nagios监控说明Word文档下载推荐.docx
《nagios监控说明Word文档下载推荐.docx》由会员分享,可在线阅读,更多相关《nagios监控说明Word文档下载推荐.docx(12页珍藏版)》请在冰豆网上搜索。
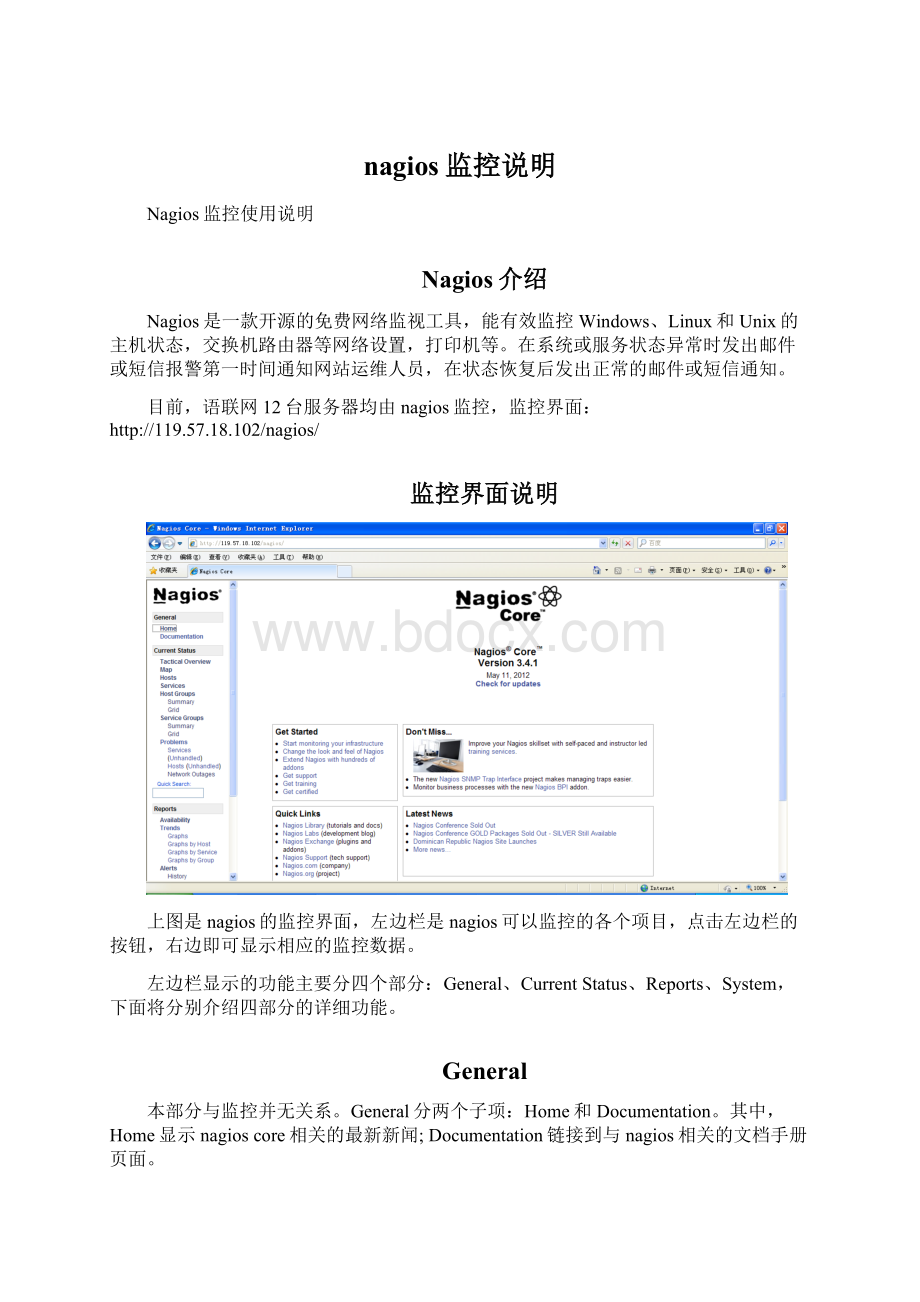
本部分显示监控的详细信息,下面将分别介绍各子项的详细内容。
TacticalOverview
该子项显示nagios所监控的所有主机状态的概况。
右上方_MonitoringPerformance:
上图中检测执行时间的三个值分别表示min/max/avg。
比如
,表示服务检测执行时间最短0.01秒,最长4.11秒,平均0.303秒
左上方_NetworkOutages
下方部分
其中MonitoringFeatures中的Flap有必要解释一下,Flap指被监控服务的状态值在该服务报警的阈值附近徘徊时间较长时的状态。
Map
本部分主要显示监控机与被监控机之间简单的拓朴图,页面中央即显示拓朴图。
另外,解释一下右上方的功能:
1、LayoutMethod
下拉框中有不同的显示方式,选择其中一种,然后点击update,拓朴图的显示方式会有所改变。
2、Scalingfactor
缩放拓朴图的大小
3、DrawingLayers和Layermode
这里我也不知道怎么翻译成中文。
其中DrawingLayers的框中显示的是nagios所监控的两个主机群。
如果选中”LinuxServers”,然后在Layermode中选中Exclude,那么拓朴图将显示所有的windows-servers;
如果选中”LinuxServers”,然后在Layermode中选中include,那么拓朴图将显示所有的Linuxservers。
4、Suppresspopus
该项我也不知道是什么功能,呵呵。
Hosts
不管是host还是service的状态,如果显示绿色表示正常,黄色表示警告,红色表示报警。
下面就监控的各项分别进行解释:
其中主机名的命名,前面的数字是该主机IP的主机位,后面是该主机所承担的角色或任务。
比如:
100_redis_master
,表示该主机的IP的主机位是100,该主机的角色是redis主服务器。
点击主机名右边的按钮
,会显示该主机上的服务。
HostStateInformation
点击该主机名,会显示关于该主机的详细信息:
,如下图如示:
其中,“InScheduledDowntime?
”的精确意义我也不明白;
“PassiveChecks”用于被监控机器特别多时,这样可以减轻监控机的负担。
HostCommands
声明:
本人很少用这部分的功能,可能有些解释不准确,请指正。
这部分是nagios的外部命令,在执行这些命令时,服务器上会调用文件nagios.cmd。
这些命令并没有直接更改nagios的配置文件,但可以实现一些功能,如下图如示:
没有解释的地方表明本人还没完全理解。
HostComments
如上图所示,该部分主要用于不同系统管理员之间的交流或备忘。
管理员A在下班之前作如上备注,管理员B接替时,会看到以上信息,以作相关准备。
