数)
deltalin
purelin神经元的S函数
deltatan
tansig神经元的S函数
deltalog
logsig神经元的S函数
trainbp
EP算法训练函数(标准)
trainbpx
快速EP算法训练函数
trainlm
Levenberg-Marquardt训练函数
traingd
梯度下降训练函数
traingdm
梯度下降、动量训练函数
traingda
梯度下降、自适应学习率训练函数
traingdx
梯度下降、动量和自适应学习训练函数
simuff
前馈网络仿真函数(网络计算和测试网络)
errsurf
计算误差曲面函数
plotes
绘制误差曲面函数
ploterr
绘制网络误差相对训练步曲线
现行MATLAE工具中,神经元及网络模型表达略有差别
基本神经元模型:
厂个输入矢量%=4(1儿x权值矢量Wj
=OV(j,D,WO,2),■»
评(nCh偏置量右”则该神经元净输入为巧=闪严*十勾,输岀卩=/(町)。
a)j/=purelin(5)
b)=logsigG)
c)=tansig(s)
传递函数(转移函数):
344多层前馈网络的主要能力
多层前馈网络是目前应用最多的神经网络,这主要归结于基于BP算法的
多层前馈网络具有一些重要能力:
(1)非线性映射能力
(2)泛化能力
(3)容错能力
3.4.5误差曲面与BP算法的局限性
误差曲面与BP算法的局限性
多层前馈网络的误差是各层权值和输入样木对的函数:
F=F(Xp,W,V,dp)
特别是权空间的维数较高,误差E是一个高维极其复杂的曲面--称误差曲面。
它有三个特点:
(1)
\a
V
vV/
11
;
一维权空间误差曲面
存在平坦区域
(2)全局极小点不唯一
(3)存在多个局部极小点
Erro『Contour
ErrorSurface
WeightW
BiasB
』OILNpa)3bsE3
25
15
05
-1
-1.5
!
nil/nrjiHilliiiiiumii■■购'
imil
.V////
I/1ISV///////z7
//〃[//"
〃////////
Hi;
////i"
川仃遛口[I丿/」■l!
l[I\J
I/〃山i///ZitiWUr\iW/MW
IIIIHH
1I
iiW\ilnlwxii
zz
\\w選
lIIK1\
WWW1
n\\\w
['
WWW
IIWWW
W\\!
\\W\\\
I110IIH^I■IA\\\
J'
11、\\\\・\\\\\I「\^\\\\\M\W\
-0500.5
在某些初始值的条件下,算法的结果会陷入局部极小点,而不能自拔,使训练无法收敛于给定误差。
有采用遗传算法来求全局极小点。
误差曲面的多极值点的特点,使算法(以误差梯度降为权值调整依据)无法辨认极小点性质:
误差曲面的平坦区使训练次数大大增加,影响收敛速度。
这两个问题是BP算法的固有缺陷。
称BP算法的局限性。
其根源在于其误差梯度降的权值调整原则,每一步2求解都取局部绘优口因为训练最终进入局部极小还是全局极小与网络权值的初态仃关,而初始权值是随机确定的。
故较复杂的多层前馈网,标准BP算法的收敛性星无法预知的。
3.5标准BP算法的改进
标准BP算法在应用中暴露出一些缺陷:
(1)易形成局部极小而得不到全局最优;
(2)训练次数多,学习效率低,收敛速度慢;
(3)隐节点选取缺乏理论指导;
(4)训练时学习新样本有遗忘旧样本的趋势。
针对上述问题,国内外已提出一些有效的改进算法。
3.5.1增加动量项(惯性调整算法)
△W(t)=n8X+aAW(t-1)
a-动量系数,取(0,1)。
大都0.9左右
E,若Ef,则
3.5.2自适应调整学习率
设一初始学习率,训练一批次权值调整后,看总误差
n=Bn1
若EJ
则
n=©
n©
实现合理步长调整
3.5.3引入陡度因子
入一一陡度因子
net/■
1e
采用压缩激活函数来改变误差函数,从而改变误差曲面的效果
1e_net
欢迎您的下载,
资料仅供参考!
致力为企业和个人提供合同协议,策划案计划书,学习资料等等
打造全网一站式需求
 升级会员
升级会员 