程序性能调优Word文档格式.docx
《程序性能调优Word文档格式.docx》由会员分享,可在线阅读,更多相关《程序性能调优Word文档格式.docx(22页珍藏版)》请在冰豆网上搜索。
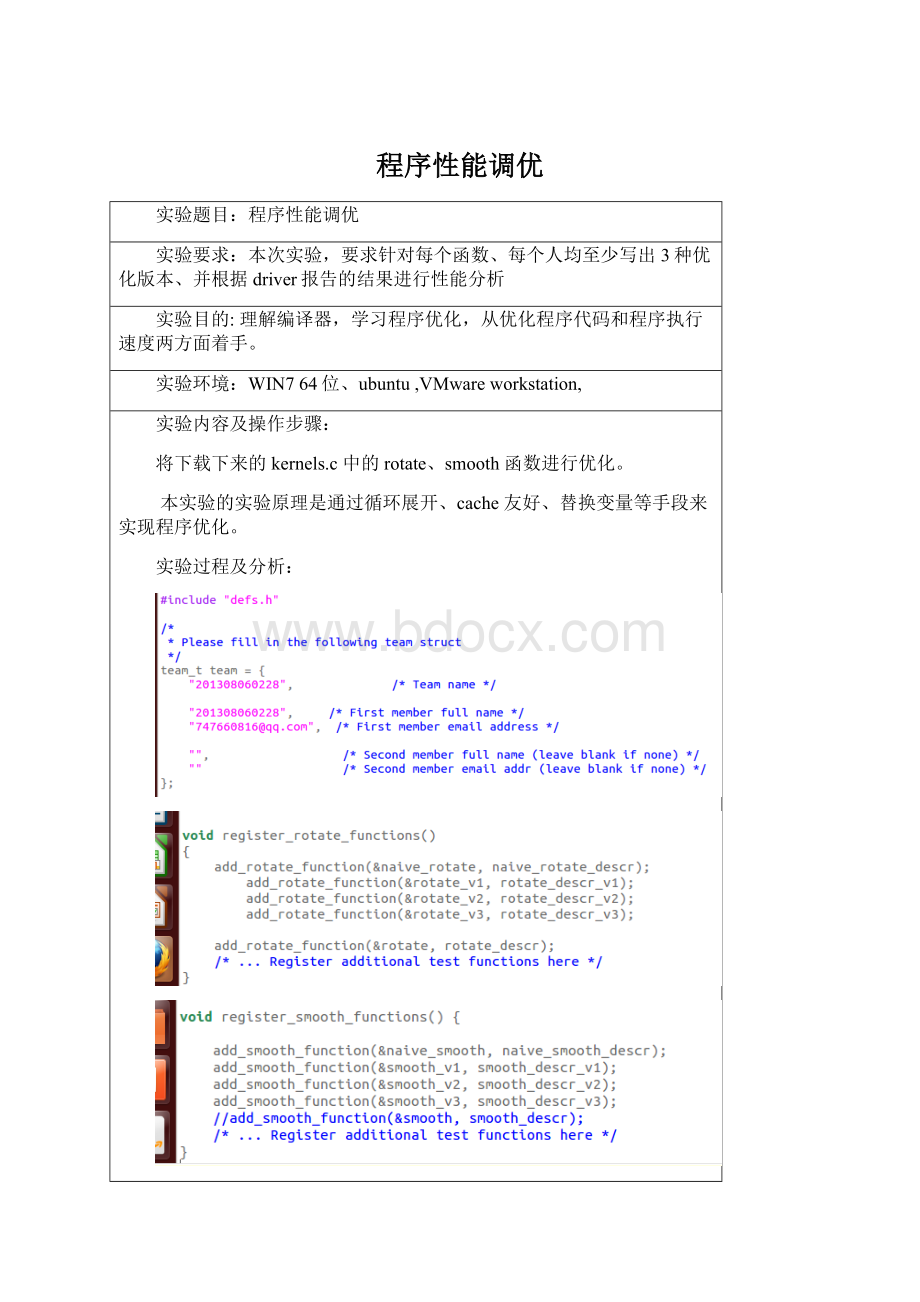
i++)
for(j=0;
j<
j++)
dst[RIDX(dim-1-j,i,dim)]=src[RIDX(i,j,dim)];
}
2)分析:
这段代码的作用就是将所有的像素进行行列调位、导致整幅图画进行了90度旋转。
P从defs.h中可以找到#defineRIDX(i,j,n)((i)*(n)+(j))。
这段代码本来很短,但是从cache友好性来分析,这个代码的效率机会很低,所以按照cache的大小,应在存储的时候进行32个像素依次存储(列存储)。
做到cache友好这样就可以可以大幅度提高效率。
#include<
stdio.h>
stdlib.h>
#include"
defs.h"
team_tteam={
"
201308060228"
/*队名*/
/*序号*/
747660816@"
/*邮箱*/
"
/*Secondmemberfullname(leaveblankifnone)*/
/*Secondmemberemailaddr(leaveblankifnone)*/
};
/*
*naive_rotate-Thenaivebaselineversionofrotate
*/
inti,j;
*rotate-Yourcurrentworkingversionofrotate
*IMPORTANT:
Thisistheversionyouwillbegradedon
charrotate_descr[]="
rotate:
Currentworkingversion,usingpointerratherthancomputingaddress"
voidrotate(intdim,pixel*src,pixel*dst)
inti;
intj;
inttmp1=dim*dim;
inttmp2=dim*31;
inttmp3=tmp1-dim;
inttmp4=tmp1+32;
inttmp5=dim+31;
dst+=tmp3;
for(i=0;
i<
i+=32)
{
for(j=0;
j<
dim;
j++)
*dst=*src;
dst++;
src+=dim;
src++;
src-=tmp2;
dst-=tmp5;
}
src+=tmp2;
dst+=tmp4;
}
}
/*********************************************************************
*register_rotate_functions-Registerallofyourdifferentversions
*oftherotatekernelwiththedriverbycallingthe
*add_rotate_function()foreachtestfunction.Whenyourunthe
*driverprogram,itwilltestandreporttheperformanceofeach
*registeredtestfunction.
*********************************************************************/
charrotate_descr_v1[]="
rotate_v1:
version1breakinto4*4blocks"