Services
Services的页面显示与Hosts基本一样。
下面以一条正监控的service信息来进行说明:
1、服务名:
disk_/,即表示磁盘的根分区
2、Attempt:
不管是主机还是服务监控,默认都是5分钟检测一次,如果出现警告或报警,会在Status显示warning或critical。
如果连续4次检测的状态都是异常,则触发邮件告警
3、StatusInformation
Freespace:
/14GB,即剩余空间14G
78%:
剩余78%的空间
Inode=96%:
此处并不是磁盘空间,指该分区inode的使用情况
另外,对正在监控的各项服务作一下简明解释:
1、disk_/:
磁盘根分区
2、disk_/bak:
磁盘分区/bak
3、disk_boot:
磁盘分区/boot。
……后面的/shm、/site、var都是如此
4、load:
CPU负载信息,三个值分别表示5分钟、10分钟、15分钟内的平均负载
5、mem:
剩余内存的百分比
6、ping:
监控机ping被监控机的情况
7、ssh:
被监控机的ssh运行状态
8、swap:
交换分区
9、total_procs:
总的进程数
10、users:
被监控机上登录的用户数
11、zombie_procs:
僵死进程数
HostGroups
本部分显示nagios所监控的主机组的相关状态信息,现有的主机组按所使用的操作系统(windows和Linux)而分,将来还可以根据需求分成其它组。
本部分主要有三个显示页面:
ServiceOverviewForAllHostGroups、
StatusSummaryForAllHostGroups、StatusGridForAllHostGroups。
只是显示的方式不同而已。
有必要说明一下三个按钮表示的意思:
:
点击该按钮会显示主机详细的状态信息
:
点击该按钮会显示主机的服务状态
点击该按钮会在拓朴图中显示该主机的位置
ServiceGroups
本部分的显示方式与HostGroups的差不多,nagios默认并没有服务组的定义,本人认为定义此组主要的目的还是便于得出不同主机、相同服务的状态对比报告(后面会涉及到此功能)。
目前定义了两个服务组check_disk_data和check_load,分别列出不同主机中磁盘分区/data和CPU的状态信息。
Problem
本部分集中显示异常信息,比如警告、报警等。
QuickSearch
此处按主机名进行搜索。
比如填入”100”,再按回车键,即可显示主机100_redis_master的相关信息,如下图所示:
Reports
本部分功能主要分两部分:
一是,显示nagios运行的相关日志,比如:
错误消息、何时发出报警邮件,这些邮件分别发送给哪些人等;
二是,生成在一定时间内,被监控的主机或服务的运行报告,比如,生成某主机在一周内的运行情况(宕机多长时间,发生异常的频率等)。
Availability
第一步
点击Availability,会显示如下界面:
Type下拉框中有四个选项:
分别针对Hostgroup、Host、Servicegroup、Service生成报告。
这里我就默认的Hostgroup进行演示。
第二步
点击按钮”ContinuetoStep2”,进入下一界面:
在Hostgroup下拉框中,我选择linux-Servers。
第三步
点击按钮”ContinuetoStep3”,进入下一界面:
没有注明的部分,我也不明白其精确的含义,也很少使用。
第四步
点击”CreateAvailabilityReport”,生成报告。
因为以上是最近7天的报告,而nagios只运行了4天,所以还有36%的TimeUndetermined。
Trends
本部分生成报告的过程与Availability相同,但本部分只生成与Host或Service相关的历史数据,并以图形的形式呈现出现。
如下图:
Graphs
Nagios默认是没有点graphs功能的,需要安装插件nagiosgraphs。
该功能是将被监控的各项数据绘在图形上,可以很直观地看出该被监控项在每天、周、月、年的运行变化情况。
上图是一天内监控http的情况。
Alerts
本部分主要是关于报警的日志和报告的生成。
History
显示当天的报警日志。
介绍一下右上方各选项的含义:
主要是对报警日志进行筛选,没有标注的项表明本人也不太明白精确含义。
Summary
对最近一周的报警信息进行汇总,默认只显示前25条,可自行设置。
生成结果如下图:
Histogram
针对主机或服务,生成其最近一周的报警信息的直方图。
生成结果如下图所示:
上图表示该主机重启过2-3次。
Notifications
显示当天触发邮件报警的记录。
EventLog
显示当天nagios运行的所有日志。
System
本部分的功能本人很少应用,经验甚少,所以介绍可能比较模糊或不准确,请原谅。
本部分主要是对nagios系统作全局的配置或注解,或查看nagios系统的各项配置,运用的命令等,只有管理员才能查看这些信息。
Comments
对主机或服务作注释,如下图所示:
其中Comment栏就是用户NagiosAdmin作的注释。
Downtime
Downtime指在设定时间段内,如果被指定的主机或服务出现异常,nagios不发出报警邮件。
因为这种异常是在计划内的、可预知的。
上图中显示的内容表示,在时间段14:
04——16:
04内,主机100_redis_master会关机维护硬件,在此期间,nagios不得发出报警邮件。
ProcessInfo
对nagios作全局的介绍或设置,如全部启用或停用某项功能等。
具体介绍请看下图:
未注明的项,大部分之前都出现过,而且解释过。
PerformanceInformation
本部分显示主机或服务在最近1分钟、5分钟、15分钟、1小时内被检测数的百分比,分主动检测和被动检测两种,因当前应用的是主动检测,所以被动检测的数据为0.
SchedulingQueue
列出计划中需要被检测项的队列,按时间顺序排列。
也可针对每一项进行更改被检测的时间。
如下图所示:
Configuration
可查看每个被监控的主机或服务的详细配置信息。
 升级会员
升级会员 