voidrotate_v1(intdim,pixel*src,pixel*dst)
inti,j,ii,jj;
for(ii=0;
ii<
ii+=4)
for(jj=0;
jj<
jj+=4)
for(i=ii;
ii+4;
for(j=jj;
jj+4;
dst[RIDX(dim-1-j,i,dim)]=src[RIDX(i,j,dim)];
charrotate_descr_v2[]="
rotate_v2:
version2breakinto32*32blocks"
voidrotate_v2(intdim,pixel*src,pixel*dst)
ii+=32)
jj+=32)
ii+32;
jj+32;
charrotate_descr_v3[]="
rotate_v3:
version3breakinto4*1blockswith4parallelpaths"
voidrotate_v3(intdim,pixel*src,pixel*dst)
inttmp=(dim-1)*dim;
pixel*src_op;
pixel*dst_op;
i+=4)
pixel*src_op_cpy=src+i*dim;
pixel*dst_op_cpy=dst+tmp+i;
src_op=src_op_cpy;
dst_op=dst_op_cpy;
j++)
*dst_op=*src_op;
dst_op++;
src_op+=dim;
src_op_cpy++;
dst_op_cpy-=dim;
2.Naive_smooth
1)原代码
charnaive_smooth_descr[]="
naive_smooth:
voidnaive_smooth(intdim,pixel*src,pixel*dst)
dst[RIDX(i,j,dim)]=avg(dim,i,j,src);
2)分析
这段代码很多次地调用avg函数,而avg函数内也频繁调用initialize_pixel_sum、accumulate_sum、assign_sum_to_pixel这几个函数,且含有2层for循环。
虽然会以损害程序的模块性为代价,但消除函数调用的时间开销,得到的代码运行速度会快得多。
所以,需要改写代码,不调用avg函数。
Smooth函数处理分为以下3部分,
一.主体内部,由9点求平均值;
二.4个角,由4点求平均值;
三.4条边界,由6点求平均值。
由图片的顶部开始处理,再上边界,顺序处理下来,其中在处理左边界时,for循环处理一行主体部分
3)优化代码
charsmooth_descr_v1[]="
smooth_v1:
withlessfunccallandgrosslysimplifiedcalculationforcentralparts"
voidsmooth_v1(intdim,pixel*src,pixel*dst)
{
inti,j,ii,jj;
pixel_sumsum;
pixelcurrent_pixel,cp;
{
dst[RIDX(0,j,dim)]=avg(dim,0,j,src);
dst[RIDX(dim-1,j,dim)]=avg(dim,dim-1,j,src);
dst[RIDX(i,0,dim)]=avg(dim,i,0,src);
dst[RIDX(i,dim-1,dim)]=avg(dim,i,dim-1,src);
for(i=1;
dim-1;
for(j=1;
sum.red=sum.green=sum.blue=0;
for(ii=max(i-1,0);
=min(i+1,dim-1);
ii++)
for(jj=max(j-1,0);
=min(j+1,dim-1);
jj++)
cp=src[RIDX(ii,jj,dim)];
sum.red+=cp.red;
sum.green+=cp.green;
sum.blue+=cp.blue;
current_pixel.red=sum.red/9;
current_pixel.green=sum.green/9;
current_pixel.blue=sum.blue/9;
dst[RIDX(i,j,dim)]=current_pixel;
charsmooth_descr_v2[]="
smooth_v2:
dividesrcinto3partsanduse3pointersforsmoothingcopy"
voidsmooth_v2(intdim,pixel*src,pixel*dst)
inti,j;
pixel*p_s=src;
pixel*p_d=dst;
pixel*p_s_nextRow=src+dim;
pixel*p_s_next2Row=src+dim*2;
//the1strow
//(0,0)pixel
p_d->
red=(p_s->
red+(p_s+1)->
red+(p_s_nextRow)->
red+(p_s_nextRow+1)->
red)>
>
2;
blue=(p_s->
blue+(p_s+1)->
blue+(p_s_nextRow+1)->
blue+(p_s_nextRow)->
blue)>
green=(p_s->
green+(p_s+1)->
green+(p_s_nextRow+1)->
green+(p_s_nextRow)->
green)>
p_d++;
//pixelsfrom(1,1)to(1,dim-2)
dim-1;
red+(p_s+2)->
red+(p_s_nextRow+2)->
red)/6;
blue+(p_s+2)->
blue+(p_s_nextRow+2)->
blue)/6;
green+(p_s+2)->
green+(p_s_nextRow+2)->
green)/6;
p_s++;
p_s_nextRow++;
//pixel(1,dim-1)
//forthenextrow
p_s=src;
p_s_nextRow=src+dim;
//thecentralparts
//1stpixeloftherow(i,0);
red+(p_s_next2Row)->
red+(p_s_next2Row+1)->
blue+(p_s_next2Row)->
blue+(p_s_next2Row+1)->
green+(p_s_next2Row)->
green+(p_s_next2Row+1)->
//centralpixelsfrom(i,1)to(i,dim-2);
red
+(p_s_nextRow+2)->
+(p_s_next2Row)->
red+(p_s_next2Row+2)->
red)/9;
blue
blue+(p_s_next2Row+2)->
blue)/9;
green
green+(p_s_next2Row+2)->
green)/9;
p_s_nextRow++;
p_s_next2Row++;
//row(i,dim-1)结束
p_s+=2;
p_s_nextRow+=2;
p_s_next2Row+=2;
//lastrow
//1stpixelofthelastrow(dim-1,0)
//pixelsfrom(dim-1,1)to(dim-1,dim-2);
green+(
 升级会员
升级会员 